1 Giới thiệu
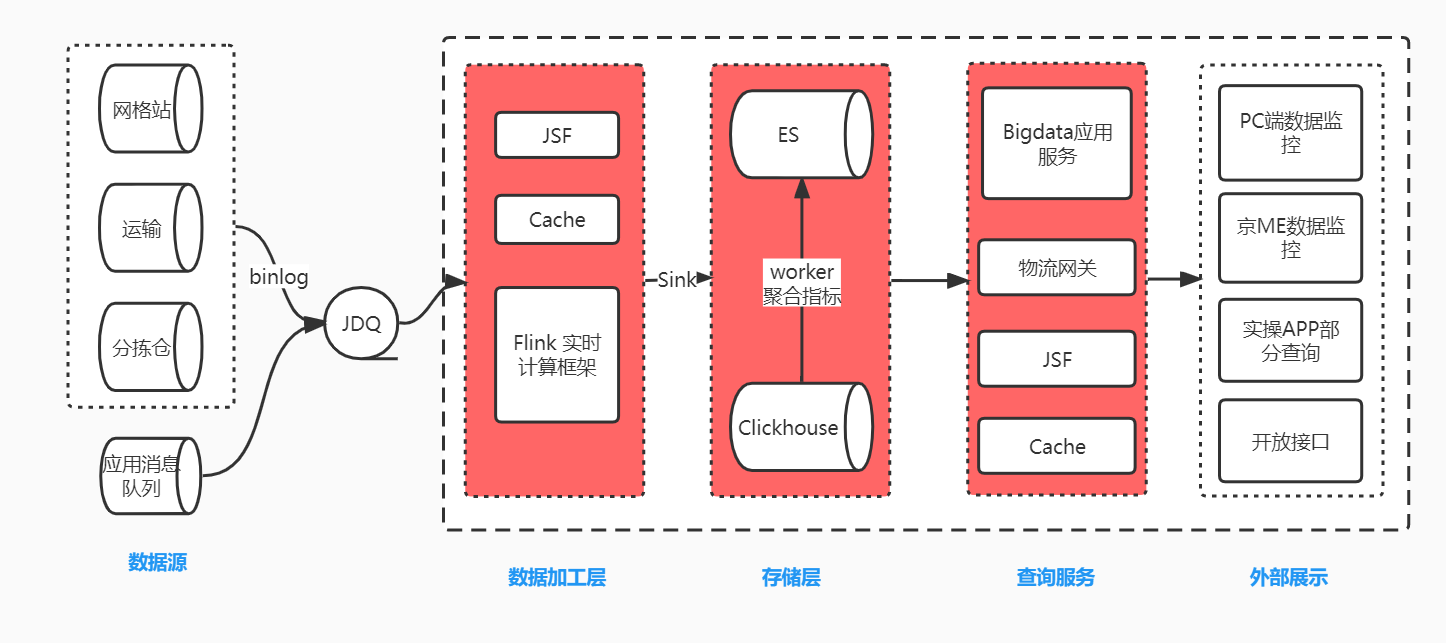
Bộ phận công nghệ Jingxida sử dụng kiến trúc JDQ+Flink+Elasticsearch để tạo báo cáo dữ liệu thời gian thực trong các tình huống mua hàng theo nhóm cộng đồng. Khi doanh nghiệp phát triển, Elasticsearch bắt đầu bộc lộ một số nhược điểm. Nó không phù hợp với các truy vấn dữ liệu quy mô lớn. Xuất phân trang sâu tần suất cao dẫn đến thời gian chết của ES và không thể loại bỏ trùng lặp số liệu thống kê một cách chính xác. Hiệu suất của nhiều trường bị giảm đáng kể khi thực hiện các phép tính tổng hợp. Vì vậy ClickHouse được ra đời để giải quyết những nhược điểm này.
Liên kết ghi dữ liệu là nơi dữ liệu kinh doanh (binlog) được xử lý và chuyển đổi thành tin nhắn MQ định dạng cố định. Flink đăng ký các Chủ đề khác nhau để nhận dữ liệu bảng từ các hệ thống sản xuất khác nhau, thực hiện liên kết, tính toán, lọc và bổ sung dữ liệu cơ bản và tổng hợp chúng thành các bảng rộng. Cuối cùng, luồng dữ liệu DataStream đã xử lý được ghi vào cả ES và ClickHouse. Dịch vụ truy vấn được tiếp xúc với thế giới bên ngoài thông qua JSF và cổng hậu cần để hiển thị bên ngoài. Vì ClickHouse sử dụng toàn bộ sức mạnh tính toán trên một truy vấn nên không tốt cho các truy vấn đồng thời cao. Chúng tôi thêm bộ nhớ đệm vào một số giao diện chỉ báo tổng hợp thời gian thực hoặc truy vấn các chỉ báo tính toán ClickHosue cho các tác vụ đã lên lịch và lưu trữ chúng trong ES. Một số chỉ báo không còn truy vấn ClickHouse theo thời gian thực nữa mà truy vấn các chỉ báo được tính toán trong ES để chống lại sự đồng thời. Phương pháp này có thể cải thiện đáng kể hiệu quả phát triển, dễ bảo trì và có thể thống nhất cỡ của các chỉ báo.
Trong quá trình giới thiệu ClickHouse, tôi đã gặp phải nhiều khó khăn khác nhau và đã dành nhiều năng lượng để khám phá và giải quyết từng cái một. Tôi ghi lại chúng ở đây với hy vọng rằng chúng có thể cung cấp một số hướng dẫn định hướng cho những sinh viên chưa tiếp xúc với ClickHouse để tránh đi lạc hướng. Nếu có lỗi trong bài viết, tôi hy vọng sẽ đưa thêm hướng dẫn. Mọi người đều được chào đón để thảo luận các chủ đề liên quan đến ClickHouse. Bài viết này dài nhưng đầy đủ thông tin hữu ích. Vui lòng dành 40 đến 60 phút để đọc.
2 Vấn đề gặp phải
Như đã đề cập ở trên, chúng tôi gặp phải nhiều khó khăn. Các vấn đề sau đây là trọng tâm của bài viết này.
- Chúng ta nên sử dụng công cụ bảng nào?
- Cách viết thư cho ClickHouse trong Flink
- Tại sao truy vấn ClickHouse lại chậm hơn 1-2 phút so với truy vấn ES?
- Viết vào một bảng phân tán hoặc một bảng cục bộ
- Tại sao mức sử dụng CPU của chỉ một phân đoạn lại cao?
- Làm thế nào để xác định SQL nào đang sử dụng CPU? Làm thế nào tôi có thể biết SQL nào đang gây ra nhiều SQL chậm như vậy?
- Tìm thấy SQL chậm, cách tối ưu hóa nó
- Làm thế nào để chịu được mức độ đồng thời cao và đảm bảo tính khả dụng của ClickHouse
3 Giải pháp lựa chọn và truy vấn công cụ bảng
Trước khi chọn công cụ tạo bảng và giải pháp truy vấn, hãy làm rõ yêu cầu của bạn. Như đã đề cập trong phần giới thiệu, chúng tôi xây dựng các bảng rộng trong Flink, bao gồm các hoạt động cập nhật dữ liệu trong doanh nghiệp và cùng một số đơn đặt hàng của doanh nghiệp sẽ được ghi vào cơ sở dữ liệu nhiều lần. Upsert của ES hỗ trợ các hoạt động yêu cầu ghi đè dữ liệu trước đó. ClickHouse không có upsert, vì vậy cần phải khám phá giải pháp có thể hỗ trợ upsert. Với yêu cầu này, chúng ta hãy cùng xem xét công cụ tạo bảng và giải pháp truy vấn của ClickHouse.
ClickHouse có nhiều công cụ bảng, xác định cách dữ liệu được lưu trữ, cách dữ liệu được tải và các đặc điểm của bảng dữ liệu. Hiện tại, công cụ bảng ClickHouse được chia thành bốn dòng: Log, MergeTree, Integration và Special.
- Chuỗi nhật ký: Phù hợp với các tình huống có lượng dữ liệu nhỏ (ít hơn một triệu hàng). Nó không hỗ trợ chỉ mục, do đó không hiệu quả cho các truy vấn phạm vi.
- Chuỗi tích hợp: chủ yếu dùng để import dữ liệu ngoài vào ClickHouse, hoặc trực tiếp vận hành dữ liệu ngoài trong ClickHouse, hỗ trợ Kafka, HDFS, JDBC, Mysql, v.v.
- Dòng đặc biệt: Ví dụ: Bộ nhớ lưu trữ dữ liệu trong bộ nhớ, dữ liệu sẽ bị mất sau khi khởi động lại và hiệu suất truy vấn tuyệt vời; Tệp lưu trữ trực tiếp các tệp cục bộ dưới dạng dữ liệu, v.v. Hầu hết chúng đều được tùy chỉnh cho các tình huống cụ thể.
- Dòng MergeTree: Bản thân họ MergeTree có nhiều biến thể engine. MergeTree, là engine cơ bản nhất trong họ, cung cấp khả năng lập chỉ mục khóa chính, phân vùng dữ liệu, sao chép dữ liệu, lấy mẫu dữ liệu và các khả năng khác, đồng thời hỗ trợ ghi dữ liệu với lượng cực lớn. Các engine khác trong họ có thế mạnh riêng dựa trên engine MergeTree.
Log, Special và Integration chủ yếu được sử dụng cho các mục đích đặc biệt và các kịch bản tương đối hạn chế. Trong số đó, MergeTree và các công cụ bảng gia đình của nó phản ánh tốt nhất các đặc điểm hiệu suất của ClickHouse. Chúng cũng là các công cụ lưu trữ chính thức hỗ trợ hầu hết các chức năng cốt lõi của ClickHouse và được sử dụng trong hầu hết các tình huống trong môi trường sản xuất. Doanh nghiệp của chúng tôi cũng không ngoại lệ và cần sử dụng các chỉ mục khóa chính. Lượng dữ liệu tăng thêm hàng ngày là hơn 25 triệu, vì vậy chuỗi MergeTree là mục tiêu chúng tôi cần khám phá.
Chuỗi công cụ bảng MergeTree được thiết kế để chèn một lượng lớn dữ liệu. Dữ liệu được ghi nhanh theo từng phần dưới dạng các đoạn dữ liệu. Để tránh quá nhiều đoạn dữ liệu, ClickHouse sẽ hợp nhất chúng thành các đoạn mới theo một số quy tắc nhất định trong nền. So với việc liên tục sửa đổi dữ liệu đã lưu trữ trên đĩa trong quá trình chèn, chiến lược hợp nhất sau khi chèn này hiệu quả hơn nhiều. Tính năng hợp nhất lặp lại các đoạn dữ liệu này cũng là nguồn gốc tên gọi của chuỗi MergeTree. Để tránh việc hình thành quá nhiều phân đoạn dữ liệu, cần phải ghi theo đợt. Chuỗi MergeTree bao gồm các công cụ MergeTree, ReplacingMergeTree, CollapsingMergeTree, VersionedCollapsingMergeTree, SummingMergeTree và AggregatingMergeTree. Các công cụ này được giới thiệu bên dưới.
3.1 MergeTree: Cây hợp nhất
MergeTree hỗ trợ tất cả cú pháp SQL của ClickHouse. Hầu hết các hàm đều tương tự như MySQL quen thuộc, nhưng một số hàm khá khác biệt, chẳng hạn như khóa chính. Khóa chính của chuỗi MergeTree không được sử dụng để loại bỏ trùng lặp. Trong MySQL, không thể có hai dữ liệu có cùng khóa chính trong một bảng, nhưng có thể thực hiện được trong ClickHouse.
Trong câu lệnh tạo bảng sau, số đơn hàng, số lượng sản phẩm, thời gian tạo và thời gian cập nhật được xác định. Dữ liệu được phân vùng theo thời gian tạo, orderNo được sử dụng làm khóa chính và orderNo cũng được sử dụng làm khóa sắp xếp (sắp xếp theo). Theo mặc định, khóa chính và khóa sắp xếp là giống nhau. Trong hầu hết các trường hợp, không cần chỉ định khóa chính. Trong ví dụ này, khóa chính chỉ được chỉ định để minh họa mối quan hệ giữa khóa chính và khóa sắp xếp. Tất nhiên, khóa sắp xếp có thể khác với trường khóa chính, nhưng khóa chính phải là tập hợp con của khóa sắp xếp. Ví dụ, nếu khóa chính là (a, b), khóa sắp xếp phải là (a, b, , ), và các trường tạo nên khóa chính phải nằm ở bên trái của trường khóa sắp xếp.
TẠO BẢNG test_MergeTree (orderNo String, number Int16, createTime DateTime, updateTime DateTime) ENGINE = MergeTree() PHÂN VÙNG THEO createTime THỨ TỰ THEO (orderNo) KHÓA CHÍNH (orderNo); chèn vào test_MergeTree values('1', '20', '2021-01-01 00:00:00', '2021-01-01 00:00:00'); chèn vào test_MergeTree values('1', '30', '2021-01-01 00:00:00', '2021-01-01 01:00:00');
Lưu ý rằng hai dữ liệu được viết ở đây có khóa chính orderNo là 1. Trong trường hợp này, trước tiên chúng ta tạo một đơn hàng, sau đó cập nhật số lượng đơn hàng thành 30 và thời gian cập nhật. Lúc này, số lượng đơn hàng thực tế là 1 và số lượng hàng hóa là 30.
Việc chèn dữ liệu có cùng khóa chính sẽ không gây ra xung đột và việc truy vấn dữ liệu sẽ hiển thị rằng cả hai dữ liệu có cùng khóa chính đều tồn tại. Hình sau đây cho thấy kết quả truy vấn. Vì mỗi lần chèn sẽ tạo thành một phần, lần chèn đầu tiên tạo tệp phân vùng dữ liệu 1609430400_1_1_0 và lần chèn thứ hai tạo tệp phân vùng dữ liệu 1609430400_2_2_0. Nền chưa kích hoạt hợp nhất, do đó kết quả hiển thị trên clickhouse-client được tách thành hai bảng (các công cụ truy vấn đồ họa DBeaver và DataGrip không thể thấy rằng có hai bảng. Bạn có thể sử dụng docker để xây dựng môi trường ClickHouse và thực thi các câu lệnh thông qua máy khách. Có một tài liệu về cách xây dựng môi trường CK ở cuối bài viết).
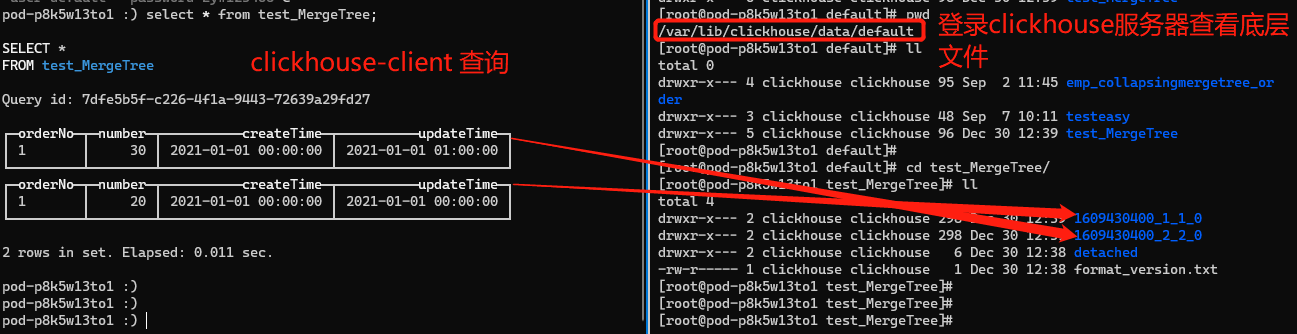
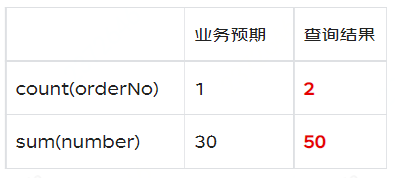
Kết quả mong đợi sẽ là số được cập nhật từ 20 đến 30 và updateTime cũng được cập nhật thành giá trị tương ứng. Chỉ có một hàng dữ liệu cho cùng một khóa chính doanh nghiệp, nhưng cuối cùng hai hàng được giữ lại. Logic xử lý này trong Clickhouse sẽ khiến dữ liệu chúng ta truy vấn không chính xác. Ví dụ, để đếm số đơn hàng không trùng lặp, hãy đếm(orderNo), và để đếm số đơn hàng, hãy đếm sum(number).
