Hồi quy tuyến tính
Giới thiệu về hồi quy tuyến tính
Tạo dữ liệu
Để có thể trực quan thấy được ý tưởng của thuật toán, trước tiên chúng ta tạo ra một số dữ liệu hai chiều để hiển thị trực quan.
import numpy as np import matplotlib.pyplot as plt def true_fun(X): # Đây là hàm true mà chúng ta đặt, tức là mô hình chân lý cơ bản return 1.5*X + 0.2 np.random.seed(0) # Đặt hạt giống ngẫu nhiên n_samples = 30 # Đặt số điểm dữ liệu được lấy mẫu'''Tạo dữ liệu ngẫu nhiên dưới dạng tập huấn luyện và thêm một số nhiễu''' X_train = np.sort(np.random.rand(n_samples)) y_train = (true_fun(X_train) + np.random.randn(n_samples) * 0.05).reshape(n_samples,1) # Dữ liệu huấn luyện được thêm một lượng nhiễu ngẫu nhiên nhất định
Định nghĩa mô hình
Chúng ta có thể sử dụng trực tiếp LinearRegression trong sklearn:
từ sklearn.linear_model import LinearRegression model = LinearRegression() # Đây là mô hình của chúng tôi model.fit(X_train[:, np.newaxis], y_train) # Mô hình đào tạo print("Tham số đầu ra w:",model.coef_) print("Tham số đầu ra b:",model.intercept_)
Tham số đầu ra w: [[1.4474774]] Tham số đầu ra b: [0.22557542]
Lưu ý np.newaxis trong mã trên. Vì X_train là vectơ một chiều nên chức năng của nó là biến đổi X_train thành ma trận hai chiều N*1. Trên thực tế, việc viết X_train[:,None] cũng có tác dụng tương tự.
Về lý do tại sao bạn cần phải làm điều này, bạn có thể thử mà không cần làm điều này và lỗi sẽ là:
Định hình lại dữ liệu của bạn bằng cách sử dụng array.reshape(-1, 1) nếu dữ liệu của bạn có một tính năng duy nhất hoặc array.reshape(1, -1) nếu dữ liệu chỉ chứa một mẫu duy nhất.
Điều này có thể hiểu đơn giản là yêu cầu của thư viện sklearn đối với dữ liệu đào tạo, không thể là một vectơ một chiều.
Kiểm tra và so sánh mô hình
Chúng ta có thể thấy rằng kết quả đầu ra của chúng ta là 1,44 và 0,22, vẫn rất gần với câu trả lời đúng. Vì vậy, hãy chọn một loạt các tập kiểm tra để xem độ chính xác:
X_test = np.linspace(0,1,100) # Tạo 100 điểm cách đều nhau giữa 0 và 1 plt.plot(X_test, model.predict(X_test[:, np.newaxis]), label = "Model") # Vẽ các điểm phân tán đã lắp plt.plot(X_test, true_fun(X_test), label = "True function") # Kết quả thực tế plt.scatter(X_train, y_train) # Vẽ các điểm của tập huấn luyện plt.legend(loc="best") # Đặt nhãn vào vị trí thích hợp nhất plt.show()
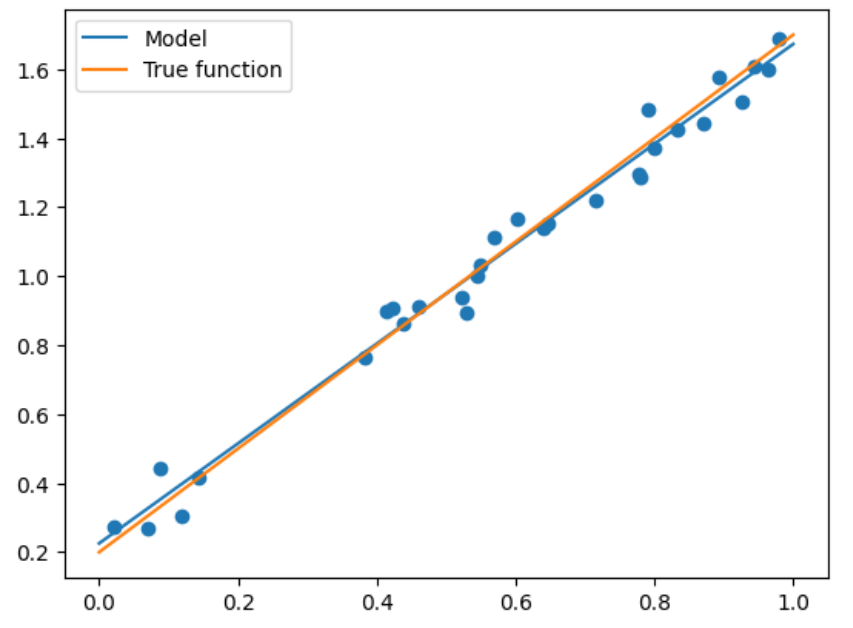
Tình huống trên là đơn giản nhất, nhưng khi xuất hiện các chiều cao hơn, chúng ta cần thực hiện hồi quy đa thức để đáp ứng nhu cầu.
Hồi quy đa thức
Triển khai cụ thể
Đối với hồi quy đa thức, hồi quy tuyến tính thường được sử dụng để giải \(y=\sum_{i=1}^m b_i \times x^i\), do đó thuật toán như sau:
import numpy as np import matplotlib.pyplot as plt from sklearn.pipeline import Pipeline from sklearn.preprocessing import PolynomialFeatures # Import các lớp có thể tính toán các tính năng đa thứcfrom sklearn.linear_model import LinearRegression from sklearn.model_selection import cross_val_score # Kiểm tra chéo def true_fun(X): # True functionreturn np.cos(1.5 * np.pi * X) np.random.seed(0) n_samples = 30 X = np.sort(np.random.rand(n_samples)) # Lấy mẫu và sắp xếp ngẫu nhiên y = true_fun(X) + np.random.randn(n_samples) * 0.1 độ = [1, 4, 15] # Đa thức có bậc cao nhất. Chúng ta thử khớp các đa thức có bậc 1, 4 và 15 tương ứngplt.figure(figsize=(14, 5)) for i in range(len(degrees)): ax = plt.subplot(1, len(degrees), i+1) # Tổng cộng có ba đồ thị. Lấy hình ảnh xử lý của đồ thị thứ i+1 plt.setp(ax, xticks = (), yticks = ()) # Điều này là để thiết lập các thuộc tính trong đồ thị ax polynomial_features = PolynomialFeatures(degree=degrees[i],include_bias=False) # Thiết lập một lớp cho hồi quy đa thức. Tham số đầu tiên là bậc cao nhất của đa thức và tham số thứ hai là có bao gồm độ lệch hay không linear_regression = LinearRegression() # Hồi quy tuyến tính pipeline = Pipeline([("polynomial_features", polynomial_features), ("linear_regression", linear_regression)]) # Sử dụng pipeline để tạo tầng mô hình pipeline.fit(X[:, np.newaxis], y) scores = cross_val_score(pipeline, X[:, np.newaxis], y, scoring="neg_mean_squared_error", cv=10) # Sử dụng xác thực chéo. Tham số đầu tiên là mô hình, tham số thứ hai là đầu vào, tham số thứ ba là nhãn, tham số thứ tư là phương pháp tính lỗi và tham số thứ năm là số lần gấp. X_test = np.linspace(0, 1, 100) plt.plot(X_test, pipeline.predict(X_test[:, np.newaxis]), label="Model") plt.plot(X_test, true_fun(X_test), label="True function") plt.scatter(X, y, edgecolor='b', s=20, label="Samples") plt.xlabel("x") plt.ylabel("y") plt.xlim((0, 1)) plt.ylim((-2, 2)) plt.legend(loc="best") plt.title("Degree {}\nMSE = {:.2e}(+/- {:.2e})".format(độ[i], -scores.mean(), điểm.std())) plt.show()
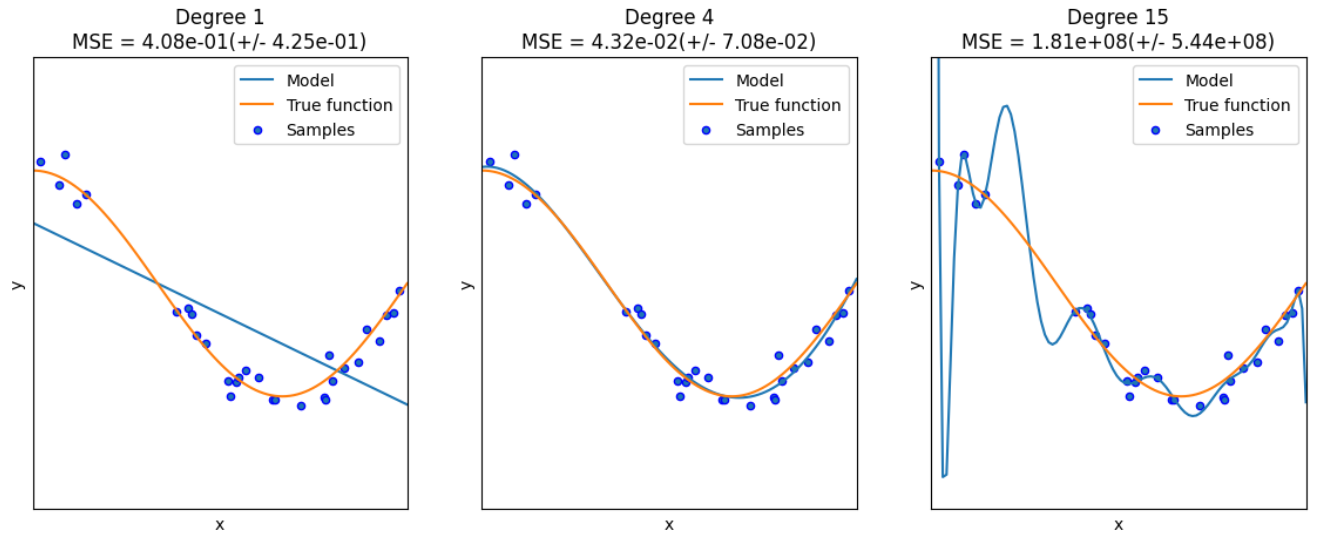
Sau đây là hai chỗ cần giải thích:
- PolynomialFeatures: Lớp này thực sự là một lớp để xây dựng các tính năng. Vì X ban đầu của chúng ta là một vectơ một chiều, nên bậc đa thức của nó là 1. Nếu chúng ta muốn xây dựng một đa thức, chúng ta cần sử dụng X để tính toán \(X^1,X^2,...,X^m\) (Đây là trường hợp của một biến. Nếu có nhiều biến, tích có hướng sẽ được tính toán.) Sau đó, lớp này triển khai một hoạt động như vậy và xây dựng m tính năng.
- Pipeline: Đây là một pipeline thuận tiện cho chúng ta. Nó cộng nhiều module lại với nhau để chúng ta không phải tính toán từng module từng bước. Ở đây, các module PolynomialFeatures và Linear Regression được cộng lại với nhau. Sau khi chúng ta truyền X vào, chúng ta thực hiện hồi quy tuyến tính sau khi xây dựng feature. Do đó Lắp đường ống .
Chúng tôi cũng sử dụng ý tưởng xác thực chéo, đây là ý tưởng rất phổ biến và sẽ không được giải thích chi tiết.
Hồi quy logistic
Mô tả ngắn gọn về ý tưởng thuật toán
Đối với hồi quy logistic, hầu hết các vấn đề là phân loại nhị phân. Cho dữ liệu \(X=\{x_1,x_2,...,\}, Y=\{y_1,y_2,...,\}\), hãy xem xét nhiệm vụ phân loại nhị phân, khi đó hàm giả thuyết của nó là:
\[h_{\theta}(x) = g(\theta^Tx)=g(w^Tx+b)=\frac{1}{1+e^{w^Tx+b}} \]
để biểu diễn xác suất của loại 1 hoặc loại 0.
Sau đó, hàm mất mát của nó thường được xác định bằng phương pháp ước tính độ tin cậy tối đa:
\[L(\theta)=\prod_{i=1}p(y_i=1\mid x_i)=h_{\theta}(x_1)(1-h_{\theta}(x))... \]
Ở đây chúng ta giả sử rằng \(y_1=1,y_2=0\). Khi đó hàm số được tối đa hóa và phép đơn giản hóa là:
\[\theta^{*}=arg\min_{\theta}(-L(\theta))=arg\min_{\theta}-\ln(L(\theta))\\ =\sum_{i=1}(-y_i\theta^Tx_i+\ln(1+e^{\theta^Tx_i})) \]
Sau đó sử dụng phương pháp giảm dần độ dốc.
Triển khai thuật toán
# Sau đây là phiên bản sklearnimport numpy as np from sklearn.datasets import fetch_openml mnist = fetch_openml("mnist_784") # Dữ liệu X, y = mnist['data'], mnist['target'] X_train = np.array(X[:60000], dtype = float) y_train = np.array(y[:60000], dtype = float) X_test = np.array(X[60000:], dtype = float) y_test = np.array(y[60000:], dtype = float) # Xây dựng tập huấn luyện và tập dữ liệuprint(X_train.shape) print(y_train.shape) print(X_test.shape) print(y_test.shape)
(60000, 784) (60000,) (10000, 784) (10000,)
từ sklearn.linear_model import LogisticRegression clf = LogisticRegression(penalty='l1', solver='saga', tol=0.1) # Tham số đầu tiên là điều khoản phạt để chọn l1 hoặc l2, tol là điều kiện dừng giải, solver có thể được coi là solver clf.fit(X_train, y_train) score = clf.score(X_test, y_test) print("Điểm kiểm tra với hình phạt L1: %.4f" % score)
Điểm kiểm tra với hình phạt L1: 0,9245
Điều tôi tò mò ở đây là hồi quy logistic là một bài toán phân loại nhị phân, nhưng ở đây chúng ta trực tiếp đưa cho nó một tập dữ liệu bài toán phân loại đa. Tại sao nó có thể được giải quyết trực tiếp? Sau khi kiểm tra, tôi thấy rằng chính sự tối ưu hóa trong lớp giúp bạn đạt được quy trình này.
