Hiểu biết sâu sắc về cách bố trí bộ nhớ và sao chép đối tượng của Python
Lời nói đầu
Trong bài viết này, tôi chủ yếu giới thiệu với các bạn vấn đề sao chép trong Python. Không dài dòng nữa, chúng ta hãy xem trực tiếp đoạn mã này. Bạn có biết kết quả đầu ra của các đoạn chương trình sau không?
a = [1, 2, 3, 4] b = a in(f"{a = } \t|\t {b = }") a[0] = 100 in(f"{a = } \t|\t {b = }")
a = [1, 2, 3, 4] b = a.copy() in(f"{a = } \t|\t {b = }") a[0] = 100 in(f"{a = } \t|\t {b = }")
a = [[1, 2, 3], 2, 3, 4] b = a.copy() in(f"{a = } \t|\t {b = }") a[0][0] = 100 in(f"{a = } \t|\t {b = }")
a = [[1, 2, 3], 2, 3, 4] b = sao chép. sao chép(a) in(f"{a = } \t|\t {b = }") a[0][0] = 100 in(f"{a = } \t|\t {b = }")
a = [[1, 2, 3], 2, 3, 4] b = sao chép. deepcopy(a) in(f"{a = } \t|\t {b = }") a[0][0] = 100 in(f"{a = } \t|\t {b = }")
Trong bài viết này chúng tôi sẽ tiến hành phân tích chi tiết về chương trình trên.
Bố cục bộ nhớ của các đối tượng Python
Đầu tiên, hãy giới thiệu một trang web tương đối hữu ích về phân bổ logic dữ liệu trong bộ nhớ, https://pythontutor.com/visualize.html#mode=display.
Chúng tôi chạy mã đầu tiên trên trang web này:
Từ kết quả đầu ra trên, có thể thấy a và b trỏ đến đối tượng dữ liệu trong cùng một bộ nhớ. Vì vậy, đầu ra của mã đầu tiên là như nhau. Chúng ta nên xác định địa chỉ bộ nhớ của một đối tượng như thế nào? Python cung cấp cho chúng ta hàm id() có sẵn để lấy địa chỉ bộ nhớ của một đối tượng:
a = [1, 2, 3, 4] b = a print(f"{a = } \t|\t {b = }") a[0] = 100 print(f"{a = } \t|\t {b = }") print(f"{id(a) = } \t|\t {id(b) = }") # Số lượng phần tử # a = [1, 2, 3, 4] | b = [1, 2, 3, 4] # a = [100, 2, 3, 4] | b = [100, 2, 3, 4] # id(a) = 4393578112 | id(b) = 4393578112
Trên thực tế, bố cục bộ nhớ đối tượng ở trên có vấn đề hoặc nó không đủ chính xác nhưng nó cũng có thể hiển thị mối quan hệ giữa từng đối tượng. Trong Cpython, bạn có thể coi mỗi biến là một con trỏ, trỏ đến dữ liệu được biểu diễn và con trỏ này lưu địa chỉ bộ nhớ của đối tượng Python.
Trong Python, danh sách thực sự lưu trữ các con trỏ tới từng đối tượng Python chứ không phải dữ liệu thực tế. Do đó, đoạn mã nhỏ ở trên có thể được sử dụng để biểu diễn bố cục của các đối tượng trong bộ nhớ như sau:
Biến a trỏ đến danh sách [1, 2, 3, 4] trong bộ nhớ. Có 4 dữ liệu trong danh sách. Bốn dữ liệu này là con trỏ và bốn con trỏ này trỏ đến bốn 1, 2, 3, 4 trong danh sách. bộ nhớ. Bạn có thể có thắc mắc, đây không phải là một vấn đề sao? Vì chúng đều là dữ liệu số nguyên, tại sao không lưu trữ dữ liệu số nguyên trực tiếp trong danh sách? Tại sao chúng ta cần thêm con trỏ để trỏ đến dữ liệu này?