Chúng ta hãy thử hợp nhất hai hàng dữ liệu.
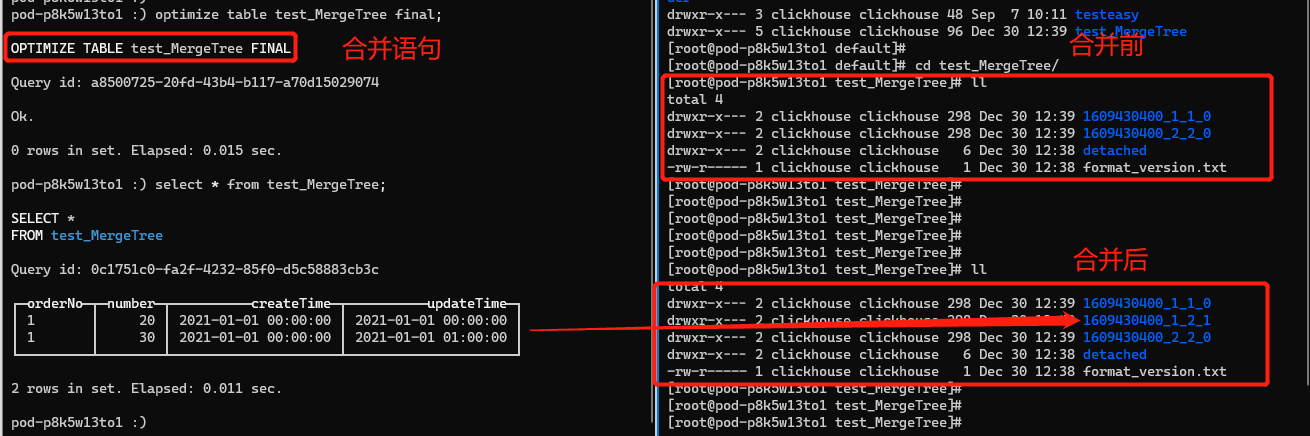
Sau khi phân đoạn bắt buộc được hợp nhất, vẫn còn hai phần dữ liệu, không phải là dữ liệu có số lượng mục cuối cùng là 30 như chúng ta mong đợi. Tuy nhiên, hai hàng dữ liệu đã được hợp nhất thành một bảng vì ID phân vùng 1609430400_1_1_0 và 1609430400_2_2_0 giống nhau và được hợp nhất thành một tệp, 1609430400_1_2_1. Sau khi quá trình hợp nhất hoàn tất, 1609430400_1_1_0 và 1609430400_2_2_0 sẽ bị xóa khỏi nền sau một khoảng thời gian nhất định (mặc định là 8 phút). Hình sau đây hiển thị quy ước đặt tên của tệp phân vùng, partitionID: 1609430400 = 2021-01-01 00:00:00, MinBolckNum, MaxBolckNum: là khối dữ liệu tối thiểu và khối dữ liệu tối đa, là một số nguyên tự tăng. Level: 0 có thể được hiểu là số lần phân vùng được hợp nhất. Giá trị mặc định là 0 và mỗi lần phân vùng mới được tạo sau khi hợp nhất, 1 sẽ được thêm vào.
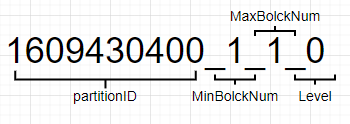
Tóm lại, chúng ta có thể thấy rằng mặc dù MergeTree có khóa chính, nhưng nó không được sử dụng để giữ cho các bản ghi duy nhất và xóa các bản sao như MySQL. Nó chỉ được sử dụng để tăng tốc các truy vấn. Ngay cả sau khi hợp nhất thủ công, các hàng dữ liệu có cùng khóa chính vẫn tồn tại. Nó không thể xóa các bản sao theo các tài liệu kinh doanh, dẫn đến kết quả không chính xác cho count(orderNo) và sum(number), không phù hợp với nhu cầu của chúng ta.
3.2 Thay thế MergeTree: Thay thế cây hợp nhất
Mặc dù MergeTree có khóa chính nhưng nó không thể loại bỏ dữ liệu trùng lặp có cùng khóa chính và kịch bản kinh doanh của chúng tôi không thể có dữ liệu trùng lặp. ClickHouse cung cấp công cụ ReplacingMergeTree để loại bỏ dữ liệu trùng lặp, có thể xóa dữ liệu trùng lặp khi hợp nhất các phân vùng. Tôi hiểu rằng việc loại bỏ trùng lặp được chia thành hai khía cạnh: một là loại bỏ trùng lặp vật lý, tức là dữ liệu trùng lặp được xóa trực tiếp và khía cạnh còn lại là loại bỏ trùng lặp truy vấn, tức là không xử lý dữ liệu vật lý nhưng kết quả truy vấn đã lọc ra dữ liệu trùng lặp.
Ví dụ như sau. Phương pháp tạo bảng ReplacingMergeTree không khác biệt nhiều so với MergeTree, ngoại trừ ENGINE được thay đổi từ MergeTree thành ReplacingMergeTree([ver]), trong đó ver là cột phiên bản, là một mục tùy chọn. Trang web chính thức hỗ trợ các kiểu UInt, Date hoặc DateTime, nhưng tôi đã kiểm tra rằng kiểu Int cũng được hỗ trợ (ClickHouse 20.8.11). ReplacingMergeTree loại bỏ dữ liệu trùng lặp vật lý khi hợp nhất dữ liệu. Chiến lược loại bỏ trùng lặp như sau.
- Nếu cột phiên bản ver không được chỉ định, hàng được chèn cuối cùng có cùng khóa chính sẽ được giữ nguyên.
- Nếu cột ver đã được chỉ định, ví dụ sau đây sẽ chỉ định cột version là cột version. Khi thực hiện loại bỏ trùng lặp, hàng có giá trị version lớn nhất sẽ được giữ lại, bất kể thứ tự chèn dữ liệu.
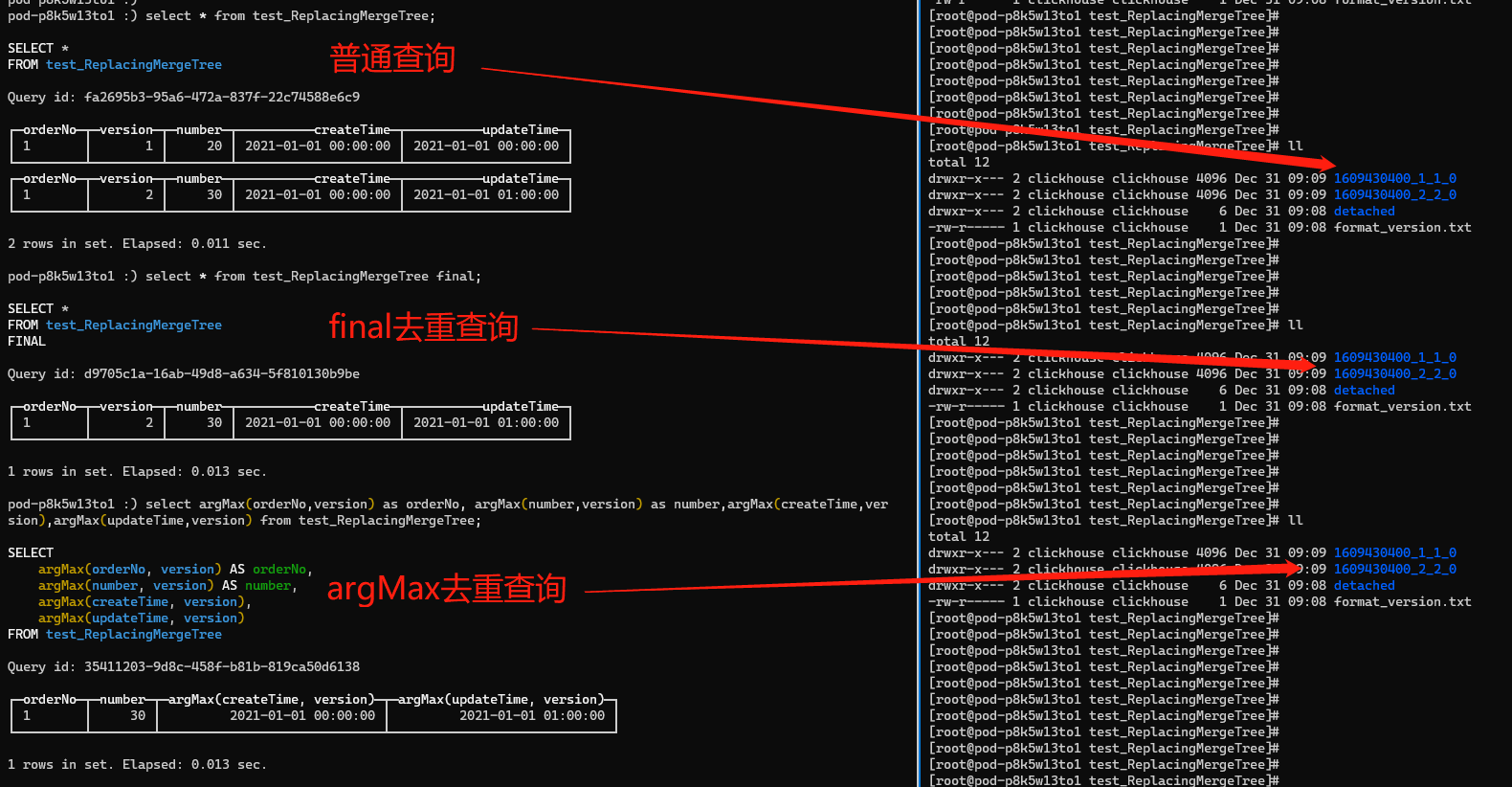
TẠO BẢNG test_ReplacingMergeTree (orderNo String, phiên bản Int16, số Int16, createTime DateTime, updateTime DateTime) ENGINE = ReplacingMergeTree(phiên bản)PHÂN VÙNG THEO createTimeORDER THEO (orderNo)KHÓA CHÍNH (orderNo);1) chèn vào test_ReplacingMergeTree giá trị('1', 1, '20', '2021-01-01 00:00:00', '2021-01-01 00:00:00');2) chèn vào test_ReplacingMergeTree giá trị('1', 2, '30', '2021-01-01 00:00:00', '2021-01-01 01:00:00');3) chèn vào test_ReplacingMergeTree values('1', 3, '30', '2021-01-02 00:00:00', '2021-01-01 01:00:00');-- phương thức cuối cùng để loại bỏ các mục trùng lặp select * from test_ReplacingMergeTree final;-- phương thức argMax để loại bỏ các mục trùng lặp select argMax(orderNo,version) as orderNo, argMax(number,version) as number,argMax(createTime,version),argMax(updateTime,version) from test_ReplacingMergeTree;
Hình sau đây cho thấy kết quả của ba truy vấn sau khi thực hiện hai câu lệnh chèn đầu tiên. Ba phương pháp truy vấn không ảnh hưởng đến dữ liệu được lưu trữ vật lý. Các phương pháp final và argMax chỉ loại bỏ trùng lặp kết quả truy vấn.
- Truy vấn bình thường: kết quả truy vấn không được loại bỏ trùng lặp, dữ liệu vật lý không được loại bỏ trùng lặp (các tệp phân vùng không được hợp nhất)
- Truy vấn loại bỏ trùng lặp cuối cùng: Kết quả truy vấn đã được loại bỏ trùng lặp, nhưng dữ liệu vật lý vẫn chưa được loại bỏ trùng lặp (các tệp phân vùng chưa được hợp nhất)
- Truy vấn loại bỏ trùng lặp argMax: kết quả truy vấn được loại bỏ trùng lặp, nhưng dữ liệu vật lý không được loại bỏ trùng lặp (các tệp phân vùng không được hợp nhất)
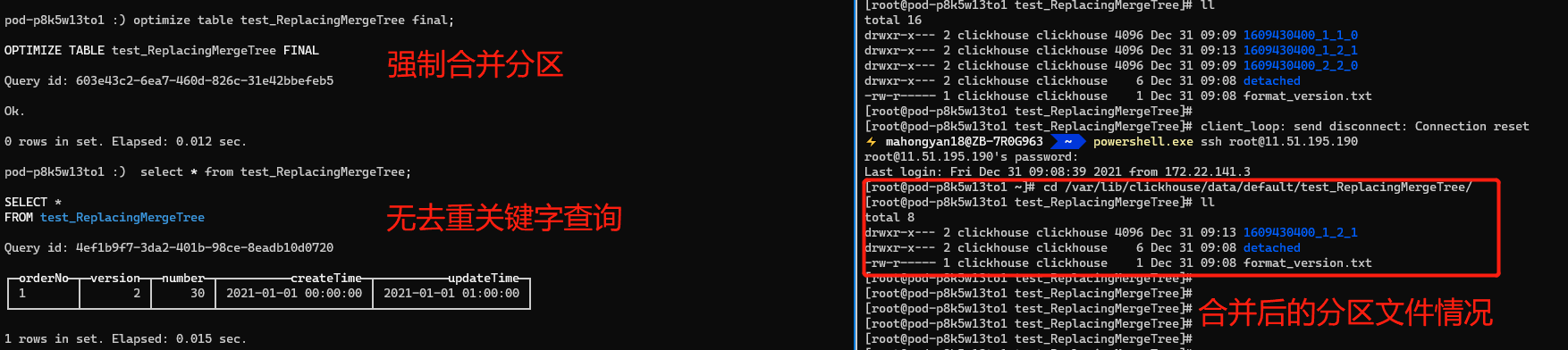
Cả hai phương thức truy vấn final và argMax đều lọc ra dữ liệu trùng lặp. Tất cả các ví dụ của chúng tôi đều dựa trên các hoạt động bảng cục bộ. Không có sự khác biệt nào về kết quả giữa final và argMax. Tuy nhiên, nếu thử nghiệm dựa trên một bảng phân tán và hai phần dữ liệu nằm trên các phân đoạn dữ liệu khác nhau (lưu ý rằng đây không phải là phân vùng dữ liệu), thì kết quả của final và argMax sẽ khác nhau. Kết quả cuối cùng sẽ không được loại bỏ trùng lặp vì final chỉ có thể thực hiện truy vấn loại bỏ trùng lặp trên các bảng cục bộ và không thể thực hiện truy vấn loại bỏ trùng lặp trên dữ liệu phân mảnh chéo, nhưng kết quả của argMax là loại bỏ trùng lặp. argMax so sánh kích thước của phiên bản tham số thứ hai để trích xuất dữ liệu mới nhất mà chúng ta muốn truy vấn để lọc dữ liệu trùng lặp. Nguyên tắc là thu thập dữ liệu của từng Shard vào bộ nhớ của cùng một Shard để so sánh và tính toán, do đó hỗ trợ loại bỏ trùng lặp giữa các Shard.
Vì lệnh hợp nhất nền được thực hiện tại thời điểm không xác định, hãy thực hiện lệnh hợp nhất và sau đó sử dụng truy vấn bình thường. Kết quả là dữ liệu đã loại bỏ trùng lặp. Phiên bản = 2, số = 30 là dữ liệu chúng ta muốn giữ lại.