# Sau đây là phiên bản pytorch từ torch.utils.data import DataLoader từ torchvision import datasets import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt từ sklearn.linear_model import LogisticRegression từ sklearn.metrics import classification_report import numpy as np train_dataset = datasets.MNIST(root = p_parent_path+'/datasets/', train = True,transform = transforms.ToTensor(), download = False) test_dataset = datasets.MNIST(root = p_parent_path+'/datasets/', train = False, transform = transforms.ToTensor(), download = False) # Tải tập dữ liệu batch_size = len(train_dataset) train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True) test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True) # Bộ tải dữ liệu X_train,y_train = next(iter(train_loader)) X_test,y_test = next(iter(test_loader)) # In 100 hình ảnh đầu tiên images, labels= X_train[:100], y_train[:100] # Sử dụng images để tạo lưới có kích thước 10 hình ảnh img = torchvision.utils.make_grid(images, nrow=10) # Định dạng của cv2.imshow() là (size1,size1,channels), trong khi định dạng của img là (channels,size1,size1), # do đó bạn cần sử dụng .transpose() để chuyển đổi số kênh màu thành chiều thứ ba img = img.numpy().transpose(1,2,0) print(images.shape) print(labels.reshape(10,10)) print(img.shape) plt.imshow(img) plt.show()
4, 8, 5, 3, 1, 5, 2, 4], [5, 4, 8, 5, 5, 1, 1, 6, 0, 4] 2, 7, 3, 8, 0], [5, 6, 4, 9, 0, 6, 1, 2, 3, 3], [4, 3, 4, 8, 5, 3, 1, 5, 2, 4] 1, 8, 6, 3, 7, 7, 9, 5, 9], [8, 4, 7, 0, 3, 6, 6, 2, 5, 3], [2, 0, 6, 5, 1, 7, 2, 7, 1, 2]]) (302, 302, 3)

X_train,y_train = X_train.cpu().numpy(),y_train.cpu().numpy() # chuyển đổi tenxơ thành dạng mảng) X_test,y_test = X_test.cpu().numpy(),y_test.cpu().numpy() # chuyển đổi tenxơ thành dạng mảng) X_train = X_train.reshape(X_train.shape[0],784) # Mở rộng thành dạng vectơ 1 chiều, độ dài là 28*28, bằng 784 X_test = X_test.reshape(X_test.shape[0],784) model = LogisticRegression(solver='lbfgs', max_iter = 400) model.fit(X_train, y_train) y_pred = model.predict(X_test) print(classification_report(y_test, y_pred)) # In báo cáo
9 0,71 0,56 0,63 9 0,75 0,56 0,63 10 12 13 14 15 16 17 18 19 20 21 22 24 25 27 28 29 30 31 32 33 34 35 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 8 0,74 0,75 0,73 100
Cây quyết định
Trước tiên, chúng ta hãy giới thiệu một tập dữ liệu, tập dữ liệu iris. Tập dữ liệu này chứa 150 bản ghi trong 3 danh mục, 50 dữ liệu trong mỗi danh mục và mỗi bản ghi có 4 đặc điểm: chiều dài lá đài, chiều rộng lá đài, chiều dài cánh hoa và chiều rộng cánh hoa. 4 đặc điểm này có thể được sử dụng để dự đoán hoa iris thuộc giống nào (iris-setosa, iris-versicolour, iris-virginica).
import seaborn as sns from pandas import plotting import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn import tree # Tải tập dữ liệu data = load_iris() # Chuyển đổi sang định dạng DataFrame df = pd.DataFrame(data.data, columns=data.feature_names) df['Species'] = data.target # Thêm cột species # Xem thông tin tập dữ liệu print(f"Thông tin tập dữ liệu: \n{df.info()}") # Xem 5 dữ liệu đầu tiên print(f"5 dữ liệu đầu tiên: \n{df.head()}") df.describe()
RangeIndex: 150 mục, từ 0 đến 149 Cột dữ liệu (tổng cộng 5 cột): # Cột Không Null Số lượng Dtype --- ------ -------------- ----- 0 chiều dài đài hoa (cm) 150 không null float64 1 chiều rộng đài hoa (cm) 150 không null float64 2 chiều dài cánh hoa (cm) 150 không null float64 3 chiều rộng cánh hoa (cm) 150 không null float64 4 Loài 150 không null int32 dtypes: float64(4), int32(1) sử dụng bộ nhớ: 5,4 KB Thông tin tập dữ liệu: Không có 5 mục đầu tiên: chiều dài đài hoa (cm) chiều rộng đài hoa (cm) chiều dài cánh hoa (cm) chiều rộng cánh hoa (cm) \ 0 5,1 3,5 1,4 0,2 1 4,9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2 3 4.6 3.1 1.5 0.2 4 5.0 3.6 1.4 0.2 Loài 0 0 1 0 2 0 3 0 4 0
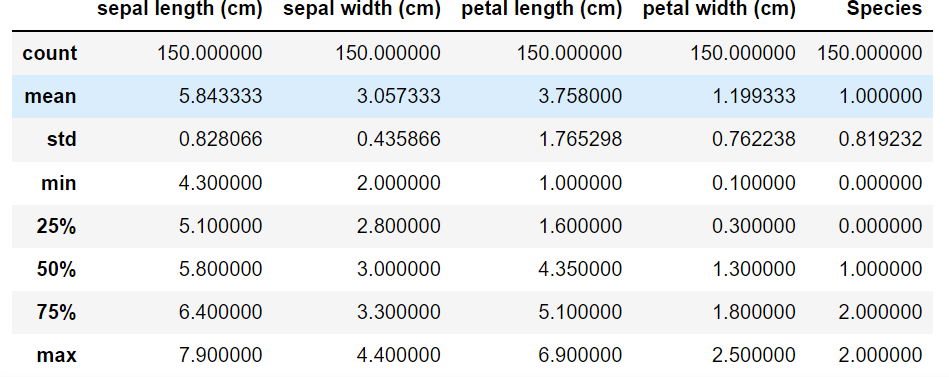
Trên đây là quan sát sơ bộ về dữ liệu. Chúng ta hãy xem xét việc triển khai thuật toán cụ thể:
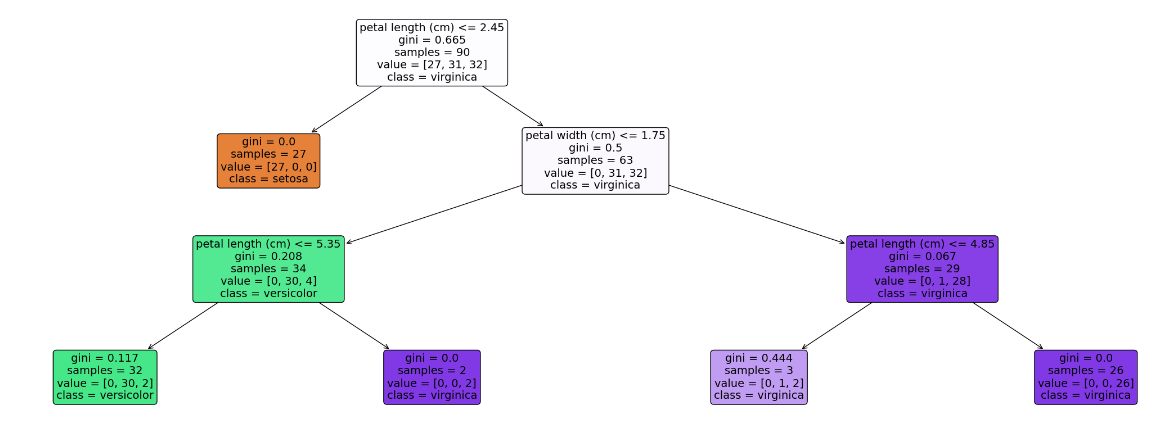
_train_split(X, y, test_size = 0,4, random_state = 42) mô hình = DecisionTreeClassifier(max_depth = 3, random_state = 42) 42) # Độ sâu tối đa của cây quyết định là 3 model.fit(X_train, y_train) # Xuất cây dưới dạng văn bản text_representation = tree.export_text(model) print(text_representation) # Vẽ cây dưới dạng hình ảnh plt.figure(figsize=(30, 10), facecolor='w') a = tree.plot_tree(model, feature_names = feature_names, class_names = labels, rounded = True,filled = True, fontsize = 14) plt.show()
[0 1 2] ['setosa' 'versicolor' 'virginica'] {0: 'setosa', 1: 'versicolor', 2: 'virginica'} |--- tính năng_2 <= 2,45 | |--- lớp: setosa |--- tính năng_2 > 2,45 | |--- tính năng_3 <= 1,75 | | |--- tính năng_2 <= 5,35 | | | |--- lớp: versicolor | | |--- tính năng_2 > 5,35 | | ||--- lớp: virginica | |--- tính năng_3 > 1,75 | | | |--- tính năng_2 <= 4,85 | | | |--- lớp: virginica | | ||--- tính năng_2 > 4,85 | | ||--- lớp: virginica
MLP
Để biết thêm thông tin về perceptron nhiều lớp, hãy xem blog của tôi về mạng nơ-ron.
Tiếp theo chúng ta tập trung vào việc triển khai thuật toán.
từ sklearn.neural_network nhập MLPClassifier từ sklearn.datasets nhập fetch_openml nhập numpy dưới dạng np mnist = fetch_openml("mnist_784") # Tải tập dữ liệu X, y = mnist['data'], mnist['target'] X_train = np.array(X[:60000], dtype=float) y_train = np.array(y[:60000], dtype=float) X_test = np.array(X[60000:], dtype=float) y_test = np.array(y[60000:], dtype=float) clf = MLPClassifier(alpha = 1e-5, hidden_layer_sizes = (15,15), random_state=1) # alpha là hệ số phạt của thuật ngữ chính quy hóa và thứ hai là số lượng nút ẩn trong mỗi lớp, ở đây có 2 lớp, mỗi lớp có 15 nút clf.fit(X_train, y_train) score = clf.score(X_test, y_test) score
0,9124
Sau đây là một số thông số đáng chú ý:
- kích hoạt: Chọn chức năng kích hoạt, tùy chọn {'identity','logistic','tanh','relu'}, mặc định là relu
- trình giải: trình tối ưu hóa trọng số, tùy chọn {'lbfgs','sgd','adam'}, mặc định là adam
- learning_rate_init: tốc độ học ban đầu, chỉ được sử dụng trong sgd hoặc adam
SVM
Chúng tôi vẫn tập trung vào việc triển khai thuật toán SVM.
Việc lựa chọn các hạt nhân khác nhau chủ yếu liên quan đến việc chỉ định tham số hạt nhân trong svm.SVC.
SVM tuyến tính