Trên thực tế, trong Python, bất kỳ đối tượng Python nào cũng có thể được lưu trữ trong một danh sách. Ví dụ: chương trình sau là hợp pháp:
dữ liệu = [1, {1:2, 3:4}, {'a', 1, 2, 25.0}, (1, 2, 3), "xin chào thế giới"]
Trong danh sách trên, các kiểu dữ liệu từ dữ liệu đầu tiên đến dữ liệu cuối cùng là: dữ liệu số nguyên, từ điển, tập hợp, bộ dữ liệu, chuỗi. Bây giờ, để hiện thực hóa tính năng này của Python, các đặc tính của con trỏ có đáp ứng được yêu cầu không? Mỗi con trỏ chiếm cùng một bộ nhớ, vì vậy bạn có thể sử dụng một mảng để lưu trữ con trỏ của đối tượng Python, sau đó trỏ con trỏ này tới đối tượng Python thực! .
Kiểm tra thử
Sau phân tích ở trên, chúng ta hãy xem đoạn mã sau và cách bố trí bộ nhớ của nó:
dữ liệu = [[1, 2, 3], 4, 5, 6] dữ liệu_gán = dữ liệu dữ liệu_sao chép = dữ liệu.sao chép()
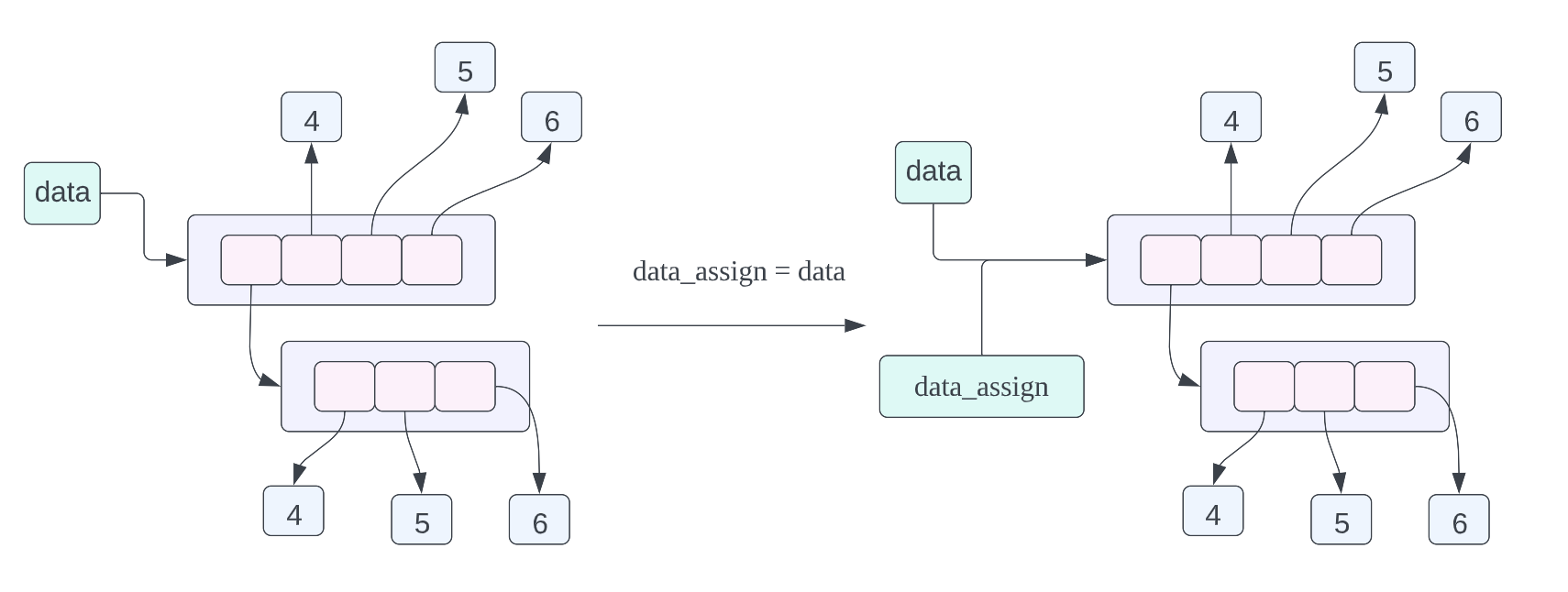

-
data_assign = dữ liệu , trước đây chúng ta đã nói về cách bố trí bộ nhớ của câu lệnh gán này, nhưng chúng ta cũng đang xem xét nó. Ý nghĩa của câu lệnh gán này là dữ liệu được chỉ ra bởi data_signed và data là cùng một dữ liệu, tức là cùng một danh sách.