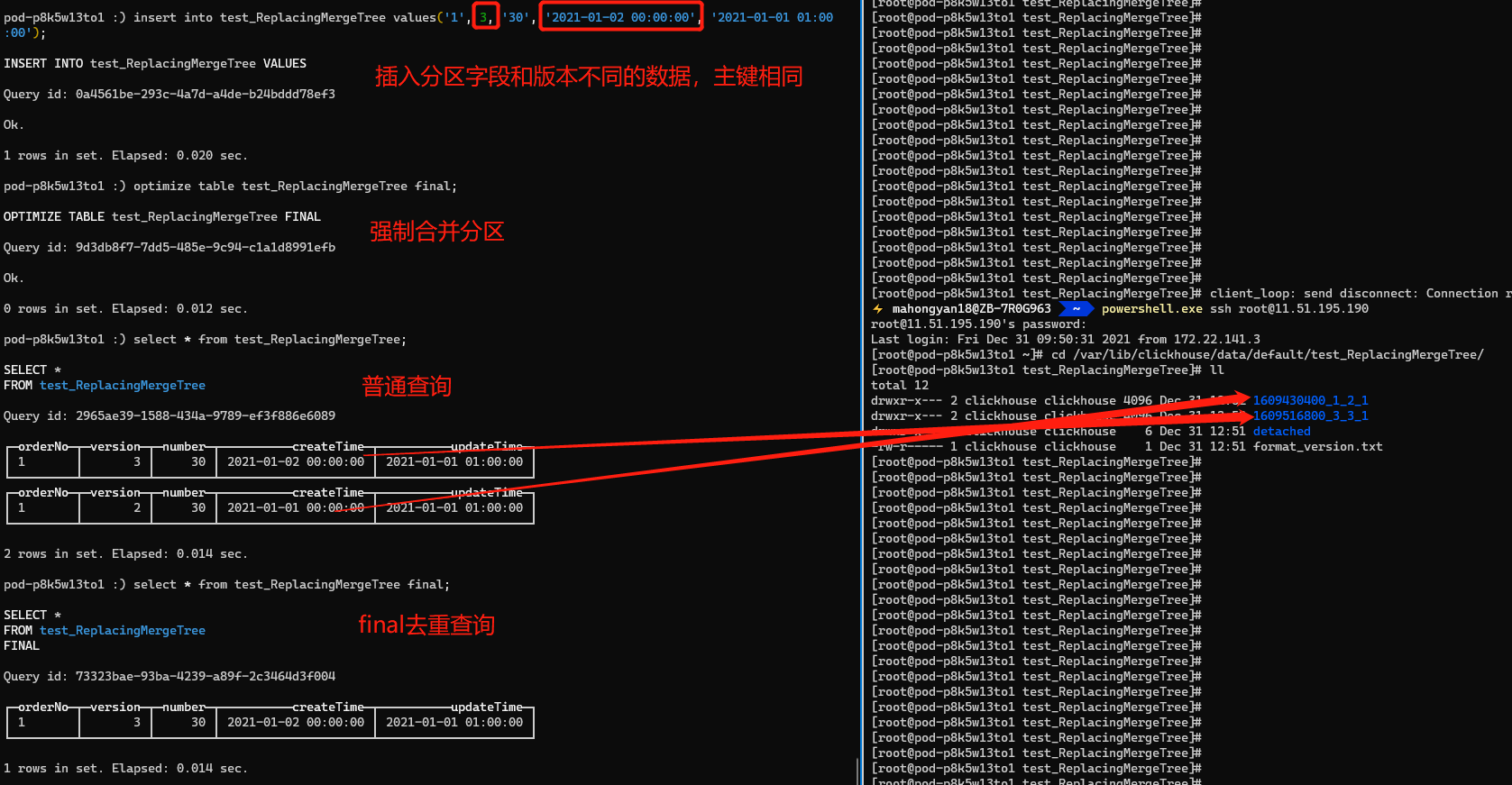
Thực hiện lệnh chèn thứ ba. Khóa chính của lệnh thứ ba giống với hai lệnh đầu tiên, nhưng trường phân vùng createTime thì khác. Hai lệnh đầu tiên là 2021-01-01 00:00:00, và lệnh thứ ba là 2021-01-02 00:00:00. Nếu chúng ta làm theo hiểu biết trên, dữ liệu có phiên bản = 3 sẽ được giữ lại sau khi hợp nhất bắt buộc. Sau khi thực hiện truy vấn bình thường, chúng tôi thấy rằng dữ liệu của phiên bản = 1 và 2 đã được hợp nhất và loại bỏ trùng lặp, và 2 được giữ lại, nhưng phiên bản = 3 vẫn tồn tại. Lý do là vì ReplacingMergeTree xóa dữ liệu trùng lặp theo đơn vị phân vùng. Các trường phân vùng createTime và partitionID của hai lần chèn đầu tiên là giống nhau, do đó chúng được hợp nhất vào tệp phân vùng 1609430400_1_2_1. Tuy nhiên, lần chèn thứ ba không nhất quán với hai lần đầu tiên và không thể được hợp nhất vào một tệp phân vùng, do đó không thể thực hiện được việc loại bỏ trùng lặp vật lý. Cuối cùng, thông qua truy vấn loại bỏ trùng lặp cuối cùng, người ta thấy rằng việc loại bỏ trùng lặp truy vấn có thể được hỗ trợ và argMax cũng có tác dụng tương tự, nhưng không được hiển thị.
ReplacingMergeTree có những đặc điểm sau.
- Sử dụng khóa chính làm khóa duy nhất để xác định dữ liệu trùng lặp và hỗ trợ chèn dữ liệu có cùng khóa chính.
- Logic xóa dữ liệu trùng lặp sẽ được kích hoạt khi hợp nhất các phân vùng. Tuy nhiên, thời điểm hợp nhất vẫn chưa chắc chắn nên có thể có dữ liệu trùng lặp khi truy vấn, nhưng cuối cùng các dữ liệu trùng lặp đó sẽ bị xóa. Bạn có thể gọi optimize theo cách thủ công, nhưng nó sẽ khiến lượng dữ liệu đọc và ghi tăng lên, do đó không được khuyến khích sử dụng trong sản xuất.
- Dữ liệu trùng lặp được xóa theo đơn vị phân vùng dữ liệu. Khi các phân vùng được hợp nhất, dữ liệu trùng lặp trong cùng một phân vùng sẽ bị xóa, nhưng dữ liệu trùng lặp trong các phân vùng khác nhau sẽ không bị xóa.
- Bạn có thể sử dụng các phương thức final và argMax để loại bỏ trùng lặp các truy vấn. Phương thức này có thể nhận được kết quả truy vấn chính xác bất kể việc hợp nhất dữ liệu có được thực hiện hay không.
Thực hành tốt nhất của ReplaceMergeTree.
- Truy vấn chọn thông thường: Đối với các truy vấn ngoại tuyến có hiệu quả thời gian thấp, có thể sử dụng tính năng hợp nhất tự động của ClickHouse, nhưng cần đảm bảo rằng cùng một tài liệu kinh doanh nằm trên cùng một phân vùng dữ liệu và bảng phân phối cũng cần được đảm bảo nằm trong cùng một phân đoạn. Đây là phương pháp truy vấn hiệu quả nhất và tiết kiệm tài nguyên tính toán nhất.
- Chế độ truy vấn cuối cùng: Đối với truy vấn thời gian thực, bạn có thể sử dụng final. Final là loại bỏ trùng lặp cục bộ. Cần đảm bảo rằng dữ liệu có cùng khóa chính nằm trên cùng một phân đoạn, nhưng không cần phải nằm trên cùng một phân vùng dữ liệu. Phương pháp này đứng thứ hai về hiệu quả, nhưng nó tiêu tốn một số hiệu suất so với select thông thường. Nếu điều kiện where chạm đúng chỉ mục khóa chính, chỉ mục phụ và trường phân vùng, thì có thể sử dụng hiệu quả đầy đủ.
- Truy vấn sử dụng argMax: Đối với các truy vấn thời gian thực, bạn có thể sử dụng argMax. Yêu cầu sử dụng argMax là thấp nhất và nó có thể loại bỏ các bản sao trong bất kỳ truy vấn nào. Tuy nhiên, do phương pháp triển khai của nó, hiệu quả của nó thấp hơn nhiều và tiêu tốn nhiều hiệu suất, vì vậy không được khuyến khích. Sau này trong 9.4.3, chúng tôi sẽ so sánh dữ liệu thử nghiệm ứng suất với phiên bản cuối cùng.
Trong ba lược đồ sử dụng được đề cập ở trên, phương pháp ReplacingMergeTree bằng phương thức truy vấn cuối cùng đáp ứng được nhu cầu của chúng ta.
3.3 CollapsingMergeTree/VersionedCollapsingMergeTree: Thu gọn cây hợp nhất
Việc thu gọn và hợp nhất cây không còn được giải thích thông qua ví dụ nữa. Vui lòng tham khảo trang web chính thức để biết ví dụ.
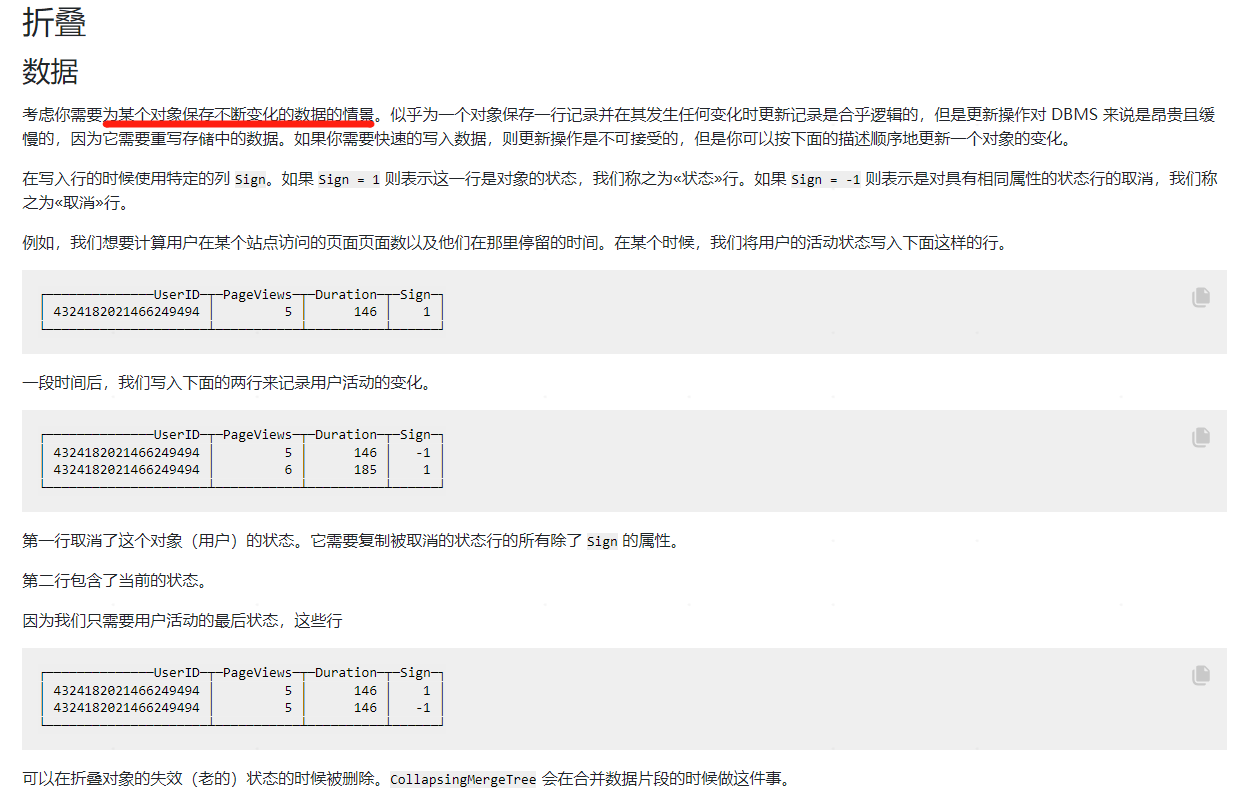
CollapsingMergeTree ghi lại trạng thái của hàng dữ liệu bằng cách xác định trường bit dấu hiệu. Nếu cờ hiệu là 1 (dòng "Trạng thái"), điều đó có nghĩa là đây là một dòng dữ liệu hợp lệ. Nếu cờ hiệu là -1 (dòng "Hủy"), điều đó có nghĩa là dòng dữ liệu này cần phải bị xóa. Cần lưu ý rằng dữ liệu có cùng khóa chính có thể được gấp lại.
- Nếu có ít nhất một hàng dữ liệu có dấu = 1 so với hàng có dấu = -1, thì hàng dữ liệu cuối cùng có dấu = 1 sẽ được giữ lại.
- Nếu có ít nhất một hàng nữa có dấu = -1 so với hàng có dấu = 1, hãy giữ nguyên hàng đầu tiên có dấu = -1.
- Nếu có cùng số hàng có dấu = 1 và dấu = -1, và hàng cuối cùng có dấu = 1, thì giữ nguyên dữ liệu của hàng đầu tiên có dấu = -1 và hàng cuối cùng có dấu = 1.
- Nếu có cùng số hàng có dấu = 1 như số hàng có dấu = -1 và hàng cuối cùng có dấu = -1 thì không có gì được giữ lại.
- Trong những trường hợp khác, ClickHouse sẽ không báo lỗi nhưng sẽ in nhật ký cảnh báo. Trong trường hợp này, kết quả truy vấn không chắc chắn và không thể đoán trước.
Hãy cẩn thận khi sử dụng CollapsingMergeTree.
1) Giống như ReplacingMergeTree, việc gấp dữ liệu không được kích hoạt theo thời gian thực. Nó chỉ được phản ánh khi các phân vùng được hợp nhất. Dữ liệu trùng lặp vẫn sẽ được truy vấn trước khi hợp nhất. Có hai giải pháp.
- Sử dụng optimize để ép hợp nhất. Cũng không nên sử dụng forcing merge trong môi trường production vì nó cực kỳ kém hiệu quả và tiêu tốn tài nguyên.
- Viết lại phương thức truy vấn và sử dụng nhóm theo với cột dấu có dấu để hoàn thiện. Phương pháp này làm tăng chi phí mã hóa được sử dụng
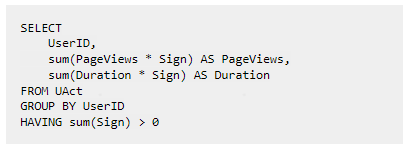
2) Về mặt ghi, chương trình cần ghi dữ liệu sẽ ghi lại dữ liệu của dòng "Trạng thái" bằng cách xóa hoặc sửa dữ liệu thông qua dòng "Hủy", điều này làm tăng đáng kể chi phí lưu trữ và độ phức tạp của lập trình. Flink sẽ chạy lại dữ liệu khi nó trực tuyến hoặc trong một số trường hợp, điều này có thể khiến các hàng dữ liệu được ghi lại trong chương trình bị mất, có thể khiến sign=1 và sign=-1 không bằng nhau và không thể hợp nhất. Đây là vấn đề chúng tôi không thể chấp nhận.
CollapsingMergeTree có một nhược điểm khác. Nó có yêu cầu nghiêm ngặt về thứ tự viết. Nếu được viết theo thứ tự bình thường, hàng có dấu = 1 được viết trước và sau đó là hàng có dấu = -1, nó có thể được hợp nhất bình thường. Nếu thứ tự bị đảo ngược, nó không thể được hợp nhất bình thường. ClickHouse cung cấp VersionedCollapsingMergeTree để giải quyết vấn đề thứ tự bằng cách tăng số phiên bản. Tuy nhiên, các tính năng khác thì giống hệt CollapsingMergeTree và không thể đáp ứng được nhu cầu của chúng tôi.
3.4 Tóm tắt về công cụ bảng
Chúng tôi đã giới thiệu chi tiết bốn công cụ bảng trong loạt MergeTree, cụ thể là MergeTree, ReplacingMergeTree, CollapsingMergeTree và VersionedCollapsingMergeTree. SummingMergeTree và AggregatingMergeTree chưa được giới thiệu. SummingMergeTree là một công cụ bảng được thiết kế cho những người chỉ quan tâm đến dữ liệu tóm tắt và không quan tâm đến dữ liệu chi tiết. MergeTree cũng có thể đáp ứng nhu cầu chỉ tập trung vào dữ liệu tóm tắt, có thể đáp ứng thông qua nhóm theo với các hàm tổng hợp tổng và đếm, nhưng tổng hợp theo thời gian thực cho mỗi truy vấn sẽ làm tăng đáng kể chi phí. Chúng tôi có cả yêu cầu về dữ liệu chi tiết và yêu cầu về chỉ số tóm tắt, do đó SummingMergeTree không thể đáp ứng được nhu cầu của chúng tôi. AggregatingMergeTree là phiên bản nâng cấp của SummingMergeTree. Về cơ bản, chúng giống nhau. Điểm khác biệt là SummingMergeTree thực hiện tổng hợp trên các cột không phải khóa chính, trong khi AggregatingMergeTree có thể chỉ định nhiều hàm tổng hợp khác nhau. Nó cũng không đáp ứng được nhu cầu.