Nhập khẩu NUMPY khi nhập NP matplotlib.pyplot dưới dạng PLT từ Sklearn Nhập dữ liệu SVM = NP.Array ([0.1, 0.7], [0.3, 0.6], [0.4, 0.1] 7, 0.8], [0,5, 0,72]]) y_min, y_max = data[:,1].min() - 0.2, data[:,0].max() + 0.2 xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.002), np.arange(y_min, y_max, 0.002)) # Tạo mạng lưới model_linear = svm.SVC(kernel = 'linear', C = 0.001) # Mô hình SVM tuyến tính model_linear.fit(data, label) Z = model_linear.predict(np.c_[xx.ravel(), yy.ravel()]) # Đầu tiên kéo xx (size*size) và yy (size*size) vào một chiều, sau đó kết nối chúng để trở thành ma trận hai cột, rồi sử dụng nó làm X để dự đoán Z = Z.reshape(xx.shape) plt.contourf(xx,yy, Z, cmap=plt.cm.ocean, alpha=0.6) # Có thể hiểu là vẽ đường đồng mức, xx là tọa độ ngang, yy là tọa độ trục, Z là giá trị của điểm tọa độ chính xác và cmap là bảng màu plt.scatter(data[:6,0],data[:6,1], marker='o', color='r', s=100, lw=3) plt.scatter(data[6:,0],data[6:,1], marker='x', color='k', s=100, lw=3) plt.title("SVM tuyến tính") plt.show()
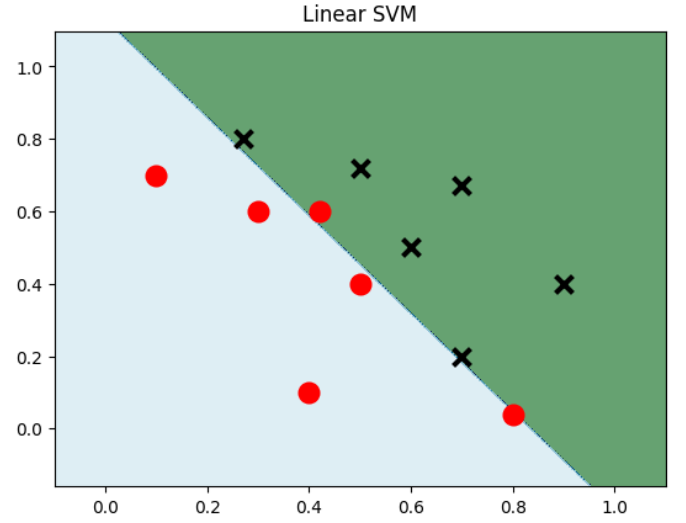
Hạt nhân đa thức
plt.figure(figsize=(16,15)) # Vẽ nhiều mức đa thức để so sánh với i, bậc trong enumerate([1,3,5,7,9,12]): model_poly = svm.SVC(C=0.001, kernel='poly', degree = degree) # Hạt nhân đa thức model_poly.fit(data, label) Z = model_poly.predict(np.c_[xx.ravel(), yy.ravel()])#Dự đoán Z = Z.reshape(xx.shape) plt.subplot(3,2, i+1) plt.subplots_adjust(wspace=0.2, hspace=0.2) # Điều chỉnh khoảng cách giữa các biểu đồ con plt.contourf(xx,yy, Z, cmap=plt.cm.ocean, alpha=0.6) plt.scatter(data[:6, 0], data[:6, 1], marker='o', color='r', s=100, lw=3) plt.scatter(data[6:, 0], data[6:, 1], marker='x', color='k', s=100, lw=3) plt.title('Poly SVM với $\degree=$' + str(degree)) plt.show()
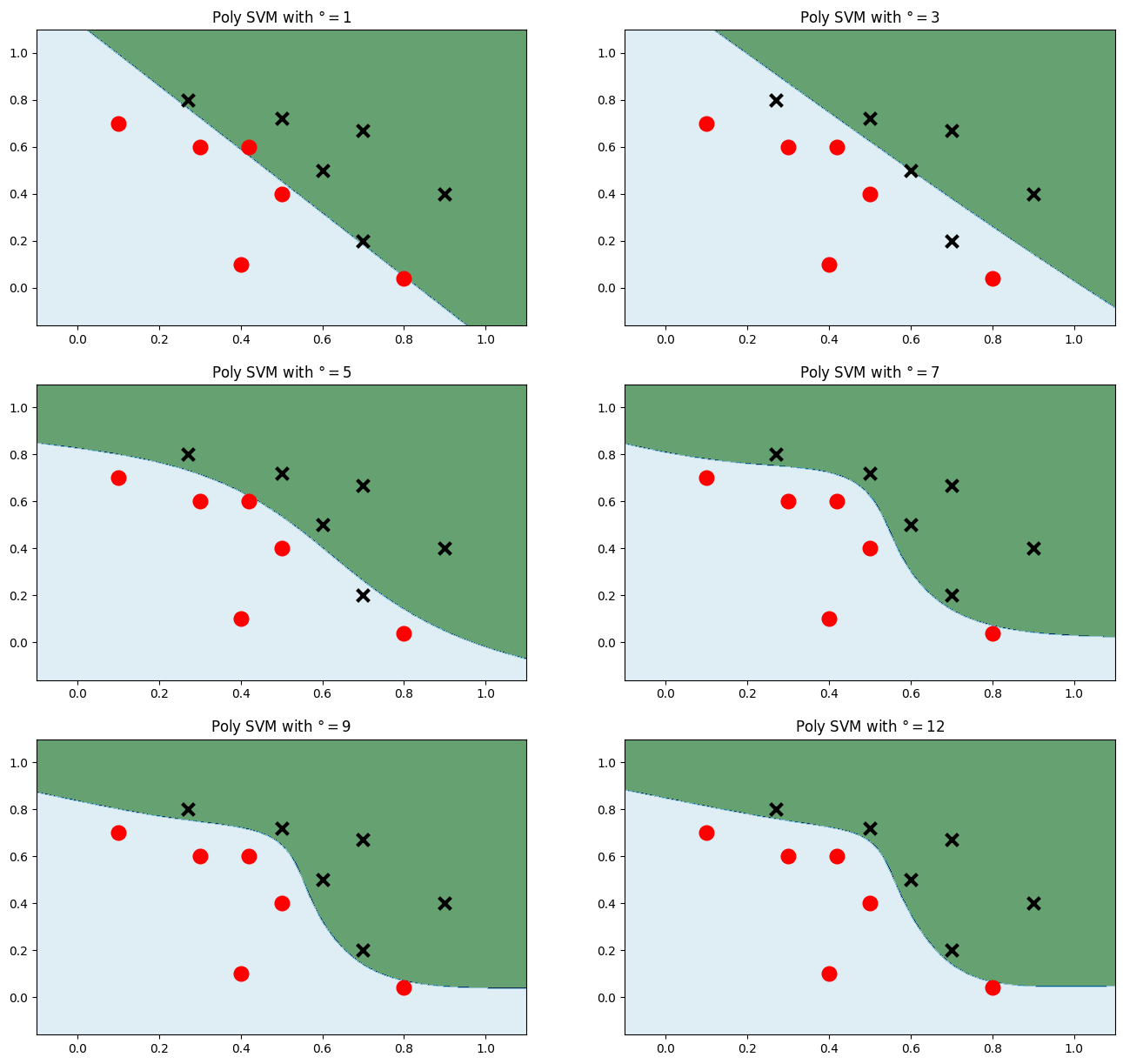
Hạt nhân Gaussian
plt.figure(figsize=(16,15)) cho i, gamma trong enumerate([1,5,15,35,45,55]): model_rbf = svm.SVC(kernel='rbf', gamma=gamma, C = 0,001) # Chọn mô hình hạt nhân Gaussian model_rbf.fit(data, label) Z = model_rbf.predict(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) plt.subplot(3, 2, i + 1) plt.subplots_adjust(wspace=0,4, hspace=0,4) plt.contourf(xx, yy, Z, cmap=plt.cm.ocean, alpha=0,6) # Vẽ các điểm đào tạo plt.scatter(data[:6, 0], data[:6, 1], đánh dấu = 'o', màu = 'r', s = 100, lw = 3) plt.scatter (dữ liệu [6:, 0], dữ liệu [6:, 1], đánh dấu = 'x', màu = 'k', s = 100, lw = 3) plt.title ('RBF SVM với $\gamma = $' + str (gamma)) plt.show()
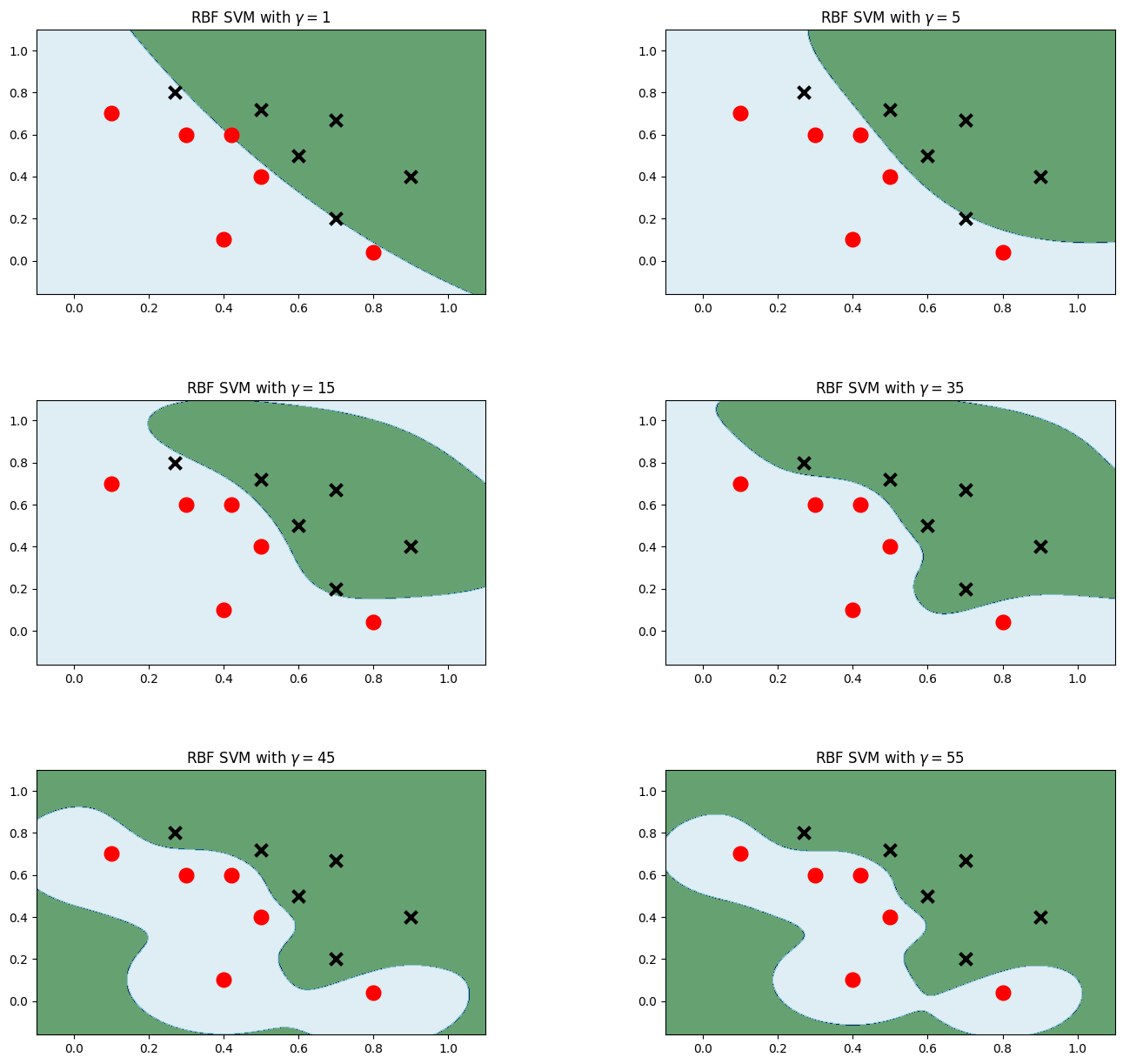
So sánh tác động của các loại hạt nhân khác nhau lên Mnist
Đọc dữ liệu
từ sklearn nhập svm nhập numpy dưới dạng np từ time nhập time từ sklearn.metrics nhập accuracy_score từ struct nhập unpack từ sklearn.model_selection nhập GridSearchCV def readimage(path): với open(path, 'rb') là f: magic, num, rows, cols = unpack('>4I', f.read(16)) img = np.fromfile(f, dtype=np.uint8).reshape(num, 784) trả về img def readlabel(path): với open(path, 'rb') là f: magic, num = unpack('>2I', f.read(8)) lab = np.fromfile(f, dtype=np.uint8) trả về lab train_data = readimage("../../datasets/MNIST/raw/train-images-idx3-ubyte")#Read data train_label = đọc nhãn("../../datasets/MNIST/raw/train-labels-idx1-ubyte") dữ liệu kiểm tra = đọc ảnh("../../datasets/MNIST/raw/t10k-images-idx3-ubyte") nhãn kiểm tra = đọc nhãn("../../datasets/MNIST/raw/t10k-labels-idx1-ubyte") in(train_data.shape) in(train_label.shape)
(60000, 784) (60000,)
Hạt nhân Gaussian
# Có quá nhiều dữ liệu trong tập dữ liệu. Để tiết kiệm thời gian, chúng tôi chỉ sử dụng 4000 dữ liệu đầu tiên để đào tạo train_data=train_data[:4000] train_label=train_label[:4000] test_data=test_data[:400] test_label=test_label[:400] svc=svm.SVC() tham số = {"kernel":['rbf'], "C":[1]} print("Train....") clf = GridSearchCV(svc, tham số, n_jobs=-1) # Tìm kiếm lưới để xác định tham số start = time() clf.fit(train_data, train_label) end = time() t = end - start print("Thời gian đào tạo: %dmin%.3fsec" % (t//60, t-60 * (t//60))) dự đoán = clf.predict(test_data) print("độ chính xác:", độ chính xác_điểm(dự đoán, test_label)) chính xác = [0] * 10 tổng = [0] * 10 i = 0 j = 0 trong khi i < len(test_label): tổng[test_label[i]] += 1 nếu dự đoán[i] == test_label[i]: j += 1 i += 1 print("Độ chính xác của tập kiểm tra:", j/400)
Đào tạo.... Thời gian đào tạo: 0 phút 7,548 giây Độ chính xác: 0,955 Độ chính xác của bộ kiểm tra: 0,955
Hạt nhân đa thức
tham số = {'kernel':['poly'], 'C':[1]}#Sử dụng hạt nhân đa thức print("Train...") clf=GridSearchCV(svc,parameters,n_jobs=-1) start = time() clf.fit(train_data, train_label) end = time() t = end - start print('Train:%dmin%.3fsec' % (t//60, t - 60 * (t//60))) prediction = clf.predict(test_data) print("accuracy: ", accuracy_score(prediction, test_label)) accuracy=[0]*10 sumall=[0]*10 i=0 j=0 while i
Đào tạo... Đào tạo: Độ chính xác 0 phút 6,438 giây: 0,93 Độ chính xác của bộ kiểm tra: 0,93
Hạt nhân tuyến tính
tham số = {'kernel':['linear'], 'C':[1]}#Sử dụng kernel tuyến tính print("Train...") clf=GridSearchCV(svc,parameters,n_jobs=-1) start = time() clf.fit(train_data, train_label) end = time() t = end - start print('Train:%dmin%.3fsec' % (t//60, t - 60 * (t//60))) prediction = clf.predict(test_data) print("accuracy: ", accuracy_score(prediction, test_label)) accuracy=[0]*10 sumall=[0]*10 i=0 j=0 while i
Đào tạo... Đào tạo: Độ chính xác 0 phút 3,712 giây: 0,9175 Độ chính xác của bộ kiểm tra: 0,9175
NBay có
Lời gọi đến phần này của thuật toán tương đối đơn giản:
import numpy as np import matplotlib.pyplot as plt import seaborn as sns; sns.set() from sklearn.datasets import make_blobs # make_blobs: Tạo tập dữ liệu để phân cụm # n_samples: số điểm mẫu, n_features: chiều của dữ liệu, centers: các điểm trung tâm của dữ liệu được tạo, giá trị mặc định là 3 # cluster_std: độ lệch chuẩn của tập dữ liệu, số dấu phẩy động hoặc chuỗi dấu phẩy động, giá trị mặc định là 1.0, random_state: hạt giống ngẫu nhiên X, y = make_blobs(n_samples = 100, n_features = 2, centers = 2, random_state = 2, cluster_std = 1.5) plt.scatter(X[:,0], X[:,1], c = y, s = 50, cmap = 'RdBu') plt.show()
Đầu tiên hãy vẽ biểu đồ phân tán của tập dữ liệu huấn luyện:
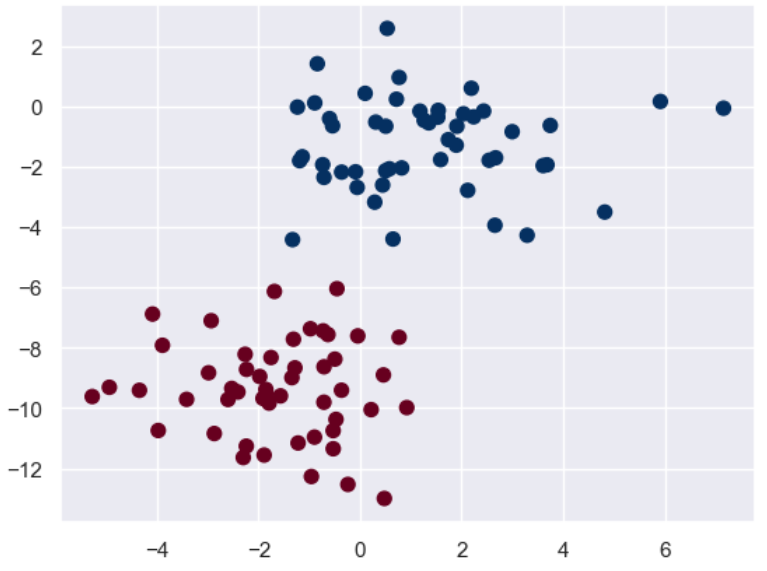
Tiếp theo, chúng ta hãy xây dựng bộ thử nghiệm của riêng mình để xem hiệu ứng:
từ sklearn.naive_bayes import GaussianNB model = GaussianNB() # Naive Bayes model.fit(X, y) rng = np.random.RandomState(0) X_test = [-6, -14] + [14,18] * rng.rand(5000,2) # Tạo tập kiểm tra y_pred = model.predict(X_test) # Biểu diễn dữ liệu của tập huấn luyện và tập kiểm tra bằng hình ảnh. Những hình ảnh có màu tối và đường kính lớn là tập huấn luyện, và những hình ảnh có màu sáng và đường kính nhỏ là tập kiểm tra plt.scatter(X[:,0],X[:,1], c = y, s = 50, cmap = 'RdBu') lim = plt.axis() # Lấy các tham số giới hạn trục hiện tại plt.scatter(X_test[:,0], X_test[:,1], c = y_pred, s = 20, cmap='RdBu', alpha = 0.1) plt.axis(lim) plt.show()
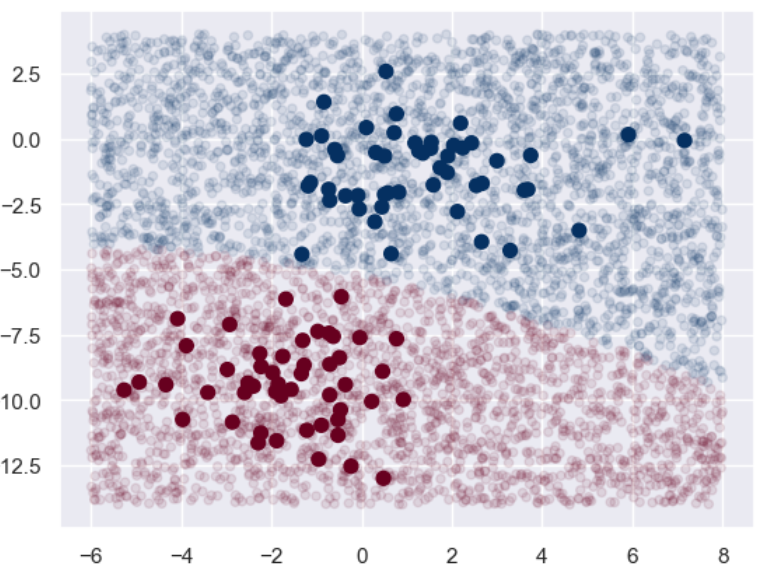
Có thể thấy rằng ranh giới giữa hai phạm trù này vẫn còn rất rõ ràng.