-
data_copy = data.copy() , ý nghĩa của câu lệnh gán này là tạo một bản sao nông của dữ liệu được dữ liệu trỏ đến, sau đó để data_copy trỏ đến dữ liệu đã sao chép. Bản sao nông ở đây có nghĩa là sao chép từng con trỏ trong danh sách mà không sao chép con trỏ trong danh sách. Dữ liệu được sao chép. Từ sơ đồ bố trí bộ nhớ của đối tượng trên, chúng ta có thể thấy data_copy trỏ đến một danh sách mới, nhưng dữ liệu được con trỏ trỏ đến trong danh sách giống với dữ liệu được con trỏ trỏ đến trong danh sách dữ liệu. được biểu thị bằng mũi tên màu xanh lá cây, dữ liệu Sử dụng mũi tên màu đen để biểu thị điều này.
Xem địa chỉ bộ nhớ của một đối tượng
Trong bài viết trước, chúng tôi chủ yếu phân tích cách bố trí bộ nhớ của đối tượng. Trong phần này, chúng tôi sử dụng python để cung cấp cho chúng tôi một công cụ rất hiệu quả để xác minh điều này. Trong python, chúng ta có thể sử dụng id() để xem địa chỉ bộ nhớ của một đối tượng. id(a) là xem địa chỉ bộ nhớ của đối tượng được trỏ tới bởi đối tượng a.
- Nhìn vào đầu ra của chương trình sau:
a = [1, 2, 3] b = a print(f"{id(a) = } {id(b) = }") cho i trong phạm vi(len(a)): print(f"{i = } {id(a[i]) = } {id(b[i]) = }")
Theo phân tích trước đây của chúng tôi, a và b trỏ đến cùng một bộ nhớ, có nghĩa là hai biến trỏ đến cùng một đối tượng Python. Do đó, kết quả id đầu ra ở trên giống nhau cho a và b.
id(a) = 4392953984 id(b) = 4392953984 i = 0 id(a[i]) = 4312613104 id(b[i]) = 4312613104 i = 1 id(a[i]) = 4312613136 id(b[i]) = 4312613136 i = 2 id(a[i]) = 4312613168 id(b[i]) = 4312613168
- Hãy xem địa chỉ bộ nhớ của bản sao nông:
a = [[1, 2, 3], 4, 5] b = a.copy() print(f"{id(a) = } {id(b) = }") đối với i trong phạm vi(len(a)): print(f"{i = } {id(a[i]) = } {id(b[i]) = }")
Theo phân tích trước đây của chúng tôi, việc gọi chính phương thức sao chép của danh sách là bản sao nông của danh sách. Nó chỉ sao chép dữ liệu con trỏ của danh sách và không sao chép dữ liệu thực được con trỏ trỏ đến trong danh sách. Ta duyệt dữ liệu trong danh sách, ta nhận được Đối với địa chỉ của đối tượng được trỏ tới, kết quả trả về của danh sách a và danh sách b giống nhau, nhưng điểm khác với ví dụ trước là địa chỉ của các danh sách được trỏ đến bởi a và b khác nhau (vì dữ liệu được sao chép nên bạn có thể tham khảo Kết quả của bản sao nông được giải thích bên dưới).
Có thể hiểu nó bằng cách kết hợp các kết quả đầu ra sau với văn bản trên:
id(a) = 4392953984 id(b) = 4393050112 # Kết quả đầu ra của hai đối tượng không bằng nhau i = 0 id(a[i]) = 4393045632 id(b[i]) = 4393045632 # Trỏ tới cùng một bộ nhớ đối tượng Do đó, nếu địa chỉ bộ nhớ bằng nhau thì nó giống như i = 1 id(a[i]) = 4312613200 id(b[i]) = 4312613200 i = 2 id(a[i]) = 4312613232 id(b[i]) = 4312613232
mô-đun sao chép
Có một gói sao chép tích hợp trong python, chủ yếu được sử dụng để sao chép các đối tượng. Có hai phương thức chính trong mô-đun này, copy.copy(x) và copy.deepcopy().