Cuối cùng, chúng tôi đã chọn công cụ ReplacingMergeTree. Bảng phân tán được phân mảnh bằng khóa chính doanh nghiệp sipHash64 (docId) để đảm bảo dữ liệu có cùng khóa chính doanh nghiệp sẽ nằm trong cùng một phân mảnh. Đồng thời, thời gian tạo tài liệu doanh nghiệp được sử dụng để phân vùng theo tháng hoặc ngày. Hợp tác với final để thực hiện loại bỏ trùng lặp truy vấn. Trong thời kỳ Double 11, khối lượng dữ liệu của giải pháp này tăng 30 triệu mỗi ngày và QPS cơ sở dữ liệu là 93 trong thời kỳ kinh doanh cao điểm. Mức sử dụng CPU của cụm 32C 128G 6 phân đoạn 2 bản sao lên tới 60% và toàn bộ hệ thống ổn định. Tất cả các tối ưu hóa thực tế dưới đây cũng dựa trên công cụ ReplacingMergeTree.
4 Cách viết Flink cho ClickHouse
4.1 Các vấn đề về phiên bản Flink
Flink hỗ trợ ghi dữ liệu vào cơ sở dữ liệu JDBC thông qua JDBC Connector, nhưng phương pháp ghi của JDBC Connector trong các phiên bản Flink khác nhau lại rất khác nhau. Bởi vì Flink đã thực hiện một bản tái cấu trúc lớn của JDBC Connector trong phiên bản 1.11:
- Tên gói trước phiên bản 1.11 là flink-jdbc
- Sau phiên bản 1.11 (bao gồm), tên gói là flink-connector-jdbc
Hai hỗ trợ viết ClickHouse Sink theo những cách khác nhau trong Flink như sau
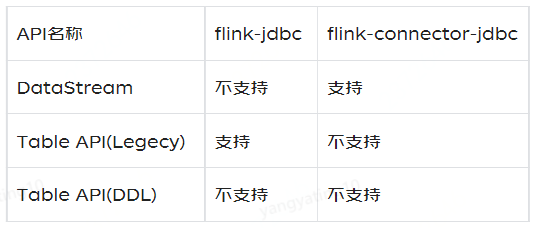
Ban đầu chúng tôi sử dụng Flink phiên bản 1.10.3. flink-jdbc không hỗ trợ ghi bằng DataStream. Chúng tôi cần nâng cấp phiên bản Flink lên 1.11.x hoặc cao hơn để sử dụng flink-connector-jdbc để ghi dữ liệu vào ClickHouse.
4.2 Xây dựng bồn rửa ClickHouse
/** * Construct Sink * @param clusterPrefix clickhouse tên cơ sở dữ liệu * @param sql chèn trình giữ chỗ eq: chèn vào demo (id, tên) giá trị (?, ?) */ public static SinkFunction getSink(String clusterPrefix, String sql) { String clusterUrl = LoadPropertiesUtil.appInfoProcessMap.get(clusterPrefix + CLUSTER_URL); String clusterUsername = LoadPropertiesUtil.appInfoProcessMap.get(clusterPrefix + CLUSTER_USER_NAME); String clusterPassword = LoadPropertiesUtil.appInfoProcessMap.get(clusterPrefix + CLUSTER_PASSWORD); return JdbcSink.sink(sql, new CkSinkBuilder<>(), new JdbcExecutionOptions.Builder().withBatchSize(200000).build(), new JdbcConnectionOptions.JdbcConnectionOptionsBuilder() .withDriverName("ru.yandex.clickhouse.ClickHouseDriver") .withUrl(clusterUrl) .withUsername(clusterUsername) .withPassword(clusterPassword) .build());}
Sử dụng api JdbcSink.sink() của flink-connector-jdbc để xây dựng bộ thu Flink. Ý nghĩa của các tham số JdbcSink.sink() như sau.
- sql: Câu lệnh SQL ở dạng giữ chỗ, ví dụ: chèn vào demo (id, name) các giá trị (?, ?)
- new CkSinkBuilder<>(): Lớp triển khai của giao diện org.apache.flink.connector.jdbc.JdbcStatementBuilder. Lớp này chủ yếu ánh xạ dữ liệu trong luồng tới java.sql.PreparedStatement để xây dựng PreparedStatement. Chi tiết không được nhắc lại ở đây.
- Tham số thứ ba: chiến lược thực hiện của flink sink.
- Tham số đầu vào thứ tư: trình điều khiển jdbc, kết nối, tài khoản và mật khẩu.

- Khi sử dụng, chỉ cần thêmSink vào luồng DataStream.
5 Flink viết chiến lược ClickHouse
Flink ghi vào ES và Clikhouse cùng lúc, nhưng khi truy vấn dữ liệu, tôi thấy ClickHouse luôn chậm hơn ES. Tôi bắt đầu nghi ngờ rằng việc hợp nhất ClickHouse và các xử lý khác sẽ mất một thời gian, nhưng các hoạt động hợp nhất này của ClickHouse sẽ không ảnh hưởng đến truy vấn. Sau đó, tôi đã kiểm tra mã chiến lược ghi Flink và phát hiện ra rằng có vấn đề với chiến lược mà chúng tôi sử dụng.
Trong mã trước đó (4.2), new JdbcExecutionOptions.Builder().withBatchSize(200000).build() là một chiến lược ghi. ClickHouse khuyến nghị ghi hàng loạt không ít hơn 1.000 hàng hoặc không quá một yêu cầu ghi mỗi giây để cải thiện hiệu suất ghi. Chiến lược là ghi 200.000 hàng bản ghi một lần và Flink cũng sẽ xác nhận việc ghi khi thực hiện điểm kiểm tra. Do đó, sẽ chỉ có dữ liệu trong ClickHouse khi lượng dữ liệu tích lũy đến 20W hoặc Flink ghi nhớ Checkpoint. Chiến lược ES sink của chúng tôi là ghi và cam kết sau mỗi 1.000 hàng hoặc 5 giây, do đó việc ghi vào ClickHouse chậm hơn so với ghi vào ES.
Có một bất lợi khi gửi khi dữ liệu đạt 20W hoặc khi Checkpoint được thực hiện. Khi lượng dữ liệu nhỏ và không đạt đến mức 20W, khoảng thời gian Checkpoint là t1 và thời gian checkpoint là t2. Khi đó, khoảng thời gian dài nhất từ khi nhận được tin nhắn JDQ đến khi ghi vào ClickHouse là t1+t2, hoàn toàn phụ thuộc vào thời gian Checkpoint. Đôi khi có tình trạng tồn đọng dữ liệu và thời gian chậm nhất là 1~2 phút. Sau đó, chiến lược ghi của ClickHouse được tối ưu hóa và JdbcExecutionOptions.Builder().withBatchIntervalMs(30 * 1000).build() mới được tối ưu hóa để gửi một lần sau mỗi 30 giây. Theo cách này, nếu Checkpoint chậm, có thể kích hoạt chiến lược đệ trình 30 giây. Nếu không, đệ trình được thực hiện trong Checkpoint. Đây cũng là một chiến lược tương đối thỏa hiệp có thể điều chỉnh theo đặc điểm kinh doanh của riêng bạn. Khi gỡ lỗi thời gian đệ trình, người ta thấy rằng nếu khoảng thời gian quá nhỏ, tỷ lệ sử dụng CPU của Zookeeper sẽ tăng lên. Nếu đệ trình ZK được đệ trình một lần sau mỗi 10 giây, tỷ lệ sử dụng sẽ tăng từ dưới 5% lên khoảng 10%.
Logic xử lý của org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat#open trong Flink như sau.

6 Ghi vào một bảng phân tán hoặc một bảng cục bộ
Trước tiên, chúng ta hãy nói về kết quả. Chúng ta đang viết vào một bảng phân tán. Thông tin trực tuyến và các đồng nghiệp từ dịch vụ đám mây ClickHouse khuyên bạn nên viết thư cho một bảng cục bộ. Bảng phân tán thực chất là một bảng logic và không lưu trữ dữ liệu vật lý thực tế. Ví dụ, khi truy vấn một bảng phân tán, bảng phân tán sẽ gửi yêu cầu truy vấn đến bảng cục bộ của mỗi phân đoạn để truy vấn, sau đó tổng hợp kết quả của bảng cục bộ của mỗi phân đoạn và trả về chúng sau khi tóm tắt. Khi ghi vào một bảng phân tán, bảng phân tán sẽ lưu trữ dữ liệu đã ghi trên các phân đoạn khác nhau theo các quy tắc nhất định. Nếu việc ghi vào một bảng phân tán chỉ là một chuyển tiếp mạng đơn giản, thì tác động không đáng kể. Tuy nhiên, việc ghi vào một bảng phân tán không phải là một chuyển tiếp đơn giản. Tình hình thực tế được thể hiện trong hình bên dưới.
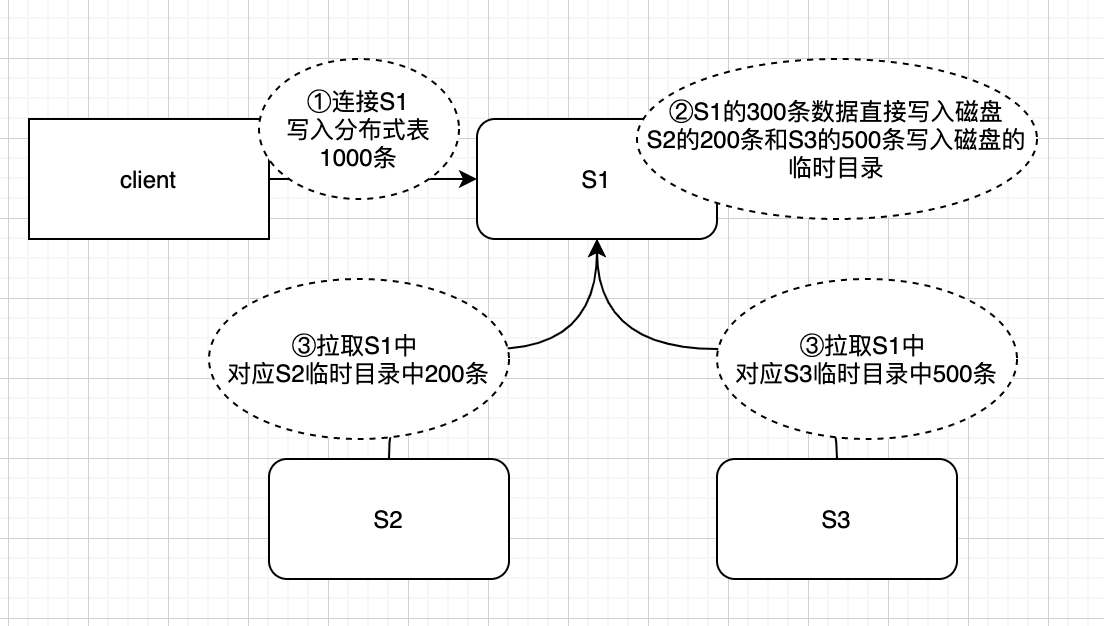
Có ba phân đoạn S1, S2 và S3. Máy khách kết nối với nút S1 để ghi vào bảng phân tán.
- Bước 1: Ghi 1.000 bản ghi vào bảng phân phối. Bảng phân phối sẽ được phân bổ theo các quy tắc định tuyến. Giả sử theo các quy tắc, 300 bản ghi được phân bổ cho S1, 200 cho S2 và 500 cho S3.
- Bước 2: Client gửi 1.000 mẩu dữ liệu, 300 mẩu dữ liệu thuộc về S1 được ghi trực tiếp vào đĩa, dữ liệu của S2 và S3 cũng được ghi vào thư mục tạm thời của S1
- Bước 3: S2 và S3 nhận được thông báo thay đổi từ zk, tạo tác vụ để kéo dữ liệu thư mục tạm thời tương ứng với phân đoạn hiện tại trong S1 và đưa tác vụ vào hàng đợi, chờ cơ hội nhất định để kéo dữ liệu đến các nút của chúng.
Từ phương pháp ghi của bảng phân tán, chúng ta có thể thấy rằng tất cả dữ liệu sẽ được đặt trên đĩa của phân đoạn được kết nối với máy khách. Nếu lượng dữ liệu lớn, IO của đĩa sẽ gây ra tình trạng tắc nghẽn. Ngoài ra, các công cụ thuộc dòng MergeTree có hành vi hợp nhất, có tác dụng khuếch đại ghi (một phần dữ liệu được hợp nhất nhiều lần) và chiếm một lượng hiệu suất đĩa nhất định. Các trường hợp ghi vào bảng cục bộ mà tôi thấy trực tuyến đều có mức tăng hàng ngày lên tới hàng chục hoặc hàng trăm tỷ. Chúng tôi chọn ghi vào một bảng phân tán vì hai lý do chính. Một là tính đơn giản, vì việc ghi vào một bảng cục bộ đòi hỏi phải sửa đổi mã và chỉ định nút nào để ghi vào. Lý do còn lại là việc ghi vào một bảng cục bộ không gặp phải bất kỳ tắc nghẽn hiệu suất nghiêm trọng nào trong quá trình phát triển. Trong giai đoạn Double 11, lượng dữ liệu tăng thêm 30 triệu hàng mỗi ngày (sau khi hợp nhất) không gây ra bất kỳ áp lực ghi nào. Nếu xảy ra tình trạng tắc nghẽn sau đó, việc ghi vào bảng phân phối có thể bị hủy bỏ.
7 Tại sao mức sử dụng CPU của chỉ một phân đoạn lại cao?
7.1 Phân phối dữ liệu không đồng đều dẫn đến việc sử dụng CPU cao trên một số nút
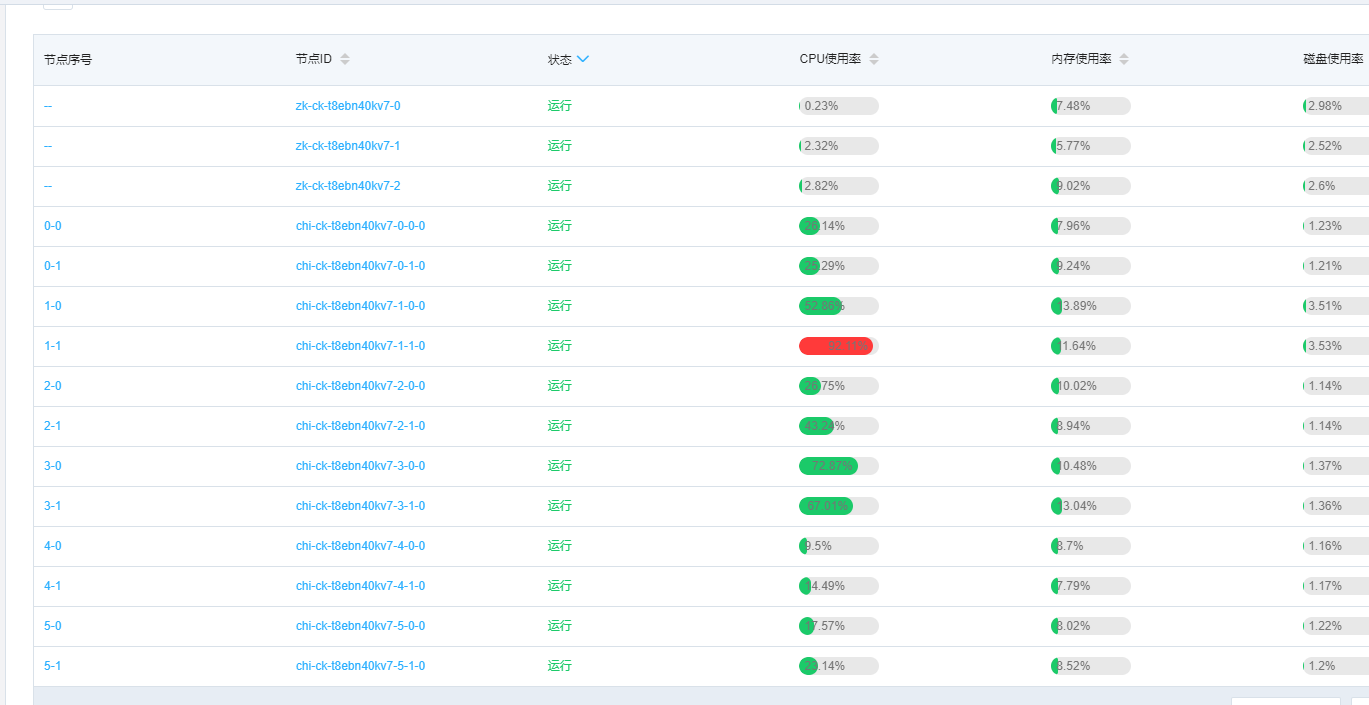
Hình ảnh trên cho thấy sự cố gặp phải khi truy cập ClickHouse, trong đó mức sử dụng CPU của nút 7-1 rất cao và sự khác biệt giữa các nút khác nhau rất lớn. Sau đó, thông qua định vị SQL, người ta phát hiện ra rằng lượng dữ liệu trên các nút khác nhau cũng rất khác nhau. Trong số đó, nút 7-1 có lượng dữ liệu lớn nhất, dẫn đến việc nút 7-1 phải xử lý một số lượng lớn các hàng dữ liệu so với các nút khác, do đó CPU sẽ cao hơn tương đối nhiều. Bởi vì chúng ta sử dụng mã trạm lưới và mã kho phân loại để băm rồi tạo ra chiến lược phân mảnh dữ liệu bảng phân tán, nhưng số lượng mã kho phân loại và mã trang web tương đối nhỏ, dẫn đến độ phân tán không đủ sau khi băm, gây ra hiện tượng lệch dữ liệu này. Sau đó, chúng tôi sử dụng khóa chính của doanh nghiệp làm hàm băm để giải quyết vấn đề sử dụng CPU cao trên một số nút.