Chúng ta cũng có thể xem xét các xác suất dự đoán trông như thế nào:
yprob = mô hình.predict_proba(X_test) yprob[:20].round(2)
Ra ngoài[25]
mảng([[0, 1.], [0, 1.], [0, 1.], [0, 1.], [0, 1.], [0, 1.], [0, 1.], [0, 1.], [1, 0.], [0, 1.], [0, 1.], [0, 1.], [0, 1.], [0, 1.], [0, 1.], [0, 1.], [0, 94, 0,06], [0, 1.], [0, 1.], [0, 1.], [0,01, 0,99], [0, 1.], [0, 1.]])
Túi và Rừng ngẫu nhiên
Để biết thêm thông tin về khía cạnh này, vui lòng tham khảo bài đăng trên blog của tôi.
Tiếp theo chúng ta tiếp tục tập trung vào việc triển khai thuật toán:
Đầu tiên, tập dữ liệu được tải:
import pandas dưới dạng pd từ sklearn.datasets import load_wine từ sklearn.model_selection import train_test_split từ sklearn.metrics import accuracy_score từ sklearn.tree import DecisionTreeClassifier import matplotlib.pyplot dưới dạng plt wine = load_wine() # Sử dụng tập dữ liệu wine print(f"All features: {wine.feature_names}") X = pd.DataFrame(wine.data, columns = wine.feature_names) y = pd.Series(wine.target) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 1)
Tất cả các tính năng: ['rượu', 'axit malic', 'tro', 'độ kiềm của tro', 'magiê', 'phenol tổng', 'flavonoid', 'phenol không phải flavonoid', 'proanthocyanins', 'cường độ màu', 'sắc thái', 'od280/od315_of_diluted_wines', 'proline']
Tiếp theo, chúng ta hãy xem nhanh kết quả sẽ như thế nào nếu sử dụng một cây quyết định duy nhất:
# Xây dựng và đào tạo bộ phân loại cây quyết định base_model = DecisionTreeClassifier(max_depth = 1, criteria='gini', random_state = 1) # Sử dụng chỉ số Gini làm tiêu chí lựa chọn base_model.fit(X_train, y_train) y_pred = base_model.predict(X_test) print(f"Độ chính xác của cây quyết định là: {accuracy_score(y_test, y_pred):.3f}")
Độ chính xác của cây quyết định là: 0,694
Như bạn thấy, độ chính xác không đủ cho một cây quyết định đơn giản.
Sau đó, chúng ta hãy thử đóng gói tập hợp với cây quyết định này làm bộ phân loại cơ sở để xem chúng ta có thể cải thiện được bao nhiêu:
from sklearn.ensemble import BaggingClassifier # Bộ phân loại cơ sở ở đây là mô hình cây quyết định được xây dựng ở trên. Mặc dù đã được điều chỉnh một lần trước đó, nhưng điều này không ảnh hưởng đến nó. Nó cũng nên được điều chỉnh lại model = BaggingClassifier(base_estimator = base_model, n_estimators = 50, # Số lượng tối đa của trình học yếu là 50 random_state = 1) model.fit(X_train, y_train) y_pred = model.predict(X_test)# Dự đoán print(f"Độ chính xác của BaggingClassifier: {accuracy_score(y_test,y_pred):.3f}")
Độ chính xác của BaggingClassifier: 0,917
Bạn có thể thấy sự cải thiện khá rõ ràng! Tiếp theo, chúng ta hãy tập trung vào tham số quan trọng - tác động của số lượng bộ phân loại cơ sở lên kết quả:
# Hãy kiểm tra hiệu ứng của số lượng bộ phân loại cơ sở x = list(range(2,102,2)) # một số chẵn giữa 2 và 102 y = [] đối với i trong x: model = BaggingClassifier(base_estimator = base_model, n_estimators = i, random_state = 1) model.fit(X_train, y_train) model_test_sc = accuracy_score(y_test, model.predict(X_test)) y.append(model_test_sc) # Lưu trữ điểm số plt.style.use('ggplot') # Đặt kiểu nền bản vẽ plt.title("Hiệu ứng của n_estimators", pad = 20) plt.xlabel("Số lượng bộ ước tính cơ sở") plt.ylabel("Độ chính xác của BaggingClassifier") plt.plot(x,y) plt.show()
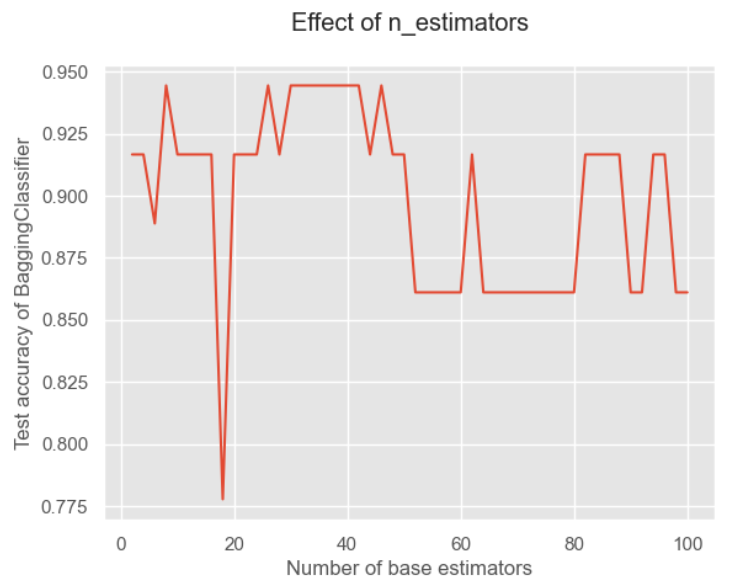
Có thể thấy rằng càng có nhiều bộ phân loại cơ sở thì càng tốt! Bởi vì quá nhiều giá trị có thể dẫn đến tình trạng trùng lặp và kết quả phân loại kém.
Tiếp theo, chúng ta hãy xem xét việc triển khai thuật toán cải tiến - rừng ngẫu nhiên:
từ sklearn.ensemble nhập RandomForestClassifier model = RandomForestClassifier( n_estimators = 50, random_state = 1) model.fit(X_train, y_train) y_pred = model.predict(X_test) print(f"Độ chính xác của RandomForestClassifier: {accuracy_score(y_test,y_pred):.3f}")
Độ chính xác của RandomForestClassifier: 0,972
Có thể thấy rằng do rừng ngẫu nhiên bổ sung tính năng ngẫu nhiên nên tính đa dạng của bộ phân loại cơ sở được cải thiện và độ chính xác của phân loại cũng được cải thiện hơn nữa.
Chúng ta cũng hãy quan sát tác động của số lượng bộ phân loại cơ sở lên kết quả:
x = list(range(2, 102, 2))# Số lượng ước lượng là n_estimators. Ở đây chúng ta lấy một số chẵn [2,102]y = [] cho i trong x: model = RandomForestClassifier(n_estimators=i, random_state=1) model.fit(X_train, y_train) model_test_sc = accuracy_score(y_test, model.predict(X_test)) y.append(model_test_sc) plt.style.use('ggplot') plt.title("Hiệu ứng của n_estimators", pad=20) plt.xlabel("Số lượng ước lượng cơ sở") plt.ylabel("Kiểm tra độ chính xác của RandomForestClassifier") plt.plot(x, y) plt.show()
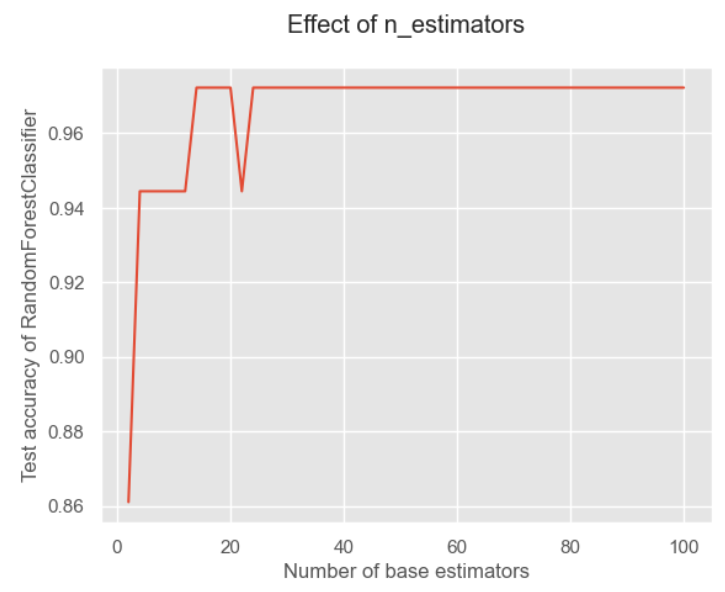
Đối với rừng ngẫu nhiên, tôi nghĩ lý do là vì nó thêm tính ngẫu nhiên vào các đặc điểm nên không quá nhạy cảm với số lượng.
Tăng cường
Để biết thêm thông tin về AdaBoost, bạn cũng có thể đọc blog của tôi.
Dưới đây chúng tôi vẫn tập trung vào việc triển khai thuật toán:
Tương tự như vậy, trước tiên hãy nhập dữ liệu, sau đó xem mô hình tốt như thế nào trên một cây quyết định duy nhất:
từ sklearn.datasets nhập load_wine từ sklearn.model_selection nhập train_test_split từ sklearn nhập metrics nhập pandas dưới dạng pd từ sklearn.tree nhập DecisionTreeClassifier từ sklearn.metrics nhập accuracy_score wine = load_wine() #Sử dụng tập dữ liệu wine print(f"Tất cả các tính năng: {wine.feature_names}") X = pd.DataFrame(wine.data, columns=wine.feature_names) y = pd.Series(wine.target) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=1) base_model = DecisionTreeClassifier(max_depth=1, criteria='gini', random_state=1) base_model.fit(X_train, y_train) y_pred = base_model.predict(X_test) print(f"Độ chính xác của cây quyết định: {accuracy_score(y_test,y_pred):.3f}")
Độ chính xác của cây quyết định là: 0,694
Kết quả vẫn giống như trước.
Sau đó chúng ta thử áp dụng thuật toán AdaBoost để phù hợp:
từ sklearn.ensemble nhập AdaBoostClassifier từ sklearn.model_selection nhập GridSearchCV model = AdaBoostClassifier(base_estimator=base_model, n_estimators=50, learning_rate = 0.8) # n_estimators và learning_rate là các tham số cần điều chỉnh, lr là hệ số suy giảm trọng số của mô hình học yếu.fit(X_train, y_train) y_pred = model.predict(X_test) acc = metrics.accuracy_score(y_test, y_pred) # Độ chính xác print(f"Độ chính xác: {acc:.2}")
Độ chính xác: 0,97
Bạn có thể thấy hiệu quả được cải thiện đáng kể! Nhưng tham số này được chúng tôi khởi tạo ngẫu nhiên và chúng tôi cố gắng sử dụng tìm kiếm lưới để tìm kiếm các tham số hoạt động tốt nhất trên tập huấn luyện:
hyperparameter_space = {"n_estimators":list(range(2,102,2)), "learning_rate":[0,1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1]} gs = GridSearchCV(AdaBoostClassifier(algorithm='SAMME.R', random_state = 1), param_grid = hyperparameter_space, scoring = 'accuracy', n_jobs = -1, cv = 5) gs.fit(X_train, y_train) print("Các tham số tốt nhất là:",gs.best_params_) print("Điểm tốt nhất là:",gs.best_score_)
Các tham số tốt nhất là: {'learning_rate': 0.8, 'n_estimators': 42} Điểm tốt nhất là: 0.9857142857142858
Chúng ta hãy xem xét điểm số của nó trong bộ bài kiểm tra:
model = AdaBoostClassifier(base_estimator=base_model, n_estimators=42, learning_rate = 0.8) model.fit(X_train, y_train) y_pred = model.predict(X_test) acc = metrics.accuracy_score(y_test, y_pred) # Độ chính xác print(f"Độ chính xác: {acc:.2}")
Độ chính xác: 0,94
Bạn có thể thấy rằng nó không tốt bằng các thông số trước đó của chúng tôi. Cần lưu ý ở đây rằng xác thực chéo K-fold được thực hiện khi thực hiện tìm kiếm lưới. Lúc đầu, tôi nghĩ rằng tìm kiếm dạng lưới sẽ tìm kiếm các tham số phù hợp nhất trên tập dữ liệu đào tạo, điều này cần phải được lưu ý.
thuật toán k-means
Để biết phần giới thiệu chi tiết về thuật toán phân cụ, vui lòng xem blog của tôi.
Tiếp theo chúng ta tiếp tục tập trung vào việc triển khai thuật toán.
từ sklearn.cluster nhập KMeans nhập matplotlib.pyplot dưới dạng plt nhập numpy dưới dạng np nhập matplotlib dưới dạng mpl từ sklearn nhập tập dữ liệu %matplotlib trực tuyến
# Trước khi phân cụm X = np.random.rand(1000,2) plt.scatter(X[:,0], X[:,1], marker='o')
# Khởi tạo trọng tâm và chọn k từ dữ liệu gốc làm trọng tâm def IiniCentroids(X, k): index = np.random.randint(0, len(X)-1, k) return X[index]
# Sau khi phân cụm kmeans = KMeans(n_clusters = 4) # Chia thành 2 loại kmeans.fit(X) label_pred = kmeans.labels_ plt.scatter(X[:,0], X[:,1], c= label_pred) plt.show()
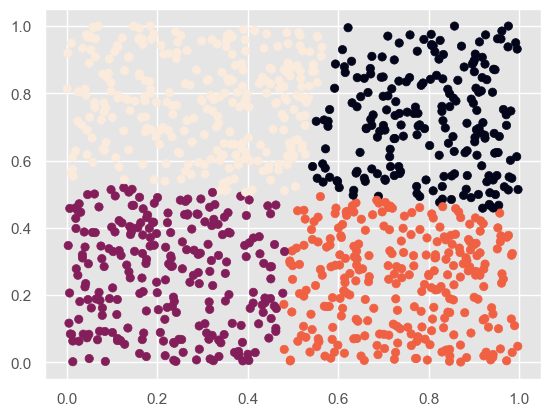
Anh ấy đưa cho tôi khá ít mã, vì vậy tôi đã tìm kiếm các tham số khác của hàm:
- n_clusters: kiểu int, số lượng cụm được tạo ra, mặc định là 8
- max_iter: kiểu int, số lần lặp tối đa để thực thi, mặc định là 300
- n_init: chọn nhiều trung tâm cụm khác nhau và cuối cùng chọn một trung tâm có cùng kết quả chạy
- init: Có ba giá trị tùy chọn
- k-means++: Theo mặc định, một phương pháp đặc biệt được sử dụng để chọn trọng tâm ban đầu và tăng tốc độ hội tụ
- Ngẫu nhiên: Chọn ngẫu nhiên các tâm từ dữ liệu đào tạo
- Truyền ndarray: tự xác định tâm
- n_việc làm
- trạng thái ngẫu nhiên
Các tính chất chính của nó là:
- cluster_centers_: trung tâm cụm cuối cùng
- nhãn: Cụm tương ứng với mỗi mẫu
- inertia_: dùng để đánh giá số lượng cụm có phù hợp không. Khoảng cách càng nhỏ thì phép chia càng tốt. Dùng để chọn số lượng cụm tối ưu.
print("Tâm cụm là:",kmeans.cluster_centers_) print("Đánh giá:",kmeans.inertia_)
Các trung tâm cụm là: [[0,79862048 0,71591318] [0,22582347 0,26005466] [0,73845863 0,23886344] [0,29972473 0,76998545]] Đánh giá: 41,37635968102986
KNN
Để biết phần giới thiệu về thuật toán này, vui lòng xem blog của tôi, trong đó giải thích thuật toán và quy trình triển khai python chi tiết.