-
Phương thức copy.copy(x) chủ yếu được sử dụng để sao chép nông. Ý nghĩa của phương thức này đối với danh sách cũng giống như phương thức x.copy() của chính danh sách đó, là một bản sao nông. Phương thức này sẽ xây dựng một đối tượng python mới và sao chép tất cả các tham chiếu dữ liệu (con trỏ) trong đối tượng x.
-
copy.deepcopy(x) Phương thức này chủ yếu thực hiện deep copy của đối tượng x. Ý nghĩa của deep copy ở đây là nó sẽ xây dựng một đối tượng mới và xem đệ quy từng đối tượng trong đối tượng x. Nếu đối tượng được xem đệ quy là Immutable object sẽ không. được sao chép. Nếu đối tượng được xem là đối tượng có thể thay đổi, không gian bộ nhớ sẽ được mở lại và dữ liệu gốc trong đối tượng x sẽ được sao chép sang bộ nhớ mới. (Chúng ta sẽ phân tích chi tiết các đối tượng có thể thay đổi và không thể thay đổi ở phần tiếp theo).
-
Dựa vào những phân tích trên, chúng ta có thể biết deep copy có giá thành cao hơn so với deep copy, đặc biệt khi có nhiều subobject trong một đối tượng sẽ tốn rất nhiều thời gian và dung lượng bộ nhớ.
-
Đối với các đối tượng python, sự khác biệt giữa bản sao sâu và bản sao nông chủ yếu nằm ở các đối tượng tổng hợp (các đối tượng có đối tượng con, chẳng hạn như danh sách, tổ tiên, thể hiện của lớp, v.v.). Điểm này chủ yếu liên quan đến các đối tượng có thể thay đổi và bất biến trong phần tiếp theo.
Các đối tượng và bản sao đối tượng có thể thay đổi và bất biến
Có hai loại đối tượng chính trong python, đối tượng có thể thay đổi và đối tượng bất biến. Cái gọi là đối tượng có thể thay đổi có nghĩa là nội dung của đối tượng có thể thay đổi và đối tượng bất biến có nghĩa là nội dung của đối tượng không thể thay đổi.
- Các đối tượng có thể thay đổi: chẳng hạn như danh sách, ký tự, bộ, bytearray và đối tượng thể hiện của các lớp.
- Các đối tượng bất biến: số nguyên, float, phức tạp, chuỗi, tuple, Frozenset, byte.
Bạn có thể có câu hỏi sau khi xem phần này. Số nguyên và chuỗi không thể sửa đổi được?
a = 10 a = 100 a = "xin chào" a = "thế giới"
Ví dụ: đoạn mã sau là chính xác và không có lỗi xảy ra, nhưng trên thực tế, đối tượng được trỏ đến bởi a đã thay đổi. Khi đối tượng đầu tiên trỏ đến một số nguyên hoặc chuỗi, nếu một số nguyên mới và khác được gán lại, Hoặc đối tượng chuỗi, python sẽ tạo một đối tượng mới, chúng ta có thể sử dụng đoạn mã sau để xác minh:
a = 10 in(f"{id(a) = }") a = 100 in(f"{id(a) = }") a = "xin chào" in(f"{id(a) = }") a = "thế giới" in(f"{id(a) = }")
Đầu ra của chương trình trên như sau:
id(a) = 4365566480 id(a) = 4365569360 id(a) = 4424109232 id(a) = 4616350128
Những gì bạn có thể thấy là đối tượng bộ nhớ được chỉ định bởi biến sẽ thay đổi sau khi gán lại (vì địa chỉ bộ nhớ thay đổi). Mặc dù biến có thể được gán lại nhưng những gì bạn nhận được không phải là một đối tượng mới. trên đối tượng ban đầu! .