7.2 Một nút kích hoạt việc hợp nhất, khiến CPU của nút đó ở mức cao
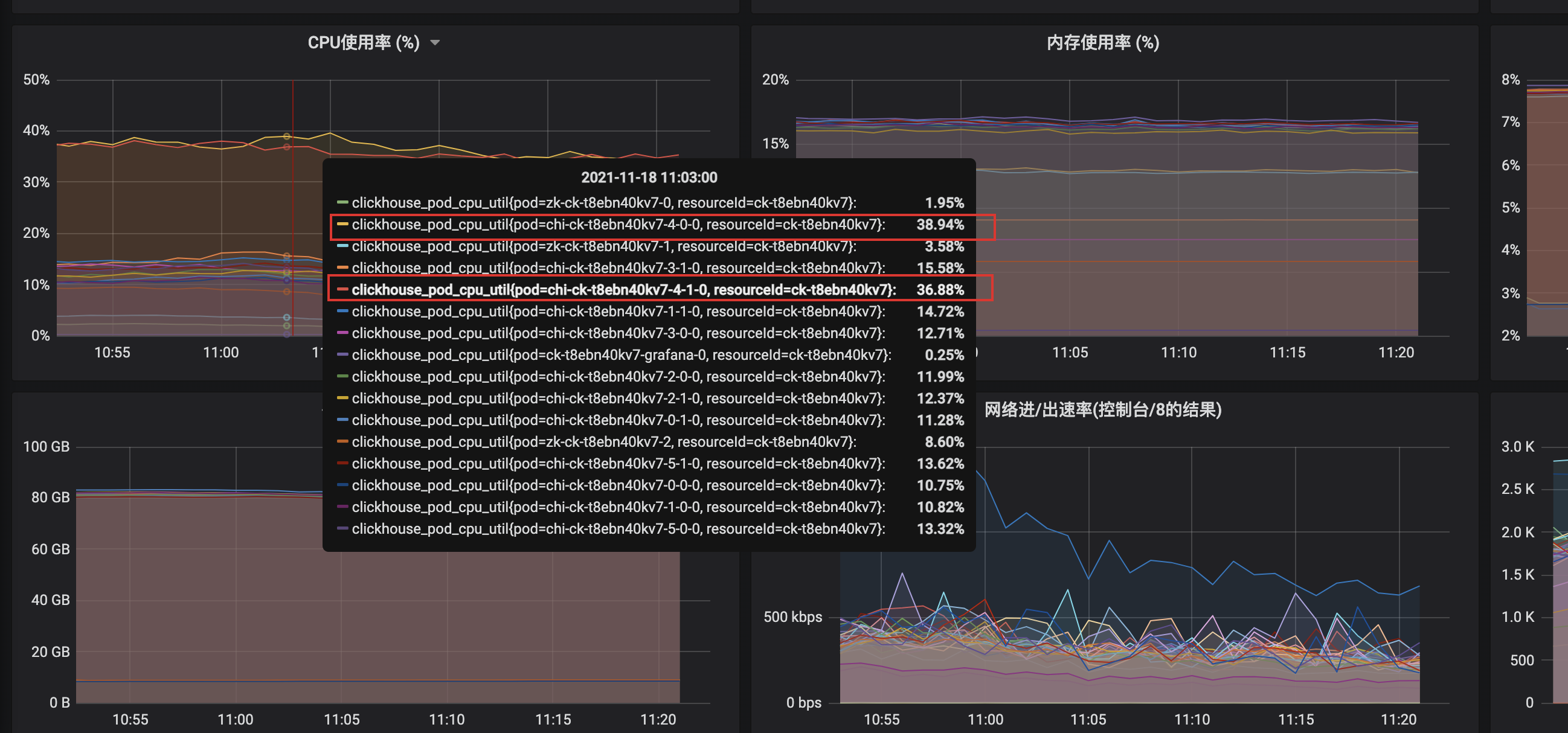
Node 7-4 (node chính và bản sao), CPU cao hơn nhiều so với các node khác không có bất kỳ dấu hiệu nào. Sau khi loại trừ các trường hợp khẩn cấp như ra mắt và quảng bá doanh nghiệp mới, SQL chậm được định vị và các truy vấn chậm của mỗi node được phân tích thông qua query_log. Đối với các tuyên bố cụ thể, hãy xem Phần 8.
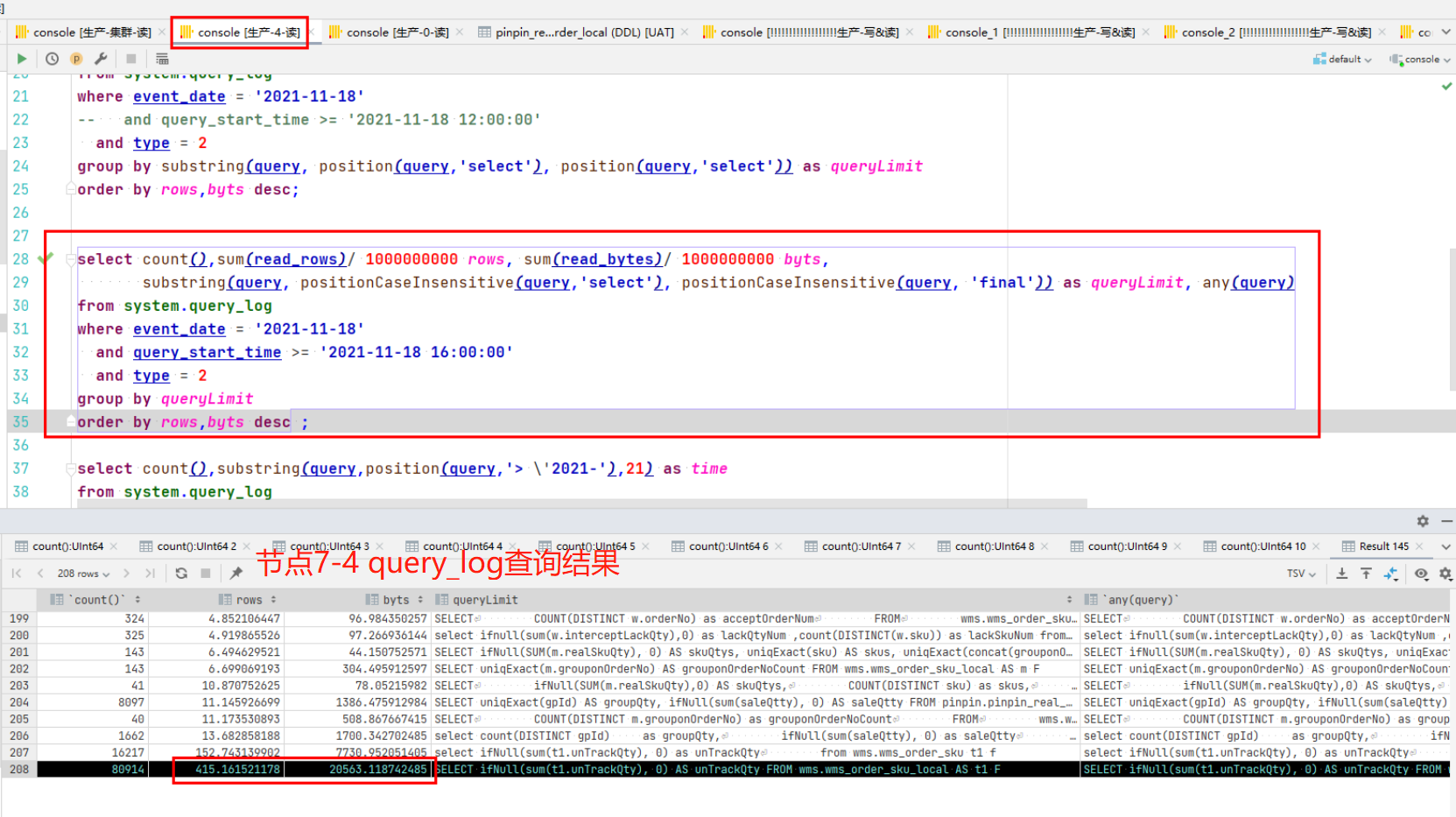
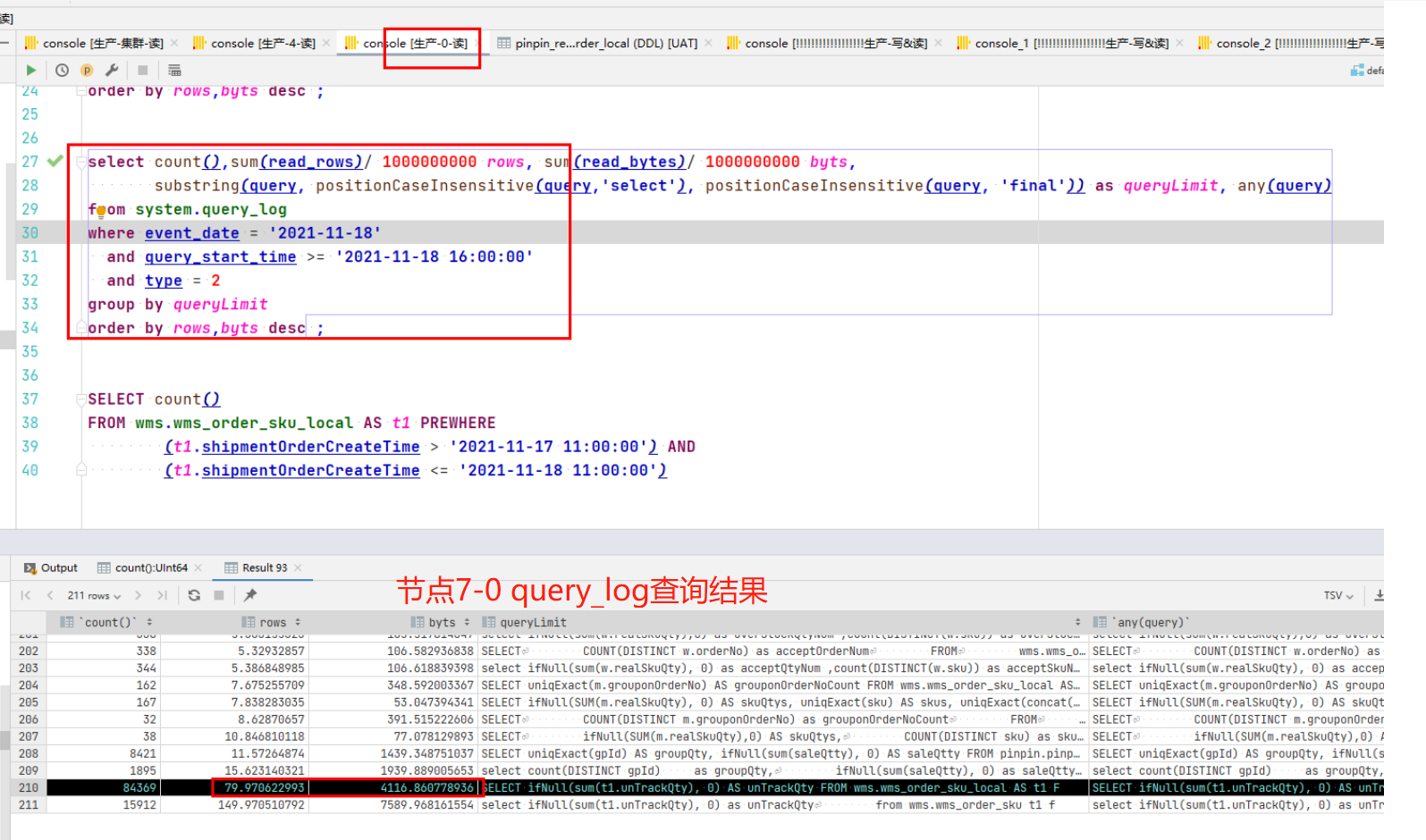
Khi so sánh SQL chậm của hai nút, người ta thấy rằng các điều kiện truy vấn của SQL sau đây khá khác biệt.
CHỌN ifNull(sum(t1.unTrackQty), 0) AS unTrackQtyFROM wms.wms_order_sku_local AS t1 FINAL PREWHERE t1.shipmentOrderCreateTime > '2021-11-17 11:00:00' AND t1.shipmentOrderCreateTime <= '2021-11-18 11:00:00' AND t1.gridStationNo = 'WG0000514' AND t1.warehouseNo KHÔNG CÓ TRONG ('wms-6-979', 'wms-6-978', '6_979', '6_978') AND t1.orderType = '10' WHERE t1.ckDeliveryTaskStatus = '3'
Nhưng chúng ta có một câu hỏi: cùng một câu lệnh, cùng một số lần thực thi, cùng một lượng dữ liệu và số phần trên hai nút. Tại sao số hàng được nút 7-4 quét lại gấp năm lần số hàng của nút 7-0? Nếu chúng ta tìm ra lý do này, chúng ta sẽ có thể xác định được nguyên nhân gốc rễ của vấn đề. Tiếp theo, chúng tôi sử dụng clickhouse-client để thực hiện truy vấn SQL, bật nhật ký cấp độ theo dõi và xem quy trình thực thi SQL. Để biết phương pháp thực hiện cụ thể và phân tích nhật ký truy vấn, vui lòng tham khảo Mục 9.1 bên dưới. Tại đây chúng tôi sẽ trực tiếp phân tích kết quả.