Dưới đây chúng tôi tập trung vào quá trình triển khai bằng sklearn.
Mô-đun neighbors của thư viện sklearn triển khai các thuật toán liên quan đến KNN, trong đó:
- Lớp KNeighborsClassifier được sử dụng để triển khai các vấn đề phân loại
- Lớp KNeighborsRegressor được sử dụng để triển khai các bài toán hồi quy (bài toán hồi quy chỉ đơn giản là gán giá trị trung bình của các đặc điểm của các điểm gần đó cho điểm mục tiêu)
Phương pháp xây dựng của hai lớp này về cơ bản là giống nhau. Ở đây chúng tôi chủ yếu giới thiệu lớp KNeighborsClassifier, nguyên mẫu như sau:
KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=Không có, n_jobs=Không có, **kwargs)
Chủ yếu tập trung vào các thông số sau:
- n_neighbors: giá trị K trong KNN, giá trị mặc định thường được sử dụng là 5.
- weights: được sử dụng để xác định trọng số của các hàng xóm. Có ba cách:
- weights=uniform, nghĩa là tất cả các hàng xóm đều có cùng trọng lượng.
- trọng lượng = khoảng cách, nghĩa là trọng lượng là nghịch đảo của khoảng cách, tức là tỷ lệ nghịch với khoảng cách
- Các hàm tùy chỉnh có thể tùy chỉnh trọng số tương ứng với các khoảng cách khác nhau. Nhìn chung, bạn không cần phải xác định các hàm của riêng mình.
- thuật toán: được sử dụng để thiết lập thuật toán tính toán hàng xóm. Có bốn phương pháp:
- algorithm=auto, tự động chọn thuật toán phù hợp dựa trên dữ liệu
- algorithm=kd_tree, sử dụng thuật toán cây KD
- Cây KD phù hợp với những tình huống có ít chiều hơn, thường không quá 20 chiều. Nếu chiều lớn hơn 20, hiệu quả sẽ giảm.
- algorithm=ball_tree, sử dụng thuật toán ball tree
- Cây bóng phù hợp hơn với những tình huống có kích thước lớn hơn
- thuật toán=brute, được gọi là tìm kiếm brute force
- So với cây KD, nó sử dụng quét tuyến tính thay vì xây dựng cấu trúc cây để truy xuất nhanh.
- Nhược điểm là khi tập huấn luyện lớn thì hiệu quả rất thấp
- leaf_size: chỉ ra số lượng nút lá khi xây dựng cây KD hoặc cây bóng. Giá trị mặc định là 30.
Chúng ta hãy cùng tìm hiểu mã thực tế:
từ sklearn.datasets nhập load_digits nhập pandas dưới dạng pd số = load_digits() dữ liệu = số.data # bộ tính năng mục tiêu = số.target # bộ mục tiêu data_pd = pd.DataFrame(dữ liệu) data_pd
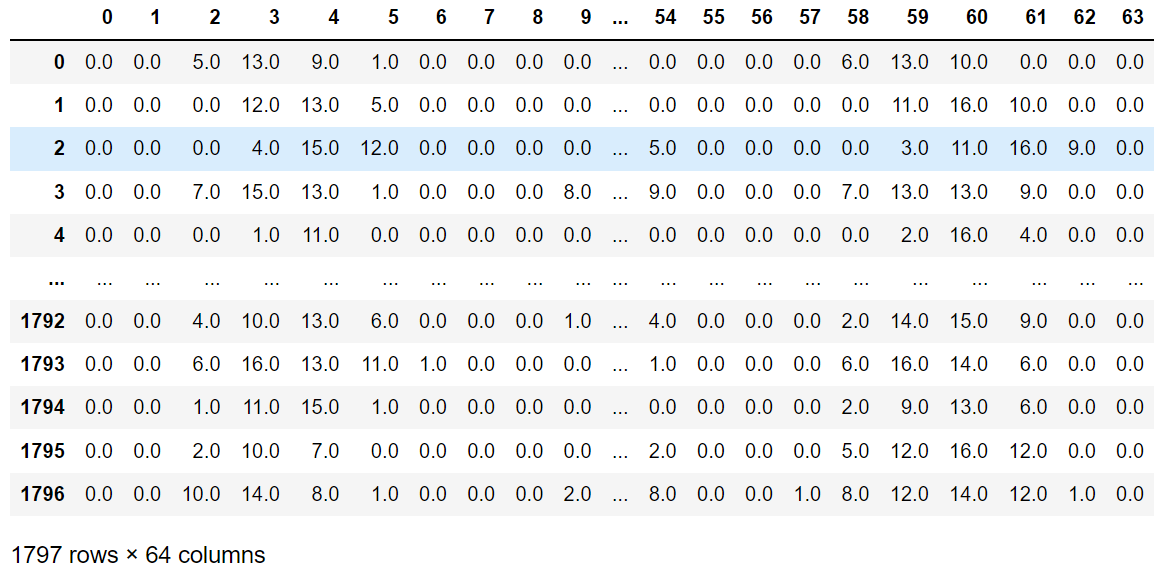
Có thể thấy rằng có 64 chiều, tương đương với một điểm phân tán trong không gian 64 chiều.
từ sklearn.model_selection nhập train_test_split train_x, test_x, train_y, test_y = train_test_split( dữ liệu, mục tiêu, test_size=0.25, random_state=33) từ sklearn.neighbors nhập KNeighborsClassifier knn = KNeighborsClassifier() knn.fit(train_x, train_y) predict_y = knn.predict(test_x) từ sklearn.metrics nhập accuracy_score điểm = accuracy_score(test_y, predict_y) điểm
0,9844444444444445
PCA
Để biết giải thích chi tiết về thuật toán PCA, vui lòng tham khảo blog của tôi, trong đó giải thích về thuật toán PCA và quy trình triển khai PCA trong Numpy.
Tiếp theo, chúng ta tiếp tục tập trung vào quá trình triển khai thuật toán:
# Đầu tiên, chúng ta tạo dữ liệu ngẫu nhiên và trực quan hóa itimport numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D %matplotlib inline from sklearn.datasets import make_blobs # X là đối tượng mẫu, Y là danh mục cụm mẫu, tổng cộng 1000 mẫu, 3 đối tượng cho mỗi mẫu, tổng cộng 4 cụmX, y = make_blobs(n_samples=10000, n_features=3, centers=[[3,3, 3], [0,0,0], [1,1,1], [2,2,2]], cluster_std=[0,2, 0,1, 0,2, 0,2], random_state = 9) fig = plt.figure() ax = Axes3D(fig, rect=[0,0,1,1], elev = 20, azim = 10) # rect là bên trái, bên dưới, chiều rộng, chiều cao, được sử dụng để xác định phạm vi, elev là góc nhìn lên và xuống, azim là góc nhìn trái và phải plt.scatter(X[:,0],X[:,1], X[:,2], marker='o')
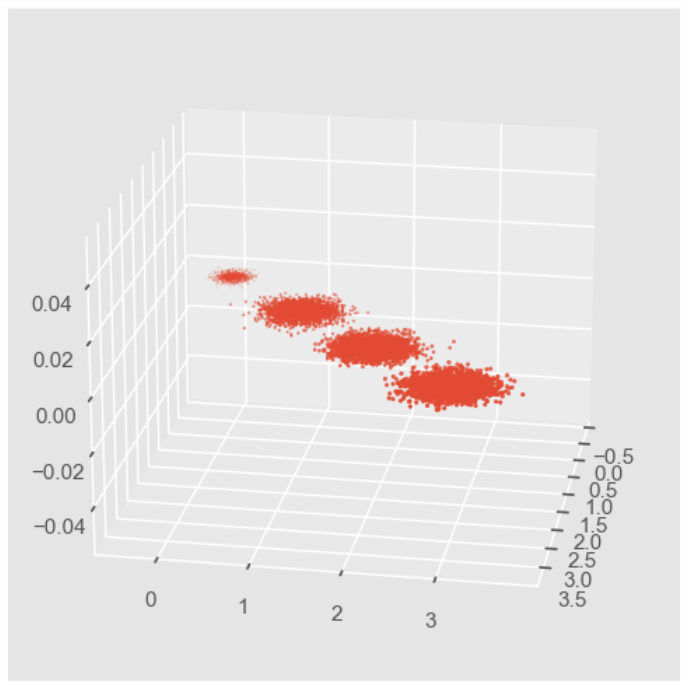
Vì PCA cần tập trung vào phương sai được giữ lại khi giảm chiều, nên chúng ta sẽ không giảm chiều trước mà chỉ chiếu dữ liệu để xem phân phối phương sai của ba chiều sau khi chiếu:
từ sklearn.decomposition nhập PCA pca = PCA(n_components = 3) pca.fit(X) in(pca.explained_variance_ratio_) # Tỷ lệ phần trăm phương sai được giữ lại bởi mỗi tính năng in(pca.explained_variance_) # Giá trị phương sai ban đầu của mỗi tính năng
[0,98318212 0,00850037 0,00831751] [3,78521638 0,03272613 0,03202212]
Có thể thấy rằng phương sai của chiều thứ nhất chiếm tới 98%.
Sau đó chúng ta hãy thử giảm nó xuống còn 2 chiều:
pca = PCA(n_components=2) pca.fit(X) in(pca.explained_variance_ratio_) in(pca.explained_variance_)
[ 0,98318212 0,00850037 ] [ 3,78521638 0,03272613 ]
Có thể thấy rằng nếu giữ lại hai chiều, nó sẽ chọn hai đặc điểm đầu tiên có độ biến thiên lớn hơn và loại bỏ đặc điểm thứ ba.
Chúng ta vẽ hình ảnh sau khi giảm chiều:
X_new = pca.transform(X) plt.scatter(X_new[:, 0], X_new[:, 1], đánh dấu='o') plt.show()
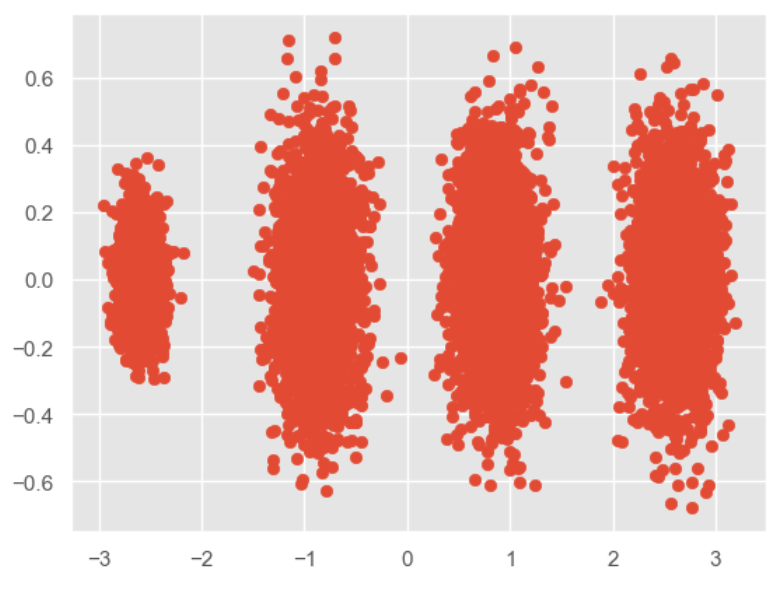
Việc giảm số chiều mà chúng ta vừa thực hiện là để chỉ định số chiều được giữ lại, do đó chúng ta cũng có thể chỉ định kích thước của tỷ lệ phương sai được giữ lại:
pca = PCA(n_components=0.95) pca.fit(X) in(pca.explained_variance_ratio_) in(pca.explained_variance_) in(pca.n_components_)
[0,98318212] [3,78521638] 1
Ta thấy rằng vì chiều thứ nhất chiếm tới 98% nên để giữ lại 95% thì chỉ cần giữ lại chiều thứ nhất.
Chúng ta cũng có thể để thuật toán MLE tự chọn kết quả giảm chiều:
pca = PCA(n_components='mle') pca.fit(X) in(pca.explained_variance_ratio_) in(pca.explained_variance_) in(pca.n_components_)
[0,98318212] [3,78521638] 1
Có thể thấy rằng thuật toán MLE chỉ giữ lại đặc điểm đầu tiên.
Chúng tôi thêm các tham số cụ thể của lớp này vào đây:
- n_components: chỉ định số đặc biệt sau khi giảm chiều hoặc chỉ định tỷ lệ phương sai được giữ lại. Nó cũng có thể được tự động chọn bằng cách đặt thành MLE
- sao chép: Giá trị Boolean, có nên sao chép dữ liệu đào tạo gốc hay không
- whliten: Giá trị Boolean, có nên làm trắng để mỗi tính năng có cùng phương sai hay không
Các thuộc tính của lớp này là:
- n_components_: Trả về số lượng tính năng được giữ lại
- solved_variance_ratio_: Trả về phần trăm phương sai cho mỗi tính năng được giữ lại
- solved_variance_: Trả về phương sai của mỗi tính năng được giữ lại
Các phương pháp phổ biến là:
- fit_transform(X): đào tạo và trả về dữ liệu có chiều giảm
- inverse_transform(newData): Chuyển đổi dữ liệu có chiều giảm newData trở lại dữ liệu gốc, có thể hơi khác một chút
- transform(X): chuyển đổi X thành dữ liệu có kích thước giảm
Cố gắng khôi phục dữ liệu có chiều giảm:
new_Data = pca.transform(X) X_regan = pca.inverse_transform(new_Data) X-X_regan
mảng([[ 0,14364008, -0,1352249 , -0,00781994], [ 0,05135552, -0,01316744, -0,03802959], [-0,03610653, 0,07254754, -0,03665018], ..., [ 0,18537785, -0,0907325 , -0,09400653], [-0,2618617 , 0,20035984, 0,06048799], [-0,02015389, 0,12283753, -0,10292754]])
Vẫn còn một khoảng cách lớn.