Bây giờ chúng ta hãy xem địa chỉ bộ nhớ thay đổi như thế nào sau khi danh sách đối tượng có thể thay đổi được sửa đổi:
dữ liệu = [] in(f"{id(dữ liệu) = }") dữ liệu.thêm vào(1) in(f"{id(dữ liệu) = }") dữ liệu.thêm vào(1) in(f"{id(dữ liệu) = }") dữ liệu.thêm vào(1) in(f"{id(dữ liệu) = }") dữ liệu.thêm vào(1) in(f"{id(dữ liệu) = }")
Đầu ra của đoạn mã trên như sau:
id(dữ liệu) = 4614905664 id(dữ liệu) = 4614905664 id(dữ liệu) = 4614905664 id(dữ liệu) = 4614905664 id(dữ liệu) = 4614905664 id(dữ liệu) = 4614905664
Từ kết quả đầu ra ở trên, chúng ta có thể biết rằng khi chúng ta thêm dữ liệu mới vào danh sách (sửa đổi danh sách), bản thân địa chỉ của danh sách không thay đổi.
Chúng ta đã nói về bản sao sâu và bản sao nông trước đó, bây giờ hãy phân tích đoạn mã sau:
dữ liệu = [1, 2, 3] sao chép dữ liệu = sao chép. sao chép(dữ liệu) dữ liệu sâu = sao chép. sao chép sâu(dữ liệu) in(f"{id(dữ liệu) = } | {id(dữ liệu_sao chép) = } | {id(dữ liệu_sâu) = }") in(f"{id(dữ liệu[0]) = } | {id(dữ liệu_sao chép[0]) = } | {id(dữ liệu_sâu[0]) = }") in(f"{id(dữ liệu[1]) = } | {id(dữ liệu_sao chép[1]) = } | {id(dữ liệu_sâu[1]) = }") in(f"{id(dữ liệu[2]) = } | {id(dữ liệu_sao chép[2]) = } | {id(dữ liệu_sâu[2]) = }")
Đầu ra của đoạn mã trên như sau:
id(dữ liệu) = 4620333952 | id(bản sao dữ liệu) = 4619860736 | id(sâu dữ liệu) = 4621137024 id(dữ liệu[0]) = 4365566192 | id(bản sao dữ liệu[0]) = 4365566192 | id(sâu dữ liệu[0]) = 4365566192 id(dữ liệu[1]) = 4365566224 | id(bản sao dữ liệu[1]) = 4365566224 | id(sâu dữ liệu[1]) = 4365566224 id(dữ liệu[2]) = 4365566256 | id(dữ liệu_sâu[2]) = 4365566256
Khi nhìn thấy điều này, chắc chắn bạn sẽ rất bối rối, tại sao đối tượng bộ nhớ được trỏ tới bởi bản sao sâu và bản sao nông lại giống nhau? Chúng ta có thể hiểu tuyến đầu, vì bản sao nông sao chép tham chiếu nên đối tượng chúng trỏ tới giống nhau, nhưng tại sao đối tượng bộ nhớ trỏ đến sau bản sao sâu và bản sao nông cũng giống nhau? Điều này chính xác là do dữ liệu trong danh sách là dữ liệu số nguyên, là một đối tượng bất biến. Nếu đối tượng được trỏ tới bởi data hoặc data_copy bị sửa đổi, nó sẽ trỏ đến một đối tượng mới và sẽ không trực tiếp sửa đổi đối tượng ban đầu. Trên thực tế, các đối tượng bất biến không cần phải mở một không gian bộ nhớ mới và gán lại giá trị, vì các đối tượng trong bộ nhớ này sẽ không thay đổi.
Chúng tôi đang xem xét một đối tượng có thể sao chép:
dữ liệu = [[1], [2], [3]] sao chép dữ liệu = sao chép. sao chép(dữ liệu) dữ liệu sâu = sao chép. sao chép sâu(dữ liệu) in(f"{id(dữ liệu) = } | {id(dữ liệu_sao chép) = } | {id(dữ liệu_sâu) = }") in(f"{id(dữ liệu[0]) = } | {id(dữ liệu_sao chép[0]) = } | {id(dữ liệu_sâu[0]) = }") in(f"{id(dữ liệu[1]) = } | {id(dữ liệu_sao chép[1]) = } | {id(dữ liệu_sâu[1]) = }") in(f"{id(dữ liệu[2]) = } | {id(dữ liệu_sao chép[2]) = } | {id(dữ liệu_sâu[2]) = }")
Đầu ra của đoạn mã trên như sau:
id(dữ liệu) = 4619403712 | id(bản sao dữ liệu) = 4617239424 | id(dữ liệu sâu) = 4620032640 id(dữ liệu[0]) = 4620112640 | id(bản sao dữ liệu[0]) = 4620112640 | id(dữ liệu sâu[0]) = 4620333952 id(dữ liệu[1]) = 4619848128 | id(bản sao dữ liệu[1]) = 4619848128 | id(dữ liệu sâu[1]) = 4621272448 id(dữ liệu[2]) = 4620473280 | id(bản sao dữ liệu[2]) = 4620473280 | id(dữ liệu_sâu[2]) = 4621275840
Từ đầu ra của chương trình trên, chúng ta có thể thấy rằng khi một đối tượng có thể thay đổi được lưu trong danh sách, nếu chúng ta thực hiện sao chép sâu, một đối tượng hoàn toàn mới sẽ được tạo (địa chỉ bộ nhớ của đối tượng sao chép sâu khác với địa chỉ của bản sao nông).