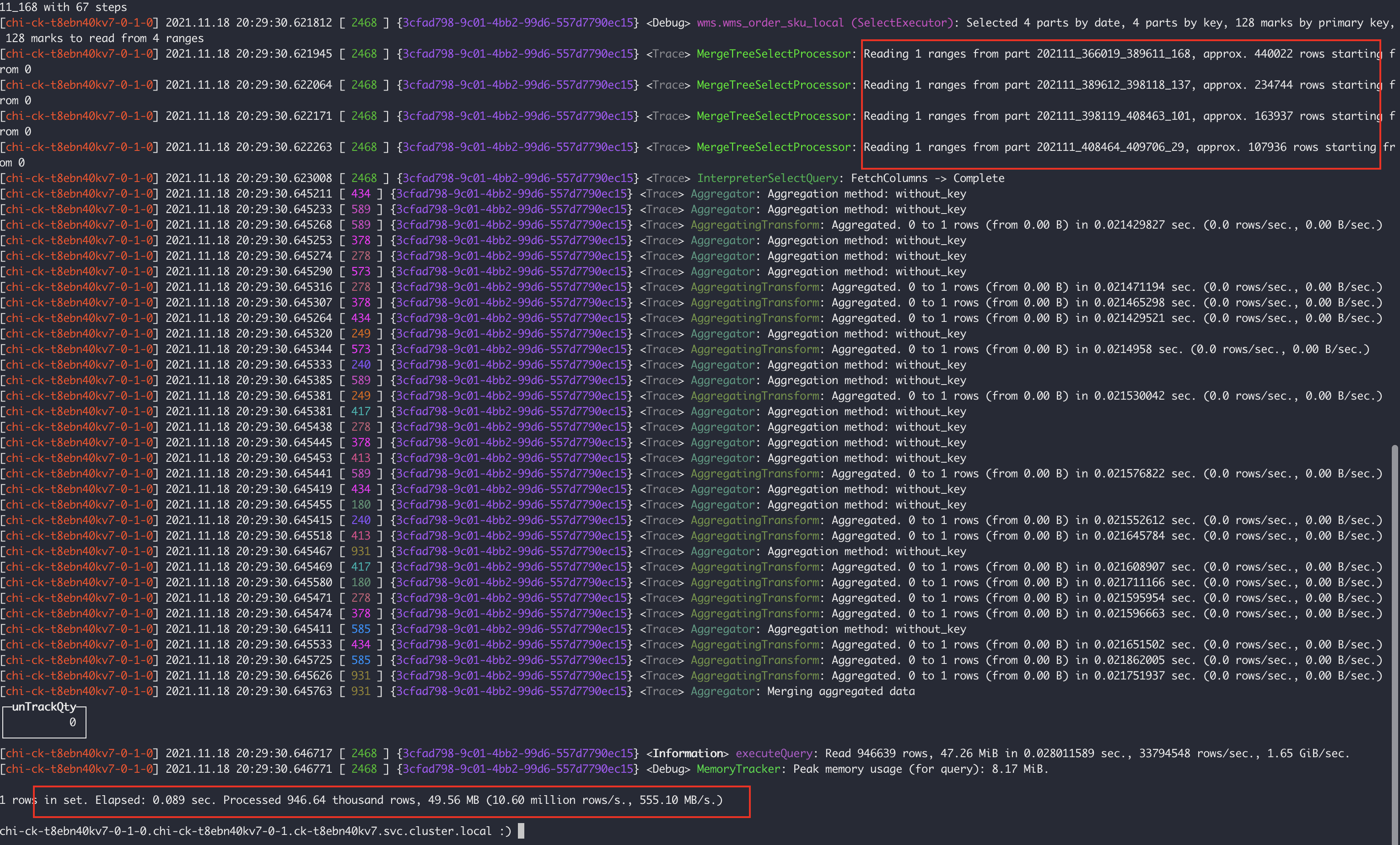
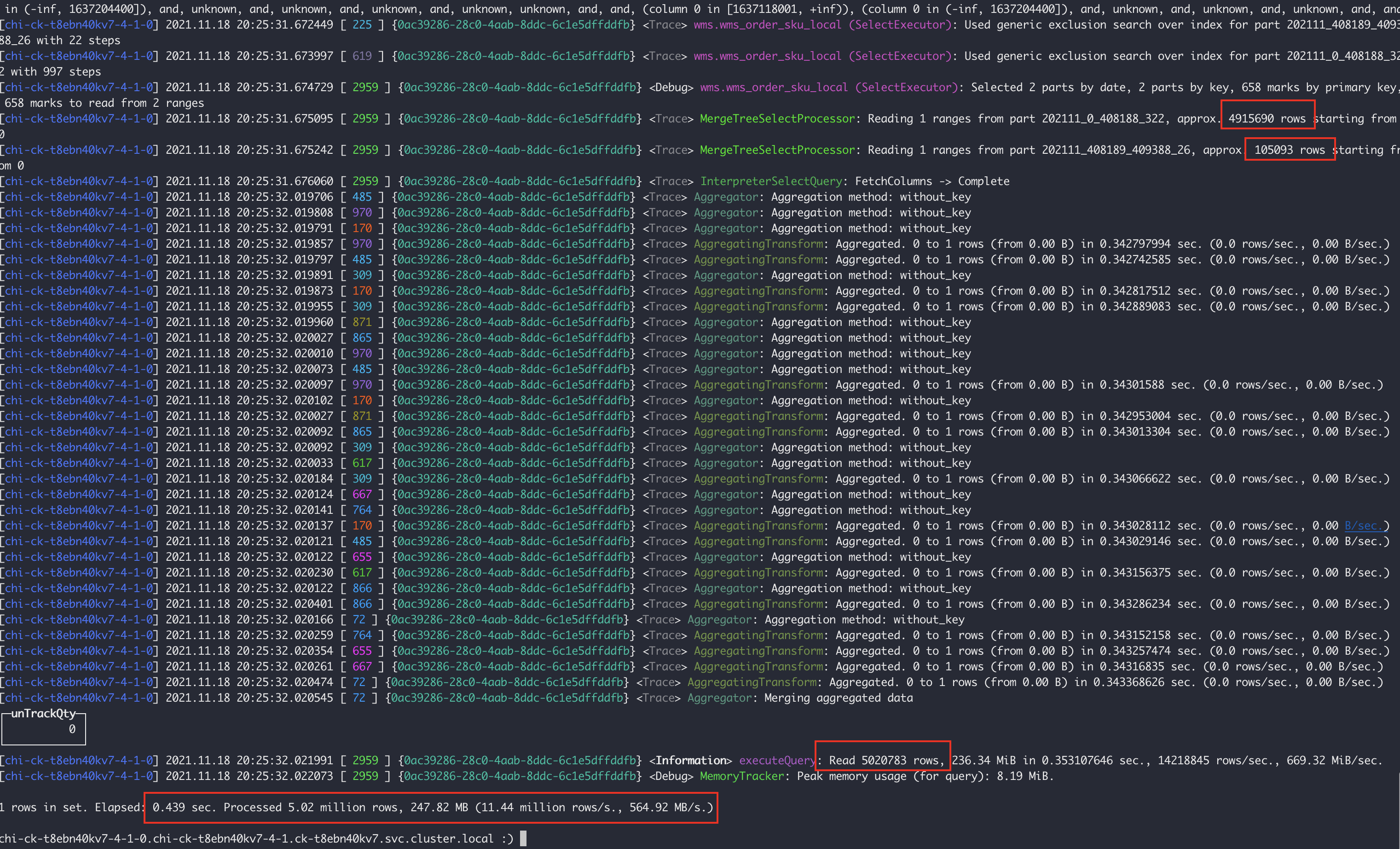
Có thể phân tích hai hình ảnh trên.
- Nút 7-0: Quét 4 tệp phân vùng, tổng cộng 94W hàng, mất 0,089 giây
- Nút 7-4: Quét các tệp phân vùng 2 phần, một trong số đó có 491 dòng W, tổng cộng 502 dòng W và mất 0,439 giây
Rõ ràng là phân vùng 202111_0_408188_322 của nút 7-4 là bất thường. Vì chúng tôi phân vùng theo tháng, phân vùng của nút 7-4 bị hợp nhất vì một lý do nào đó không rõ, khiến dữ liệu chúng tôi lấy được vào ngày 17 tháng 11 rơi vào phân vùng lớn này. Do đó, truy vấn sẽ lọc tất cả dữ liệu từ đầu tháng 11 đến ngày 18, khác với nút 7-0. Truy vấn SQL ở trên dựa trên điều kiện gridStationNo = 'WG000514', do đó vấn đề này được giải quyết bằng cách tạo chỉ mục phụ trên trường gridStationNo.
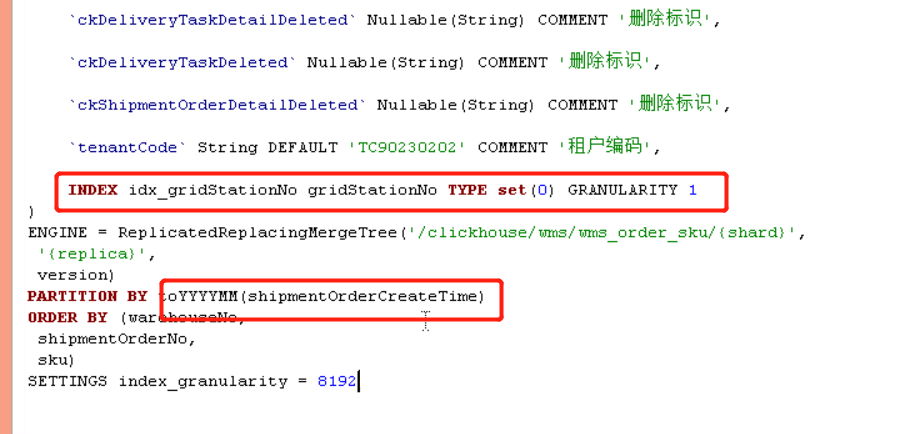
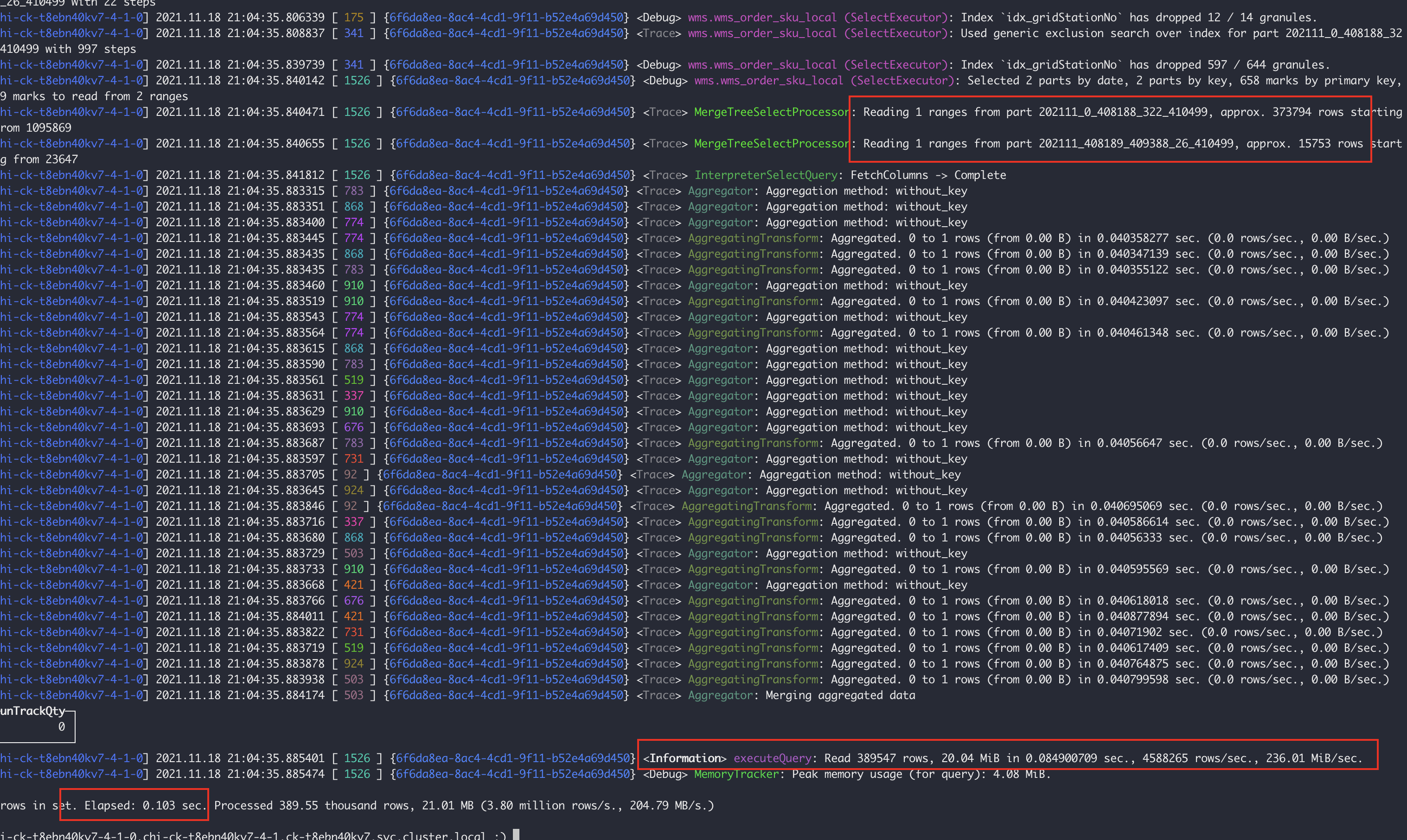
Sau khi thêm chỉ mục phụ, nút 7-4 đã quét 2 tệp phân vùng, tổng cộng 380.000 hàng, mất 0,103 giây.
7.3 Lỗi máy vật lý
Tình huống này rất hiếm nhưng đã từng xảy ra một lần.
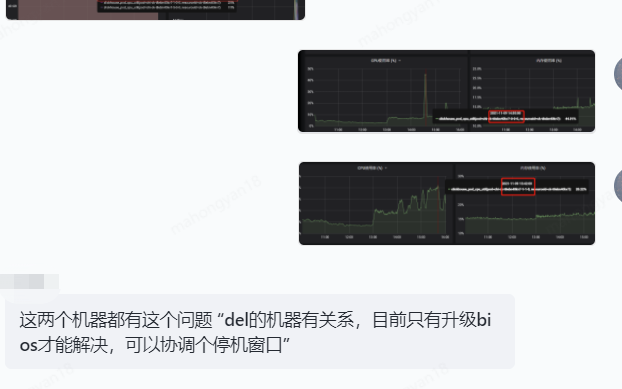
8 Làm thế nào để xác định SQL nào đang sử dụng CPU?
Tôi nghĩ có hai cách để khắc phục sự cố. Một là tần suất thực thi SQL có quá cao không và cách còn lại là xác định xem có lệnh SQL chậm nào đang được thực thi không. Thực thi tần suất cao hoặc truy vấn chậm sẽ tiêu tốn nhiều tài nguyên tính toán của CPU. Hai trường hợp sau minh họa hai phương pháp hiệu quả để khắc phục sự cố sử dụng CPU cao. Mặc dù hai phương pháp sau khác nhau về mặt hoạt động, cốt lõi của cả hai phương pháp là phân tích và xác định vị trí sự cố bằng cách phân tích query_log.
8.1 Grafana định vị SQL được thực hiện thường xuyên
Vào tháng 12, một số yêu cầu đã được đưa ra. Gần đây, người ta phát hiện ra rằng tỷ lệ sử dụng CPU tương đối cao. Cần phải tìm ra SQL nào đang gây ra điều đó.
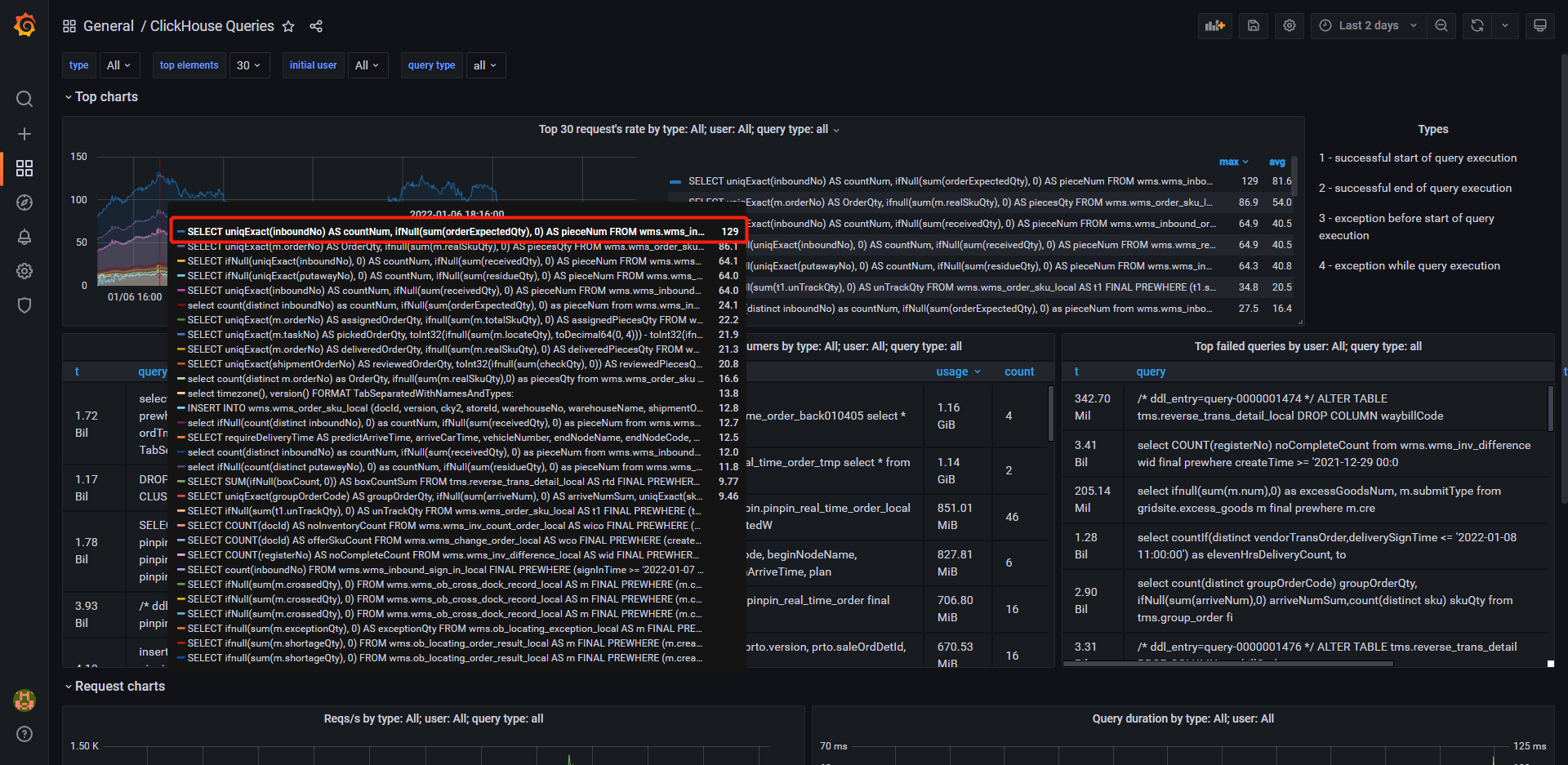
Có thể thấy từ bản giám sát grafana tự xây dựng trong hình trên (tài liệu xây dựng) rằng một số câu lệnh truy vấn được thực hiện rất thường xuyên. Thông qua SQL, logic mã giao diện truy vấn được định vị và thấy rằng giao diện front-end yêu cầu giao diện back-end thực hiện nhiều câu lệnh SQL có điều kiện tương tự, nhưng trạng thái nghiệp vụ lại khác nhau. Loại câu lệnh này yêu cầu số liệu thống kê của nhiều loại và trạng thái khác nhau, có thể được tối ưu hóa thông qua tổng hợp có điều kiện, được giải thích chi tiết trong Phần 9.4.1. Sau khi tối ưu hóa, tần suất thực hiện các câu lệnh được giảm đáng kể.