Ừm
Để biết thêm về các nguyên tắc của HMM, tôi thực sự khuyên bạn nên xem video này, video này giải thích rất rõ ràng! .
Chúng tôi tiếp tục tập trung vào việc thực hiện chương trình.
Hmmlearn triển khai ba lớp mô hình HMM, có thể được chia thành hai loại tùy theo trạng thái quan sát là liên tục hay rời rạc. GaussianHMM và GMMHMM là các mô hình HMM dành cho trạng thái quan sát liên tục, trong khi MultinomialHMM là mô hình dành cho trạng thái quan sát rời rạc. Vậy chúng ta hãy thử xem nhé:
, 0.0, 0.2, 0.6]]) # Chuẩn bị các tham số cho HMM 4 thành phần # Xác suất dân số ban đầu startprob = np.array([0.6, 0.3, 0.1, 0.0]) # Ma trận chuyển tiếp, lưu ý rằng không có chuyển tiếp nào có thể # giữa thành phần 1 và 3 transmat = np.array([[0.7, 0.2, 0.0, 0.1], [0.3, 0.5, 0.2, 0.0], [0.0, 0.3, 0.5, 0.2], [0.2, 0.0, 0.2, 0.6]]) # Giá trị trung bình của mỗi thành phần means = np.array([[0.0, 0.0], [0.0, 11.0], [9.0, 10.0], () # Xây dựng một thể hiện HMM và thiết lập các tham số gen_model = hmm.GaussianHMM(n_components=4, covariance_type="full") # Thay vì khớp nó từ dữ liệu, chúng ta thiết lập trực tiếp các tham số ước tính, giá trị trung bình và hiệp phương sai của các thành phần gen_model.startprob_ = startprob gen_model.transmat_ = transmat gen_model.means_ = means gen_model.covars_ = covars # Tạo các mẫu X, Z = gen_model.sample(500) # Vẽ dữ liệu được lấy mẫu fig, ax = plt.subplots() ax.plot(X[:, 0], X[:, 1], ".-", label="observations", ms=6, mfc="orange", alpha=0.7) # Chỉ ra số thành phần cho i, m trong enumerate(means): ax.text(m[0], m[1], 'Thành phần %i' % (i + 1), size=17, horizontalalignment='center', bbox=dict(alpha=.7, facecolor='w')) ax.legend(loc='best') fig.show()
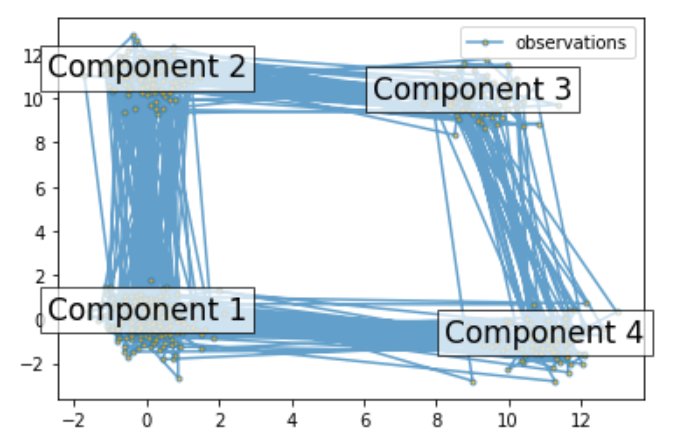
scores = list() models = list() cho n_components trong (3, 4, 5): # định nghĩa mô hình Markov ẩn của chúng ta model = hmm.GaussianHMM(n_components=n_components, covariance_type='full', n_iter=10) model.fit(X[:X.shape[0] // 2]) # 50/50 đào tạo/xác thực models.append(model) scores.append(model.score(X[X.shape[0] // 2:])) print(f'Converged: {model.monitor_.converged}' f'\tScore: {scores[-1]}') # lấy mô hình tốt nhất model = models[np.argmax(scores)] n_states = model.n_components print(f'Mô hình tốt nhất có điểm là {max(scores)} và {n_states} ' 'states') # sử dụng Thuật toán Viterbi để dự đoán chuỗi trạng thái có khả năng xảy ra nhất # với mô hình states = model.predict(X)
Hội tụ: Điểm thực: -1065.5259488089373 Hội tụ: Điểm thực: -904.2908933008515 Hội tụ: Điểm thực: -905.5449538166446 Mô hình tốt nhất có điểm là -904.2908933008515 và 4 trạng thái
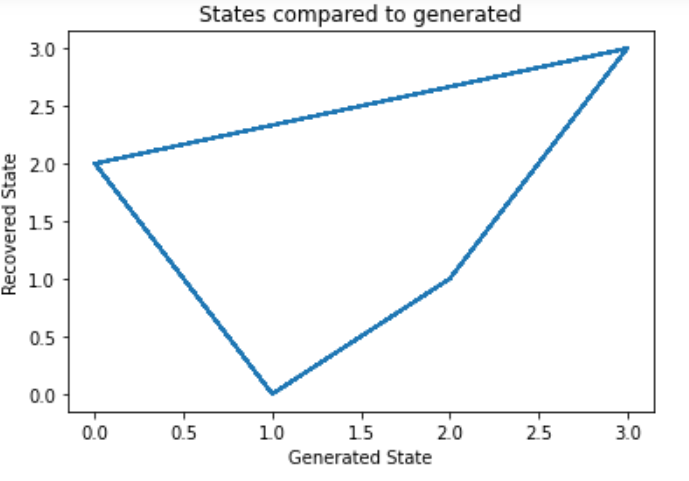
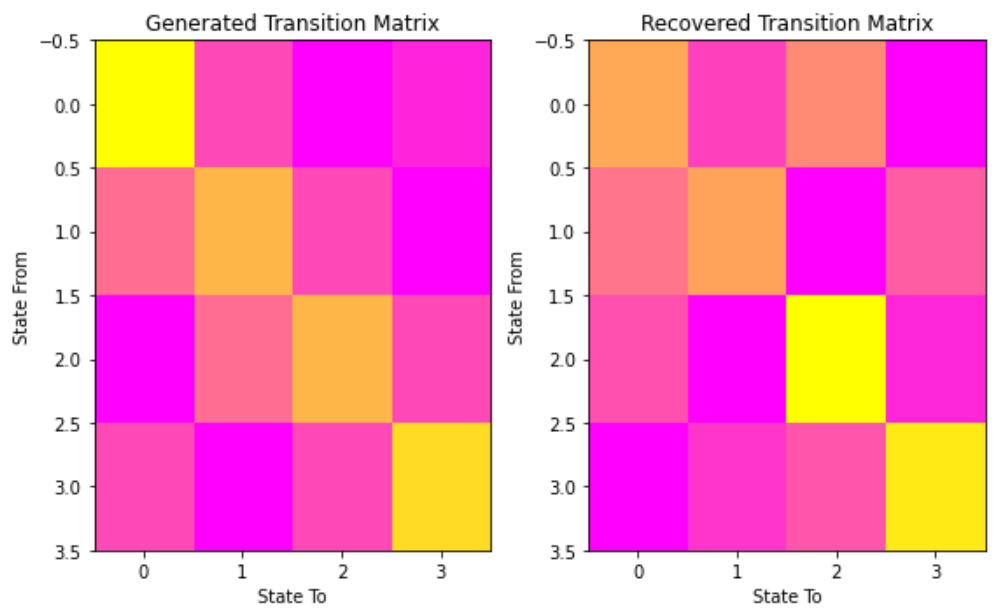
# Hãy so sánh các trạng thái của chúng ta với các trạng thái được tạo ra và ma trận chuyển đổi của chúng ta để xem mô hình của chúng ta # vẽ các trạng thái mô hình theo thời gian fig, ax = plt.subplots() ax.plot(Z, states) ax.set_title('So sánh các trạng thái với trạng thái được tạo ra') ax.set_xlabel('Trạng thái được tạo ra') ax.set_ylabel('Trạng thái được phục hồi') fig.show() # vẽ ma trận chuyển đổi fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 5)) ax1.imshow(gen_model.transmat_, aspect='auto', cmap='spring') ax1.set_title('Ma trận chuyển đổi được tạo ra') ax2.imshow(model.transmat_, aspect='auto', cmap='spring') ax2.set_title('Ma trận chuyển đổi được phục hồi') for ax in (ax1, ax2): ax.set_xlabel('Trạng thái đến') ax.set_ylabel('Trạng thái từ') fig.tight_layout() fig.show()
báo cáo trực quan
Chương này chủ yếu giải thích phần trực quan hóa của máy học, được triển khai bằng Scikit-Plot. Chương này chủ yếu bao gồm các phần sau:
- ước lượng: được sử dụng để vẽ các thuật toán khác nhau
- Số liệu: được sử dụng để vẽ ma trận máy học onfusion, đường cong ROC AUC, đường cong độ chính xác-thu hồi, v.v.
- cụm: Chủ yếu được sử dụng để vẽ cụm
- phân tích: Chủ yếu được sử dụng để vẽ giảm chiều PCA
Đầu tiên hãy tải các mô-đun cần thiết:
# Tải các mô-đun bạn cần import scikitplot as skplt import sklearn from sklearn.datasets import load_digits, load_boston, load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor, GradientBoostingClassifier, ExtraTreesClassifier from sklearn.linear_model import LinearRegression, LogisticRegression from sklearn.cluster import KMeans from sklearn.decomposition import PCA import matplotlib.pyplot as plt import sys print("Phiên bản biểu đồ Scikit: ", skplt.__version__) print("Phiên bản Scikit Learn: ", sklearn.__version__) print("Phiên bản Python: ", sys.version)
Nếu thư viện skplt chưa được cài đặt, bạn có thể trực tiếp:
pip cài đặt scikit-plot
Đang tải tập dữ liệu
Bộ dữ liệu chữ viết tay
digit = load_digits() X_digits, Y_digits = digit.data, digit.target print("Kích thước tập dữ liệu chữ số: ", X_digits.shape, Y_digits.shape) X_digits_train, X_digits_test, Y_digits_train, Y_digits_test = train_test_split(X_digits, Y_digits, train_size=0.8, stratify=Y_digits, random_state=1) print("Kích thước tập dữ liệu chữ số: ", X_digits_train.shape, X_digits_test.shape, Y_digits_train.shape, Y_digits_test.shape)
Kích thước tập dữ liệu chữ số: (1797, 64) (1797,) Kích thước đào tạo/kiểm tra chữ số: (1437, 64) (360, 64) (1437,) (360,)
Bộ dữ liệu khối u
cancer = load_breast_cancer() X_cancer, Y_cancer = cancer.data, cancer.target print("Tên tính năng: ", cancer.feature_names) print("Kích thước tập dữ liệu ung thư: ", X_cancer.shape, Y_cancer.shape) X_cancer_train, X_cancer_test, Y_cancer_train, Y_cancer_test = train_test_split(X_cancer, Y_cancer, train_size=0.8, stratify=Y_cancer, random_state=1) print("Kích thước tập huấn luyện/kiểm tra ung thư: ", X_cancer_train.shape, X_cancer_test.shape, Y_cancer_train.shape, Y_cancer_test.shape)
Tên tính năng: ['bán kính trung bình' 'kết cấu trung bình' 'chu vi trung bình' 'diện tích trung bình' 'độ mịn trung bình' 'độ nén trung bình' 'độ lõm trung bình' 'điểm lõm trung bình' 'đối xứng trung bình' 'chiều fractal trung bình' 'lỗi bán kính' 'lỗi kết cấu' 'lỗi chu vi' 'lỗi diện tích' 'lỗi độ mịn' 'lỗi độ nén' 'lỗ lõm' 'lỗi điểm lõm' 'lỗi đối xứng' 'lỗi kích thước fractal' 'bán kính tệ nhất' 'kết cấu tệ nhất' 'chu vi tệ nhất' 'diện tích tệ nhất' 'độ mịn tệ nhất' 'độ nén tệ nhất' 'độ lõm tệ nhất' 'điểm lõm tệ nhất' 'đối xứng tệ nhất' 'chiều fractal tệ nhất'] Kích thước tập dữ liệu ung thư: (569, 30) (569,) Ung thư Kích thước đào tạo/kiểm tra: (455, 30) (114, 30) (455,) (114,)
Bộ dữ liệu giá nhà ở Boston
boston = load_boston() X_boston, Y_boston = boston.data, boston.target print("Kích thước tập dữ liệu Boston: ", X_boston.shape, Y_boston.shape) print("Các tính năng của tập dữ liệu Boston: ", boston.feature_names) X_boston_train, X_boston_test, Y_boston_train, Y_boston_test = train_test_split(X_boston, Y_boston, train_size=0.8, random_state=1) print("Kích thước tập luyện/kiểm tra Boston: ", X_boston_train.shape, X_boston_test.shape, Y_boston_train.shape, Y_boston_test.shape)
Kích thước tập dữ liệu Boston: (506, 13) (506,) Các tính năng của tập dữ liệu Boston: ['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO' 'B' 'LSTAT'] Kích thước đào tạo/kiểm tra Boston: (404, 13) (102, 13) (404,) (102,)
Hình ảnh hiệu suất
Biểu đồ xác thực chéo
Chúng tôi vẽ đường cong học tập xác thực chéo cho hồi quy logistic:
skplt.estimators.plot_learning_curve(LogisticRegression(), X_digits, Y_digits, cv=7, shuffle=True, scoring="accuracy", n_jobs=-1, figsize=(6,4), title_fontsize="large", text_fontsize="large", title="Đường cong học phân loại chữ số") plt.show() skplt.estimators.plot_learning_curve(LinearRegression(), X_boston, Y_boston, cv=7, shuffle=True, scoring="r2", n_jobs=-1, figsize=(6,4), title_fontsize="large", text_fontsize="large", title="Đường cong học hồi quy Boston "); plt.show()
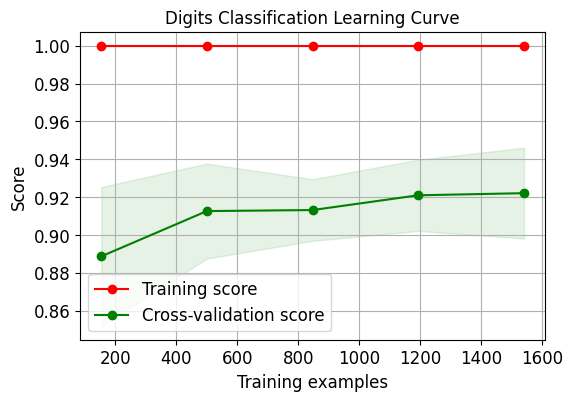
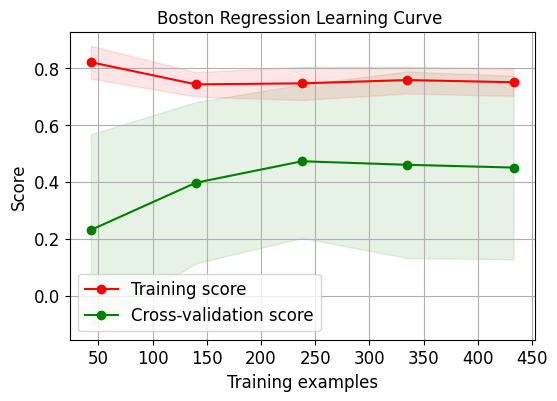
Cần lưu ý rằng vì số liệu đánh giá trên tập dữ liệu thứ hai sử dụng r2 nên điểm của nó hơi khác so với điểm đầu tiên.