Phân tích đoạn mã
Sau nghiên cứu trên, các câu hỏi được đặt ra ở đầu bài viết này sẽ rất đơn giản đối với bạn ngay bây giờ:
a = [1, 2, 3, 4] b = a in(f"{a = } \t|\t {b = }") a[0] = 100 in(f"{a = } \t|\t {b = }")
Điều này rất đơn giản. Các biến a và b khác nhau trỏ đến cùng một danh sách. Nếu dữ liệu trong a thay đổi thì kết quả đầu ra như sau:
a = [1, 2, 3, 4] | b = [1, 2, 3, 4] a = [100, 2, 3, 4] | b = [100, 2, 3, 4] id(a) = 4614458816 | id(b) = 4614458816
Chúng ta hãy xem đoạn mã thứ hai.
a = [1, 2, 3, 4] b = a.copy() in(f"{a = } \t|\t {b = }") a[0] = 100 in(f"{a = } \t|\t {b = }")
Bởi vì b là bản sao nông của a, a và b trỏ đến các danh sách khác nhau, nhưng dữ liệu trong danh sách lại trỏ đến cùng một điểm. Tuy nhiên, vì dữ liệu số nguyên là dữ liệu bất biến nên khi a[0] thay đổi, dữ liệu gốc sẽ không thay đổi. được sửa đổi nhưng dữ liệu số nguyên mới sẽ được tạo trong bộ nhớ nên nội dung của danh sách b sẽ không thay đổi. Vì vậy, đầu ra của đoạn mã trên trông như thế này:
a = [1, 2, 3, 4] | b = [1, 2, 3, 4] a = [100, 2, 3, 4] | b = [1, 2, 3, 4]
Chúng ta hãy xem clip thứ ba:
a = [[1, 2, 3], 2, 3, 4] b = a.copy() in(f"{a = } \t|\t {b = }") a[0][0] = 100 in(f"{a = } \t|\t {b = }")
Phân tích này tương tự như đoạn thứ hai, nhưng a[0] là đối tượng có thể thay đổi nên khi dữ liệu được sửa đổi, con trỏ của a[0] không thay đổi nên nội dung sửa đổi của a sẽ ảnh hưởng đến b.