8.2 Số lượng hàng được quét cao/sử dụng bộ nhớ cao: phân tích query_log_all
Phần trước đã đề cập rằng tần suất thực thi SQL cao dẫn đến việc sử dụng CPU cao. Tôi phải làm gì nếu tần suất thực thi SQL rất thấp nhưng CPU vẫn rất cao? Tần suất thực thi SQL thấp và có thể có một số lượng lớn các hàng dữ liệu cần quét, tiêu tốn nhiều tài nguyên IO, bộ nhớ và CPU của đĩa. Trong trường hợp này, bạn cần sử dụng một phương pháp khác để khắc phục sự cố SQL rất tệ này (T⌓T).
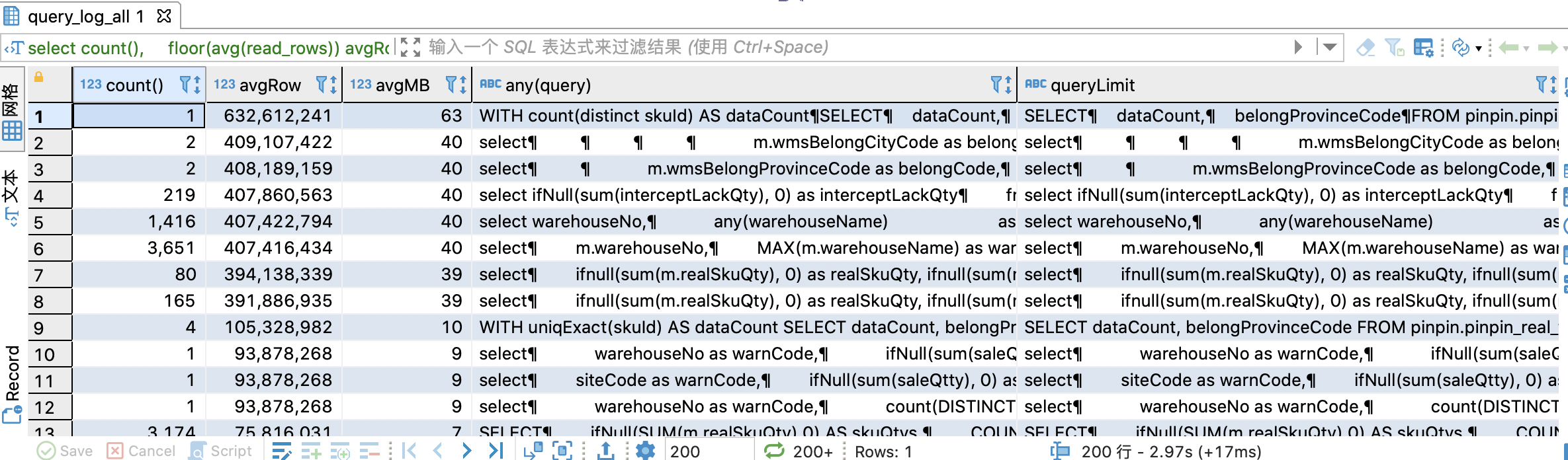
Bản thân ClickHouse có một bảng system.query_log, được sử dụng để ghi lại nhật ký thực thi của tất cả các câu lệnh. Hình sau đây cho thấy một số thông tin trường chính của bảng này.
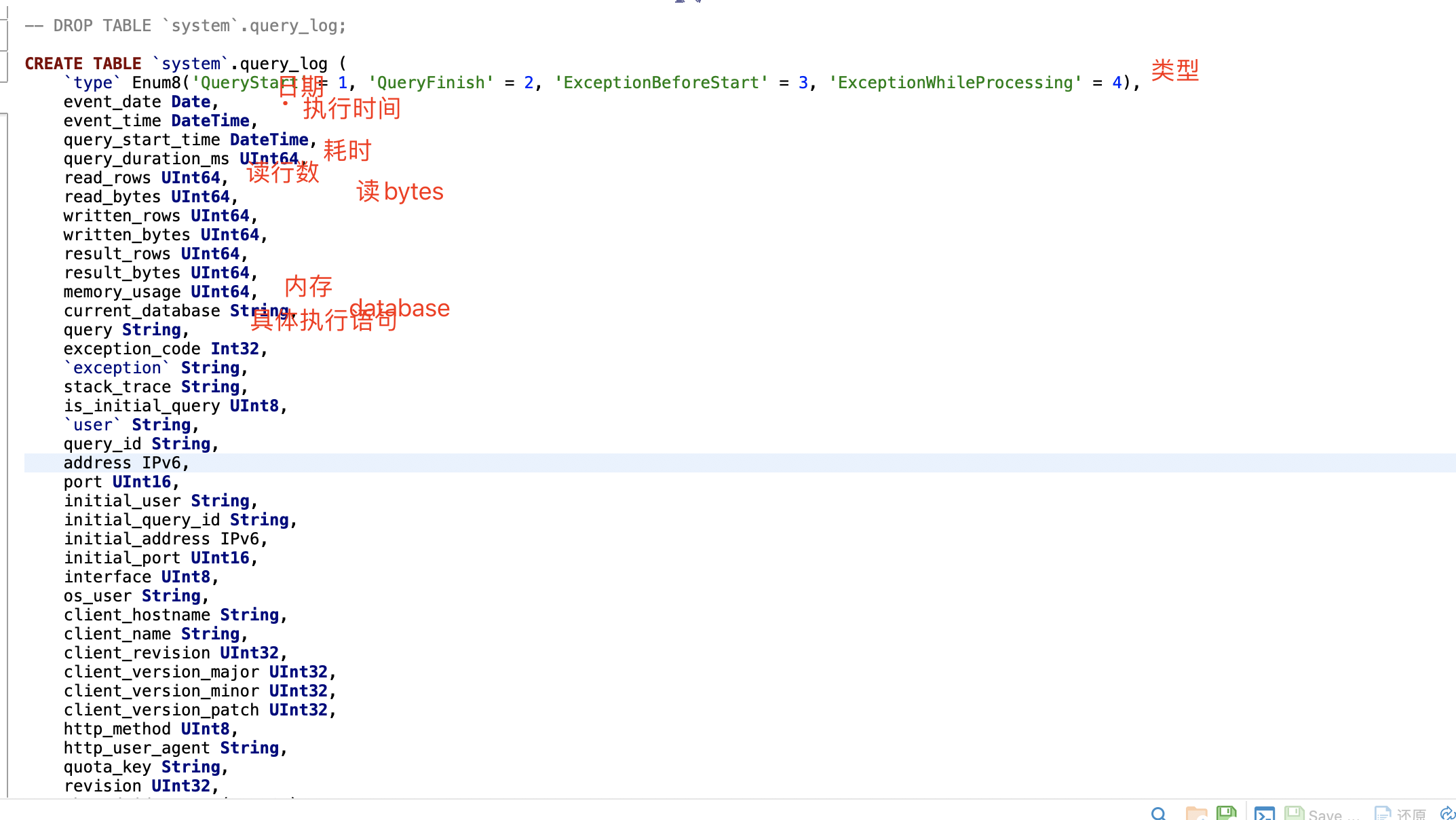
-- Tạo một bảng phân tán query_logCREATE TABLE IF NOT EXISTS system.query_log_allON CLUSTER defaultAS system.query_logENGINE = Distributed(sht_ck_cluster_pro,system,query_log,rand());-- Câu lệnh truy vấnselect -- Thời gian thực thicount(), -- Thời gian truy vấn trung bìnhavg(query_duration_ms)avgTime, -- Số lượng hàng trung bình được đọc mỗi timefloor(avg(read_rows))avgRow, -- Kích thước dữ liệu trung bình được đọc mỗi timefloor(avg(read_rows) / 10000000)avgMB, -- Câu lệnh truy vấn cụ thểany(query), -- Xóa điều kiện where và nhóm theo usersubstring(query, positionCaseInsensitive(query, 'select'), positionCaseInsensitive(query, 'from')) thành queryLimitfrom system.query_log_all/system.query_logwhere event_date = '2022-01-21' và loại = 2nhóm theo queryLimitorder theo avgRow desc;
query_log là một bảng cục bộ. Bạn cần tạo một bảng phân tán, truy vấn nhật ký truy vấn của tất cả các nút, sau đó thực thi câu lệnh phân tích truy vấn. Hiệu ứng thực thi được thể hiện trong hình bên dưới. Có thể thấy từ hình rằng số hàng trung bình được quét mỗi giây cho một số câu lệnh đã đạt tới 100 triệu. Những câu lệnh như vậy có thể có vấn đề. Bằng cách quét số lượng hàng, chúng ta có thể phân tích các câu lệnh vô lý như chỉ mục và điều kiện truy vấn. Việc sử dụng CPU cao của một nút trong 7.2 đã được giải quyết bằng cách xác định vị trí câu lệnh SQL có vấn đề theo cách này và sau đó tiếp tục điều tra.
9 Cách tối ưu hóa các truy vấn chậm
Tối ưu hóa SQL của ClickHouse tương đối đơn giản và phần lớn thời gian truy vấn được dành cho IO đĩa. Bạn có thể tham khảo thử nghiệm nhỏ này để hiểu rõ hơn. Hướng tối ưu hóa cốt lõi là giảm lượng dữ liệu được ClickHouse xử lý trong một truy vấn duy nhất, tức là giảm IO đĩa. Phần sau đây giới thiệu các phương pháp phân tích truy vấn chậm, phương pháp tối ưu hóa câu lệnh tạo bảng và một số phương pháp tối ưu hóa câu lệnh truy vấn.
9.1 Sử dụng nhật ký dịch vụ để phân tích truy vấn chậm
Mặc dù ClickHouse đã cung cấp EXPLAIN gốc để xem các kế hoạch truy vấn kể từ phiên bản 20.6, thông tin được cung cấp không hữu ích lắm đối với chúng tôi để tối ưu hóa SQL chậm. Trước phiên bản 20.6, với sự trợ giúp của nhật ký dịch vụ nền, chúng tôi có thể có thêm thông tin để phân tích. So với EXPLAIN, tôi thích sử dụng phương pháp service log để phân tích hơn. Phương pháp này yêu cầu sử dụng clickhouse-client để thực thi các câu lệnh SQL. Cuối bài viết có một tài liệu về việc xây dựng môi trường CK thông qua docker. Các phiên bản cao hơn của EXPLAIN cung cấp ESTIMATE, có thể truy vấn thông tin chi tiết như số phần được quét bởi các câu lệnh SQL và số hàng dữ liệu. Để biết chi tiết về cách sử dụng EXPLAIN, hãy tham khảo tài liệu chính thức. Sử dụng truy vấn chậm để phân tích và định vị SQL chậm sau thông qua query_log_all trong 8.2.
chọn ifNull(sum(interceptLackQty), 0) là interceptLackQtyfrom wms.wms_order_sku_local final prewhere productionEndTime = '2022-02-17 08:00:00' và orderType = '10' trong đó shipmentOrderDetailDeleted = '0' và ckContainerDetailDeleted = '0'
Sử dụng clickhouse-client và tham số send_logs_level chỉ định mức nhật ký dưới dạng theo dõi.
clickhouse-client -h địa chỉ --cổng cổng --người dùng tên người dùng --mật khẩu mật khẩu --send_logs_level=trace
Thực hiện SQL chậm ở trên trong máy khách và máy chủ sẽ in nhật ký sau. Khối lượng nhật ký lớn nên một số dòng bị bỏ qua mà không ảnh hưởng đến tính toàn vẹn của nhật ký tổng thể.