Biểu đồ tính năng quan trọng
Tính năng tốt có những đặc điểm sau:
- Nó có tính phân biệt và không trùng lặp với các tính năng khác.
- Các tính năng độc lập với nhau
- Đơn giản và dễ hiểu
Do đó, bản vẽ đặc điểm quan trọng cho phép chúng ta trực quan thấy đặc điểm nào được chức năng coi là tốt hơn và quan trọng hơn.
rf_reg = RandomForestRegressor() # Rừng ngẫu nhiên rf_reg.fit(X_boston_train, Y_boston_train) print(rf_reg.score(X_boston_test, Y_boston_test)) gb_classif = GradientBoostingClassifier() # Tăng cường độ dốc gb_classif.fit(X_cancer_train, Y_cancer_train) print(gb_classif.score(X_cancer_test, Y_cancer_test)) fig = plt.figure(figsize=(15,6)) ax1 = fig.add_subplot(121) # Hai hình ảnh, bây giờ ax1 có thể được vẽ trên hình ảnh đầu tiên skplt.estimators.plot_feature_importances(rf_reg, feature_names=boston.feature_names, title = "Mức độ quan trọng của tính năng hồi quy rừng ngẫu nhiên", x_tick_rotation = 90, order="ascending", ax=ax1) # x_tick_rotation xoay văn bản trên trục x 90° ax2 = fig.add_subplot(122) skplt.estimators.plot_feature_importances(gb_classif, feature_names=cancer.feature_names, title="Mức độ quan trọng của tính năng phân loại tăng cường độ dốc", x_tick_rotation=90, ax=ax2); plt.tight_layout() # Các tham số đồ thị con sẽ được tự động điều chỉnh để lấp đầy toàn bộ vùng ảnh plt.show()
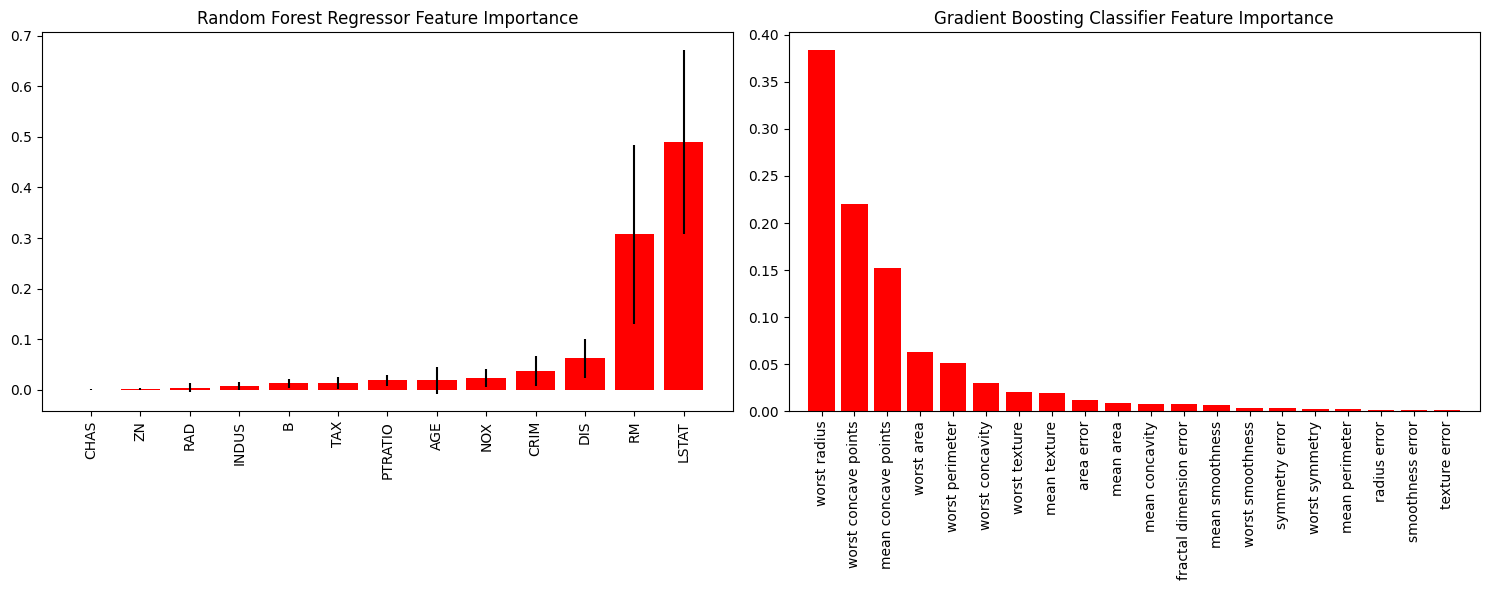
Số liệu học máy
Ma trận nhầm lẫn
Đối với phân loại thứ hai, ma trận nhầm lẫn được hiểu đơn giản như sau:
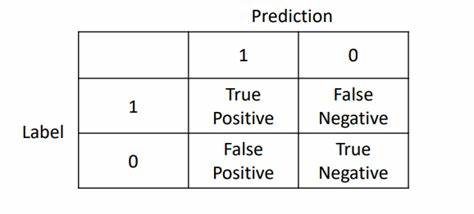
Sau đó, chúng ta thường sử dụng nó để tính độ chính xác và độ thu hồi, đồng thời tính điểm F1. Đối với phân loại đa dạng, nó tương đương với việc mở rộng chiều của ma trận vuông.
s = logisticRegress () log_reg = logisticRegress () log_reg.fit (x_digits_train, y_digits_train) log_reg.score (x_digits_test, y_digits_test) D_subplot (1,2,1) skplt.metrics.plot_confusion_matrix (y_digits_test, y_test_pred, title = "Ma trận nhầm lẫn", cmap = " EST_PRED, bình thường hóa = true, # tương đương với hạn chế với điểm số tiêu đề = "Ma trận nhầm lẫn", CMAP = "Purples", AX = AX =
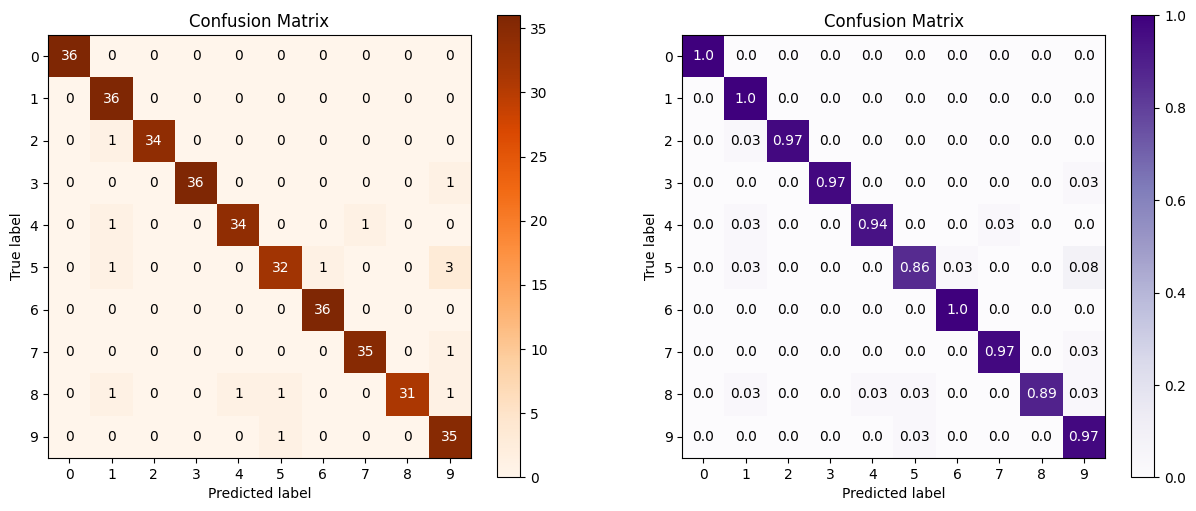
Hình ảnh thứ hai thêm normalize=True, tương đương với việc nén nó theo tỷ lệ 1.
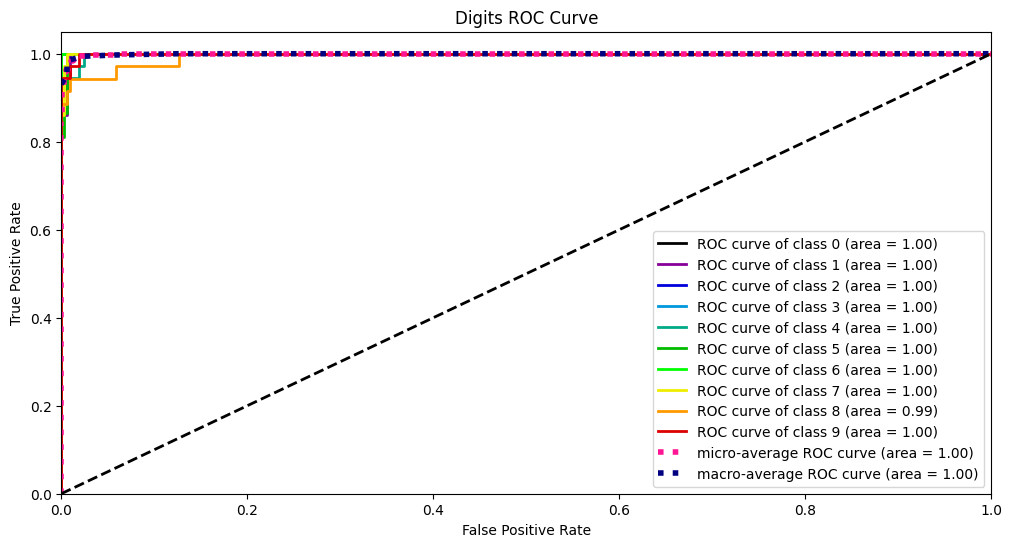
Đường cong ROC và AUC
Để hiểu đường cong ROC, chúng ta bắt đầu với ma trận nhầm lẫn:
TRONG:
- TP: dự đoán là 1, đúng là 1, tỷ lệ dương tính thực sự
- FP: Dự đoán là 1, thực tế là 0, tỷ lệ dương tính giả
- TN: dự đoán là 0, thực tế là 0, tỷ lệ âm tính thực sự
- FN: dự đoán là 0, đúng là 1, tỷ lệ âm tính giả
Khi đó, tổng số ví dụ dương tính thực trong mẫu là TP+FN và tỷ lệ các lớp dương tính được dự đoán chính xác so với tất cả các lớp dương tính là:
\[TPR=\frac{TP}{TP+FN} \]
Tương tự như vậy, phản ví dụ thực sự là FP+TN, khi đó tỷ lệ phản ví dụ dự đoán sai so với tất cả các phản ví dụ là:
\[FPR=\frac{FP}{TN+FP} \]
Một khái niệm khác là điểm cắt t, có nghĩa là khi xác suất dự đoán của mô hình đối với một mẫu lớn hơn t, thì mẫu đó được phân loại là lớp dương, nếu không thì mẫu đó được phân loại là lớp âm.
Sau đó, đường cong ROC là đường cong hai chiều được vẽ từ kết quả của TPR và FPR cho một tập dữ liệu khi điểm cắt t có các giá trị khác nhau.
Đường cong AUC là diện tích của đường cong ROC.
Y_test_probs = log_reg.predict_proba(X_digits_test) skplt.metrics.plot_roc_curve(Y_digits_test, Y_test_probs, title="Đường cong ROC chữ số", figsize=(12,6)) plt.show()
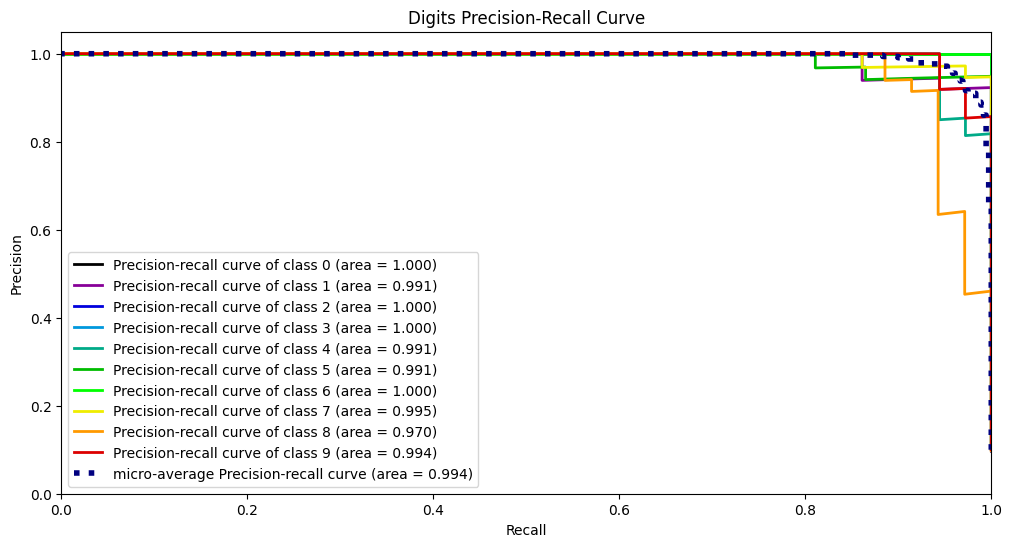
Đường cong PR
Phương pháp vẽ đường cong PR giống như phương pháp vẽ đường cong ROC. Hai chỉ số được chọn là độ chính xác và độ thu hồi:
\[độ chính xác = \frac{TP}{TP+FP}\\ thu hồi = \frac{TP}{TP+FN} \]
Sau đó chọn các điểm cắt khác nhau để vẽ các giá trị.