a = [[1, 2, 3], 2, 3, 4] | b = [[1, 2, 3], 2, 3, 4] a = [[100, 2, 3], 2, 3, 4] | b = [[100, 2, 3], 2, 3, 4]
Đoạn cuối:
a = [[1, 2, 3], 2, 3, 4] b = sao chép. deepcopy(a) in(f"{a = } \t|\t {b = }") a[0][0] = 100 in(f"{a = } \t|\t {b = }")
Bản sao sâu sẽ tạo lại một đối tượng giống hệt a[0] trong bộ nhớ và để b[0] trỏ đến đối tượng này. Do đó, việc sửa đổi a[0] sẽ không ảnh hưởng đến b[0], do đó kết quả đầu ra như sau. :
a = [[1, 2, 3], 2, 3, 4] | b = [[1, 2, 3], 2, 3, 4] a = [[100, 2, 3], 2, 3, 4] | b = [[1, 2, 3], 2, 3, 4]
Làm sáng tỏ các đối tượng Python
Bây giờ chúng ta hãy xem ngắn gọn cách Cpython triển khai cấu trúc dữ liệu danh sách và chính xác những gì được xác định trong danh sách:
typedef struct { PyObject_VAR_HEAD /* Vector các con trỏ tới các phần tử danh sách. list[0] là ob_item[0], v.v. */ PyObject **ob_item; /* ob_item chứa không gian cho các phần tử 'đã phân bổ'. Số * hiện đang được sử dụng là ob_size. * Bất biến: * 0 <= ob_size <= allocated * len(list) == ob_size * ob_item == NULL ngụ ý ob_size == allocated == 0 * list.sort() tạm thời đặt allocated thành -1 để phát hiện đột biến. * * Các mục thường không được NULL, ngoại trừ trong quá trình xây dựng khi * danh sách chưa hiển thị bên ngoài hàm xây dựng nó. */ Py_ssize_t allocated; } PyListObject;
Trong cấu trúc được xác định ở trên:
- được phân bổ đại diện cho lượng không gian bộ nhớ được phân bổ, nghĩa là số lượng con trỏ có thể được lưu trữ. Khi đã sử dụng hết dung lượng, không gian bộ nhớ cần được áp dụng lại.
- ob_item trỏ đến một mảng thực sự lưu trữ các con trỏ tới các đối tượng Python trong bộ nhớ. Ví dụ: nếu chúng ta muốn lấy con trỏ tới đối tượng đầu tiên trong danh sách, thì đó là list->ob_item[0]. dữ liệu, đó là *(list->ob_item[ 0]).
- PyObject_VAR_HEAD là macro xác định cấu trúc con bên trong cấu trúc. Định nghĩa về cấu trúc con này như sau:
typedef struct { PyObject ob_base; Py_ssize_t ob_size; /* Số lượng mục trong phần biến */ } PyVarObject;
- Chúng ta sẽ không nói về đối tượng PyObject ở đây mà chủ yếu nói về ob_size. Nó cho biết có bao nhiêu dữ liệu được lưu trữ trong danh sách. Điều này khác với việc được phân bổ cho biết có bao nhiêu khoảng trắng trong mảng được trỏ tới bởi ob_item. có bao nhiêu mục được lưu trữ trong mảng dữ liệu ob_size <= được phân bổ.
Sau khi hiểu cấu trúc của danh sách, bây giờ chúng ta có thể hiểu cách bố trí bộ nhớ trước đó. Tất cả các danh sách không lưu trữ dữ liệu thực mà là con trỏ tới những dữ liệu này.
Tóm tắt
Trong bài viết này, chúng tôi chủ yếu giới thiệu với các bạn cách sao chép và bố trí bộ nhớ của các đối tượng trong python, cũng như việc xác minh địa chỉ bộ nhớ đối tượng. Cuối cùng, chúng tôi giới thiệu ngắn gọn về cấu trúc danh sách triển khai bên trong của cpython để giúp các bạn hiểu sâu hơn về bố cục bộ nhớ của. liệt kê các đối tượng
Trên đây là toàn bộ nội dung bài viết này Tôi là Lê Hùng Hẹn gặp lại các bạn ở số tiếp theo! ! ! Để có thêm bộ sưu tập nội dung thú vị, vui lòng truy cập dự án: https://github.com/Chang-LeHung/CSCore.
Theo dõi tài khoản công khai: Nhà sư nghiên cứu vô dụng để tìm hiểu thêm về máy tính (Java, Python, kiến thức cơ bản về hệ thống máy tính, thuật toán và cấu trúc dữ liệu).
Cuối cùng, bài viết này về sự hiểu biết sâu sắc về cách bố trí bộ nhớ và sao chép đối tượng của Python kết thúc ở đây. Nếu bạn muốn biết thêm về sự hiểu biết sâu sắc về cách bố trí bộ nhớ và sao chép đối tượng của Python, vui lòng tìm kiếm các bài viết CFSDN hoặc tiếp tục duyệt các bài viết liên quan. Tôi hy vọng tất cả các bạn sẽ ủng hộ blog của tôi trong tương lai! .

 Trung tâm cá nhân
Trung tâm cá nhân Điều phát hành
Điều phát hành



 4
4



Tôi là một lập trình viên xuất sắc, rất giỏi!