skplt.metrics.plot_precision_recall_curve(Y_digits_test, Y_test_probs, title="Đường cong thu hồi-độ chính xác của chữ số", figsize=(12,6)) plt.show()
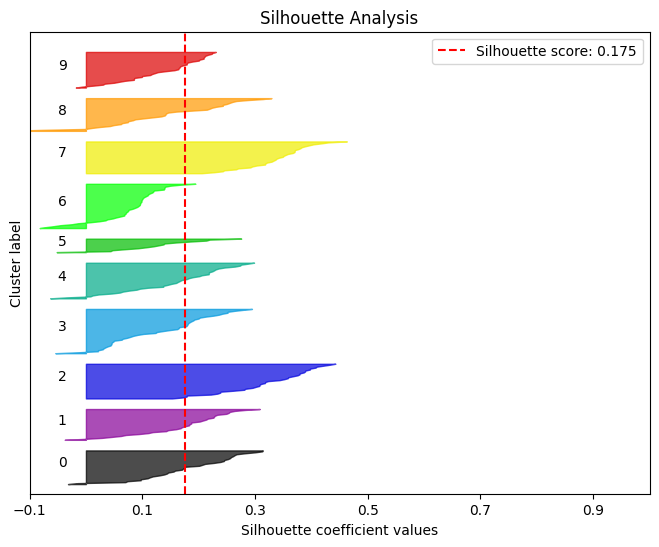
Phân tích hồ sơ
Hiểu một cách đơn giản rằng phân tích hồ sơ được sử dụng để đánh giá chất lượng của hiệu ứng cụm.
kmeans = KMeans(n_clusters=10, random_state=1) kmeans.fit(X_digits_train, Y_digits_train) cluster_labels = kmeans.predict(X_digits_test) skplt.metrics.plot_silhouette(X_digits_test, cluster_labels,figsize=(8,6)) plt.show()
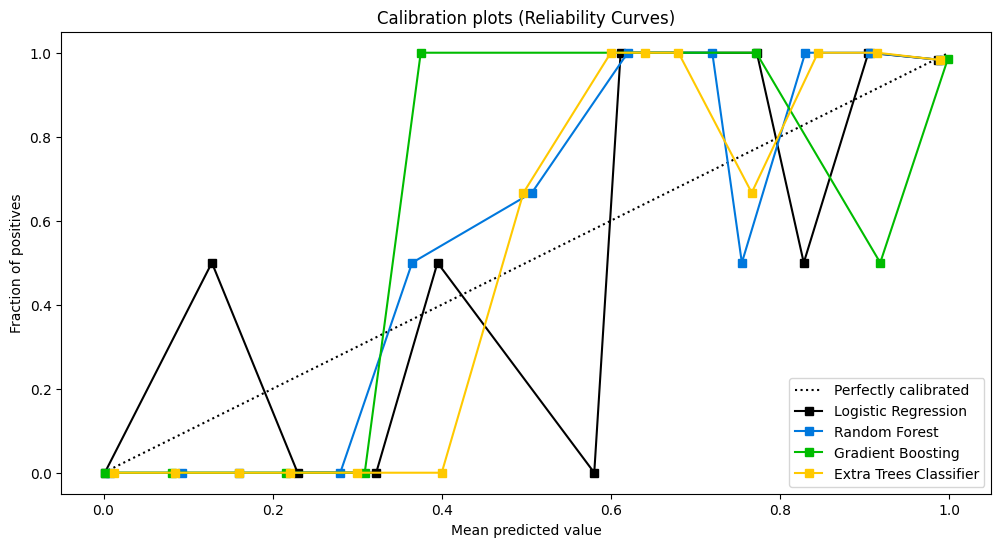
Đường cong độ tin cậy
Kiểm tra độ tin cậy của mô hình xác suất.
] clf_names = ['Hồi quy logistic', 'Rừng ngẫu nhiên', 'Tăng cường độ dốc', 'Phân loại cây bổ sung'] skplt.metrics.plot_calibration_curve(Y_cancer_test, probas_list, clf_names, n_bins=15, figsize=(12,6) ) plt.show()
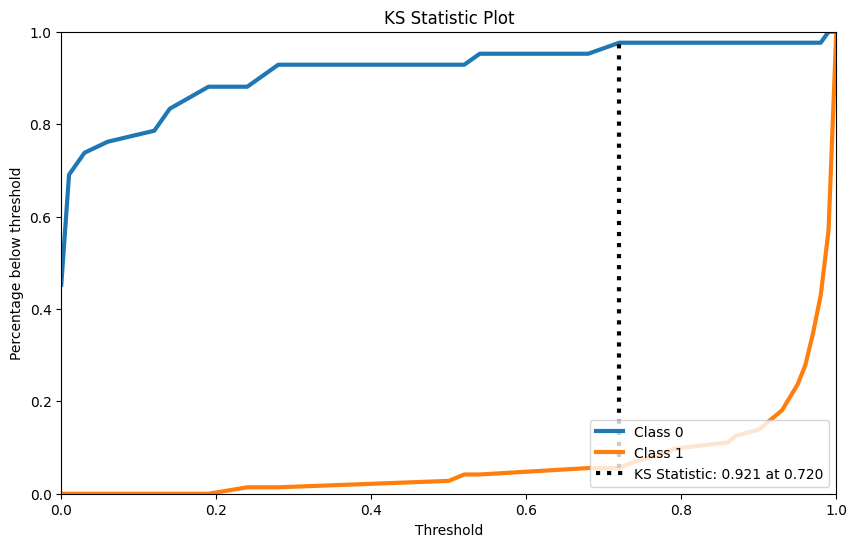
Bài kiểm tra KS
Kiểm định KS được sử dụng để kiểm tra xem hai mẫu có tuân theo cùng một phân phối hay không.
rf = RandomForestClassifier() rf.fit(X_cancer_train, Y_cancer_train) Y_cancer_probas = rf.predict_proba(X_cancer_test) skplt.metrics.plot_ks_statistic(Y_cancer_test, Y_cancer_probas, figsize=(10,6)) plt.show()
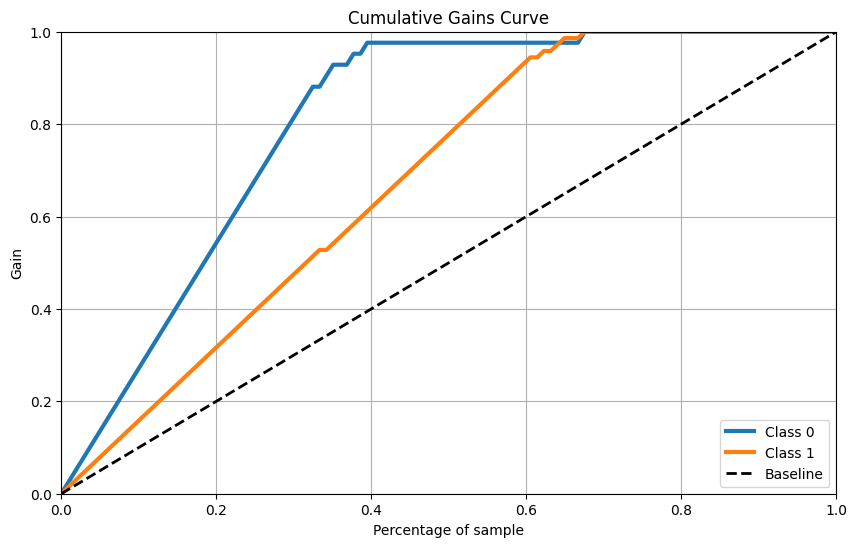
Đường cong lợi nhuận tích lũy
skplt.metrics.plot_cumulative_gain(Y_cancer_test, Y_cancer_probas, figsize=(10,6)) plt.show()
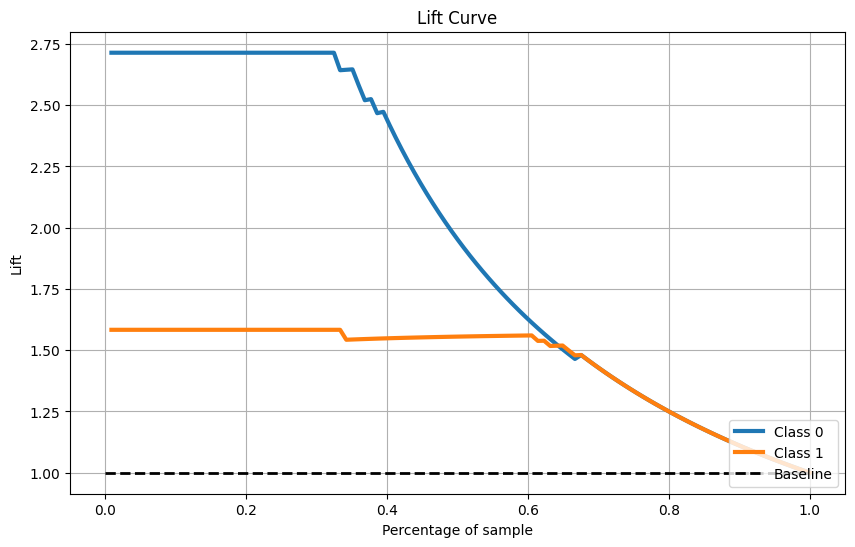
Đường cong nâng
skplt.metrics.plot_lift_curve(Y_cancer_test, Y_cancer_probas, figsize=(10,6)) plt.show()
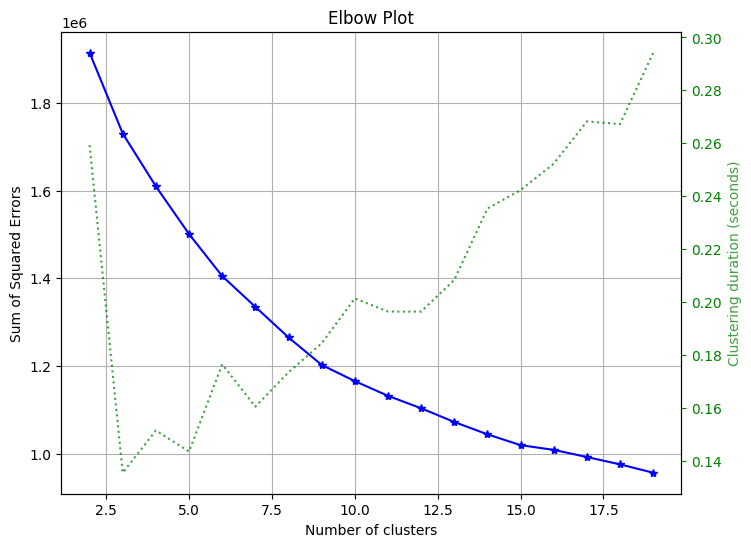
Phương pháp phân cụm
Phương pháp khuỷu tay
Được sử dụng để chọn số cụm cần được chọn để phân cụm.
skplt.cluster.plot_elbow_curve(KMeans(random_state=1), X_digits, cluster_ranges=range(2, 20), figsize=(8,6)) plt.show()
Phương pháp giảm chiều
PCA
Bạn có thể xem tỷ lệ phương sai của n thành phần chính đầu tiên của PCA:
pca = PCA(random_state=1) pca.fit(X_digits) skplt.decomposition.plot_pca_component_variance(pca, figsize=(8,6)) plt.show()
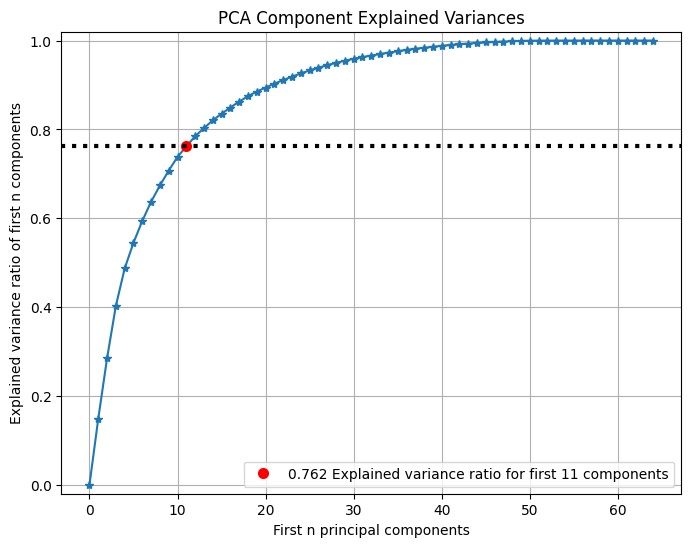
Phép chiếu 2 chiều
Chiếu 2D:
skplt.decomposition.plot_pca_2d_projection(pca, X_digits, Y_digits, figsize=(10,10), cmap="tab10") plt.show()
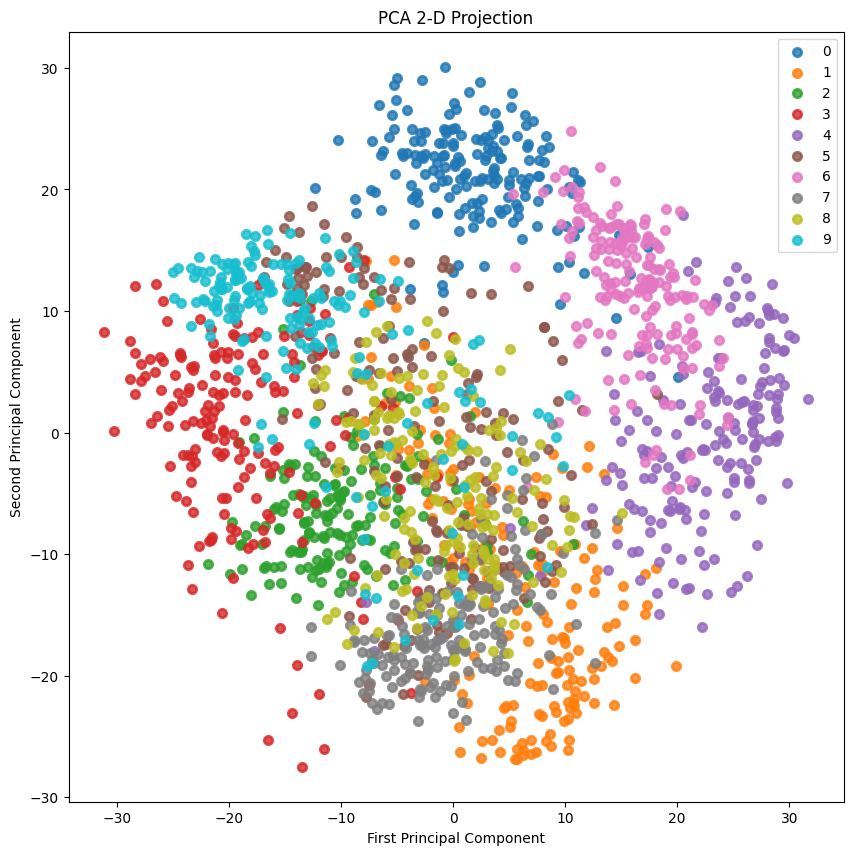
Cuối cùng, bài viết này về thực hành thực tế của mã học máy dựa trên Sklearn ở đây. Nếu bạn muốn biết thêm về thực hành thực tế của mã học máy dựa trên Sklearn, vui lòng tìm kiếm các bài viết CFSDN hoặc tiếp tục duyệt các bài viết liên quan. Tôi hy vọng bạn sẽ ủng hộ blog của tôi trong tương lai! .

 Trung tâm cá nhân
Trung tâm cá nhân Bài viết phát hành
Bài viết phát hành



 4
4



Tôi là một lập trình viên xuất sắc, rất giỏi!