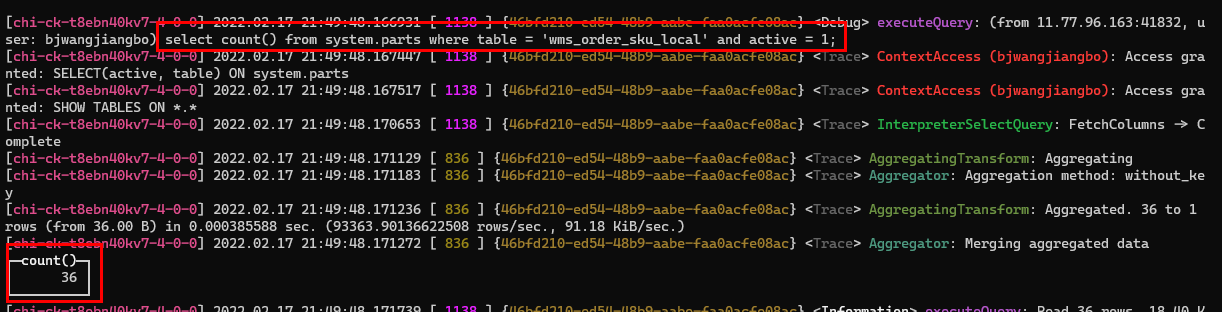
[chi-ck-t8ebn40kv7-3-0-0] 17/02/2022 21:21:54.036317 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} executeQuery: (từ 11.77.96.163:35988, người dùng: bjwangjiangbo) chọn ifNull(sum(interceptLackQty), 0) làm interceptLackQty từ wms.wms_order_sku_local final prewhere productionEndTime = '17/02/2022 08:00:00' và orderType = '10' trong đó shipmentOrderDetailDeleted = '0' và ckContainerDetailDeleted = '0'[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.037876 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} ContextAccess (bjwangjiangbo): Quyền truy cập được cấp: SELECT(orderType, interceptLackQty, productionEndTime, shipmentOrderDetailDeleted, ckContainerDetailDeleted) ON wms.wms_order_sku_local[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038239 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Điều kiện chính: không xác định, không xác định, và, không xác định, không xác định, và, và, không xác định, không xác định, và, và[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038271 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Điều kiện chỉ mục MinMax: không xác định, không xác định, và, không xác định, không xác định, và, và, không xác định, không xác định, và, và[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038399 [ 1340 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Không sử dụng chỉ mục chính trên phần 202101_0_0_0_3[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038475 [ 1407 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Không sử dụng chỉ mục chính trên phần 202103_0_17_2_22[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038491 [ 111 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Không sử dụng chỉ mục chính trên phần 202103_18_20_1_22..................................Bỏ qua một số dòng (khối này có nghĩa là: có sử dụng chỉ mục trong phân vùng hay không).................................................[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.039041 [ 1205 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Không sử dụng chỉ mục chính trên phần 202202_1723330_1723365_7[chi-ck-t8ebn40kv7-3-0-0] 17/02/2022 21:21:54.039054 [ 159 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Không sử dụng chỉ mục chính trên phần 202202_1723367_1723367_0[chi-ck-t8ebn40kv7-3-0-0] 17/02/2022 21:21:54.038928 [ 248 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Không sử dụng chỉ mục chính trên phần 202201_3675258_3700711_1054[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.039355 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Đã chọn 47 phần theo ngày, 47 phần theo khóa, 9471 điểm theo khóa chính, 9471 điểm để đọc từ 47 phạm vi[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.039495 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MergeTreeSelectProcessor: Đọc 1 phạm vi từ phần 202101_0_0_0_3, xấp xỉ 65536 hàng bắt đầu từ 0[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.039583 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MergeTreeSelectProcessor: Đọc 1 phạm vi từ phần 202101_0_0_0_3, xấp xỉ 16384 hàng bắt đầu từ 0[chi-ck-t8ebn40kv7-3-0-0] 17/02/2022 21:21:54.040291 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MergeTreeSelectProcessor: Đọc 1 phạm vi từ phần 202102_0_2_1_4, xấp xỉ 146850 hàng bắt đầu từ 0..................................Bỏ qua một số hàng (số hàng dữ liệu được đọc từ mỗi phân vùng)...................................[chi-ck-t8ebn40kv7-3-0-0] 17/02/2022 21:21:54.043538 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MergeTreeSelectProcessor: Đọc 1 phạm vi từ phần 202202_1723330_1723365_7, xấp xỉ 24576 hàng bắt đầu từ 0[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.043604 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MergeTreeSelectProcessor: Đọc 1 phạm vi từ phần 202202_1723366_1723366_0, xấp xỉ 8192 hàng bắt đầu từ 0[chi-ck-t8ebn40kv7-3-0-0] 17/02/2022 21:21:54.043677 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MergeTreeSelectProcessor: Đọc 1 phạm vi từ phần 202202_1723367_1723367_0, xấp xỉ 8192 hàng bắt đầu từ 0..................................Đã hoàn tất việc đọc dữ liệu, bắt đầu tính toán tổng hợp..................................[chi-ck-t8ebn40kv7-3-0-0] 17/02/2022 21:21:54.047880 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} InterpreterSelectQuery: FetchColumns -> Hoàn thành[chi-ck-t8ebn40kv7-3-0-0] 17/02/2022 21:21:54.263500 [ 1377 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} AggregatingTransform: Aggregating[chi-ck-t8ebn40kv7-3-0-0] 17/02/2022 21:21:54.263680 [ 1439 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} Aggregator: Phương pháp tổng hợp: without_key....................................Bỏ qua một số hàng (hoạt động tổng hợp được thực hiện sau khi hoàn tất việc đọc dữ liệu)...................................[chi-ck-t8ebn40kv7-3-0-0] 17/02/2022 21:21:54.263840 [ 156 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} AggregatingTransform: Đã tổng hợp. 12298 thành 1 hàng (từ 36,03 KiB) trong 0,215046273 giây (57187,69187876137 hàng/giây, 167,54 KiB/giây)[chi-ck-t8ebn40kv7-3-0-0] 17/02/2022 21:21:54.264283 [ 377 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} AggregatingTransform: Đã tổng hợp. 12176 thành 1 hàng (từ 35,67 KiB) trong 0,215476999 giây. (56507.191284950095 hàng/giây, 165,55 KiB/giây)[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.264307 [ 377 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} Aggregator: Đang hợp nhất tổng hợp data.................................Hoàn tất tính toán tổng hợp và trả về kết quả cuối cùng.................................┌─interceptLackQty─┐│ 563 │└────────────────────┘...................................Thời gian xử lý dữ liệu, tốc độ, hiển thị thông tin.................................[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.265490 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} executeQuery: Đọc 73645604 hàng, 1,20 GiB trong 0,229100749 giây, 321455099 hàng/giây, 5,22 GiB/giây.[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.265551 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MemoryTracker: Mức sử dụng bộ nhớ cao nhất (cho truy vấn): 60,37 MiB.1 hàng trong tập hợp. Đã trôi qua: 0,267 giây. Đã xử lý 73,65 triệu hàng, 1,28 GB (276,03 triệu hàng/giây, 4,81 GB/giây)
Bây giờ chúng ta hãy phân tích thông tin nào chúng ta có thể lấy được từ nhật ký trên. Đầu tiên, câu lệnh truy vấn không sử dụng chỉ mục khóa chính. Thông tin cụ thể như sau.
2022.02.17 21:21:54.038239 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Điều kiện chính: không xác định, không xác định, và, không xác định, không xác định, và, và, không xác định, không xác định, và, và.
Chỉ số phân vùng cũng không được sử dụng. Thông tin cụ thể như sau.
2022.02.17 21:21:54.038271 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Điều kiện chỉ mục MinMax: không xác định, không xác định và, không xác định, không xác định và, và, không xác định, không xác định và, và.
Truy vấn này quét tổng cộng 36 phần và 9390 MarkRange. Bằng cách truy vấn bảng thông tin phân vùng hệ thống system.parts, thấy rằng bảng hiện tại có tổng cộng 36 phân vùng đang hoạt động, tương đương với quét toàn bộ bảng.
2022.02.17 21:44:58.012832 [ 1138 ] {f1561330-4988-4598-a95d-bd12b15bc750} wms.wms_order_sku_local (SelectExecutor): Đã chọn 36 phần theo ngày, 36 phần theo khóa, 9390 điểm theo khóa chính, 9390 điểm để đọc từ 36 phạm vi.
Truy vấn này đọc tổng cộng 73645604 hàng dữ liệu, cũng là tổng số hàng trong bảng này. Thời gian đọc là 0,229100749 giây và tổng cộng 1,20 GB dữ liệu được đọc.
2022.02.17 21:21:54.265490 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} executeQuery: Đọc 73645604 hàng, 1,20 GiB trong 0,229100749 giây, 321455099 hàng/giây, 5,22 GiB/giây.
Bộ nhớ tối đa mà câu lệnh truy vấn này sử dụng là 60,37MB.
2022.02.17 21:21:54.265551 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MemoryTracker: Mức sử dụng bộ nhớ cao nhất (để truy vấn): 60,37 MiB.
Cuối cùng, thông tin sau được tóm tắt: truy vấn này mất tổng cộng 0,267 giây, xử lý dữ liệu 7365W, tổng cộng 1,28GB và đưa ra tốc độ xử lý dữ liệu.
1 hàng trong bộ. Đã trôi qua: 0,267 giây. Đã xử lý 73,65 triệu hàng, 1,28 GB (276,03 triệu hàng/giây, 4,81 GB/giây).
Từ những điều trên, chúng ta có thể tìm thấy hai vấn đề nghiêm trọng.
- Không sử dụng chỉ mục khóa chính: dẫn đến việc quét toàn bộ bảng
- Không sử dụng chỉ mục phân vùng: dẫn đến quét toàn bộ bảng
Do đó, cần phải thêm trường khóa chính hoặc chỉ mục phân vùng vào điều kiện truy vấn để tối ưu hóa.
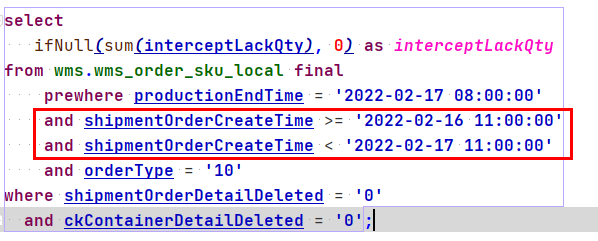
shipmentOrderCreateTime là khóa phân vùng. Chúng ta hãy xem hiệu ứng sau khi thêm điều kiện này.
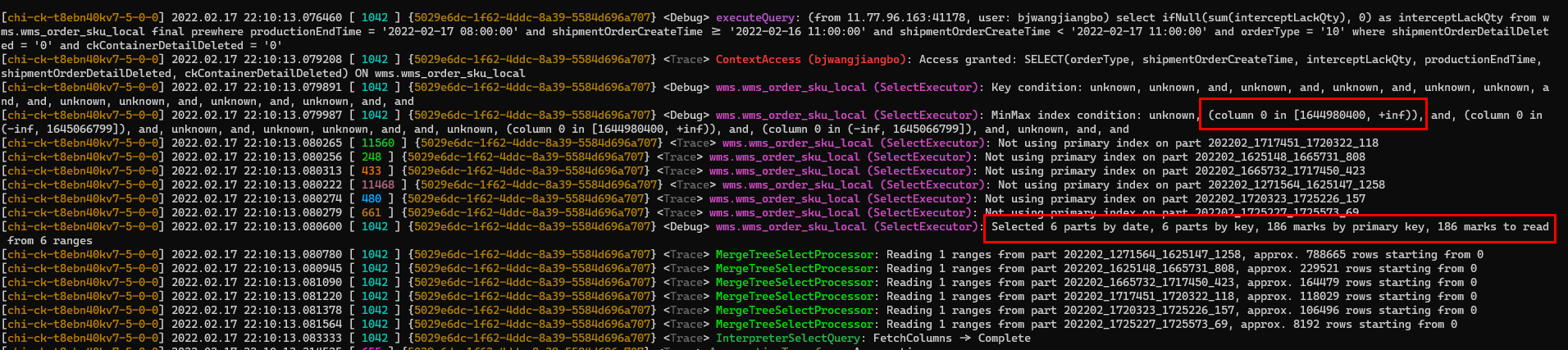

Phân tích nhật ký cho thấy chỉ mục khóa chính không được sử dụng, nhưng chỉ mục phân vùng được sử dụng. Số lượng phân đoạn được quét là 6, MarkRange là 186, tổng cộng 1.409.001 hàng dữ liệu được quét và sử dụng 40,76 MB bộ nhớ. Kích thước dữ liệu được quét được giảm đáng kể, tiết kiệm rất nhiều tài nguyên máy chủ và cải thiện tốc độ truy vấn, từ 0,267 giây xuống 0,18 giây.
9.2 Tối ưu hóa việc tạo bảng
9.2.1 Tránh sử dụng các kiểu Nullable
Trên thực tế, việc đặt thành Nullable không ảnh hưởng nhiều đến hiệu suất, có thể là do khối lượng dữ liệu của chúng ta tương đối nhỏ. Tuy nhiên, quan chức này đã chỉ rõ rằng bạn không nên sử dụng kiểu Nullable vì các trường Nullable không thể được lập chỉ mục và ngoài tệp lưu trữ các giá trị thông thường, cột Nullable sẽ có thêm một tệp để lưu trữ thẻ Null.
Việc sử dụng Nullable hầu như luôn ảnh hưởng tiêu cực đến hiệu suất, hãy lưu ý điều này khi thiết kế cơ sở dữ liệu của bạn.
TẠO BẢNG test_Nullable(orderNo String, number Nullable(Int16), createTime DateTime) ENGINE = MergeTree() PHÂN VÙNG THEO createTime THỨ TỰ THEO (orderNo) KHÓA CHÍNH (orderNo);
Lấy câu lệnh tạo bảng ở trên làm ví dụ, cột number sẽ tạo ra hai tệp bổ sung number.null.*, chiếm thêm không gian lưu trữ, trong khi cột orderNo không có tệp lưu trữ bổ sung nào cho dấu null.
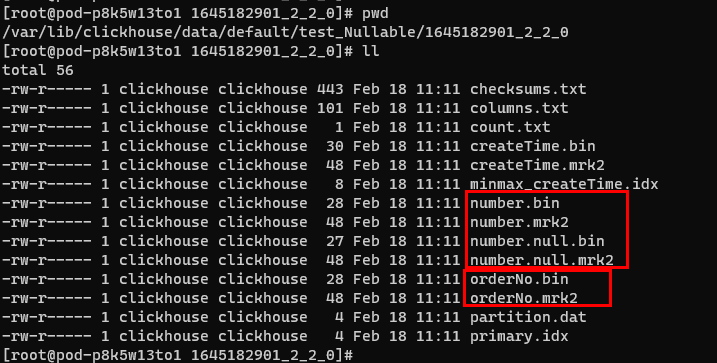
Khi chúng ta xây dựng các bảng trong các ứng dụng thực tế, chúng ta chắc chắn sẽ gặp phải các trường có thể là null. Trong trường hợp này, chúng ta có thể sử dụng một giá trị không thể xuất hiện làm giá trị mặc định. Ví dụ, nếu trường trạng thái là 0 hoặc cao hơn, chúng ta có thể đặt nó thành -1 làm giá trị mặc định thay vì sử dụng nullable.
9.2.2 Độ chi tiết phân vùng
Mức độ chi tiết của phân vùng phải được thiết lập theo đặc điểm của kịch bản kinh doanh và không được quá thô hoặc quá chi tiết. Dữ liệu của chúng tôi thường được phân chia chặt chẽ theo thời gian, do đó, nó được chia thành các phân vùng theo ngày hoặc tháng. Nếu độ chi tiết của chỉ mục quá nhỏ và được chia theo phút, giờ, v.v., một số lượng lớn các thư mục phân vùng sẽ được tạo ra. Không sử dụng trực tiếp PARTITION BY create_time, điều này sẽ dẫn đến số lượng phân vùng lớn đáng kinh ngạc. Hầu như mọi dữ liệu đều có một phân vùng, điều này sẽ ảnh hưởng nghiêm trọng đến hiệu suất. Nếu độ chi tiết chỉ mục quá thô, lượng dữ liệu trong một phân vùng đơn sẽ tương đối lớn. Vấn đề trong Mục 7.2 ở trên cũng liên quan đến độ chi tiết chỉ mục. Đối với phân vùng theo tháng, lượng dữ liệu trong một phân vùng đơn đạt tới 5 triệu cấp độ và phạm vi dữ liệu là từ cấp độ 1 đến cấp độ 18. Chỉ có dữ liệu từ cấp độ 17 và 18 được truy vấn. Tuy nhiên, sau khi tối ưu hóa phân vùng theo tháng, các phân vùng phải xử lý dữ liệu bổ sung không liên quan từ cấp độ 1 đến cấp độ 16 sau khi hợp nhất. Nếu các phân vùng được phân vùng theo ngày, sẽ không có sự đột biến CPU. Do đó, bạn nên tạo truy vấn theo đặc điểm kinh doanh của riêng mình và giữ nguyên tắc truy vấn chỉ xử lý dữ liệu trong phạm vi điều kiện truy vấn này và không xử lý dữ liệu không liên quan.
9.2.3 Chọn các quy tắc phân mảnh thích hợp cho các bảng phân tán
Lấy ví dụ 7.1 ở trên, các quy tắc phân mảnh được bảng phân tán chọn là không hợp lý, dẫn đến độ lệch dữ liệu nghiêm trọng rơi vào một vài phân mảnh. Sức mạnh tính toán của toàn bộ cụm cơ sở dữ liệu phân tán không được phát huy mà toàn bộ áp lực đều dồn vào một số ít máy. Theo cách này, hiệu suất của cụm tổng thể chắc chắn sẽ không được cải thiện, vì vậy chúng tôi chọn quy tắc phân mảnh phù hợp theo kịch bản kinh doanh. Ví dụ, chúng tôi tối ưu hóa sipHash64(warehouseNo) thành sipHash64(docId), trong đó docId là mã định danh duy nhất cho doanh nghiệp.
9.3 Kiểm tra hiệu suất và so sánh hiệu ứng tối ưu hóa
Trước khi nói về tối ưu hóa truy vấn, chúng ta hãy nói về một công cụ nhỏ, clickhouse-benchmark, một công cụ kiểm tra hiệu suất do clickhouse cung cấp. Môi trường giống như đã đề cập ở trên, sử dụng docker để xây dựng môi trường CK. Đối với các tham số kiểm tra ứng suất, vui lòng tham khảo tài liệu chính thức. Ở đây tôi sẽ đưa ra một ví dụ kiểm tra đồng thời đơn giản.
clickhouse-benchmark -c 1 -h địa chỉ liên kết --port số cổng --tài khoản người dùng --mật khẩu mật khẩu <<< "Câu lệnh SQL cụ thể"
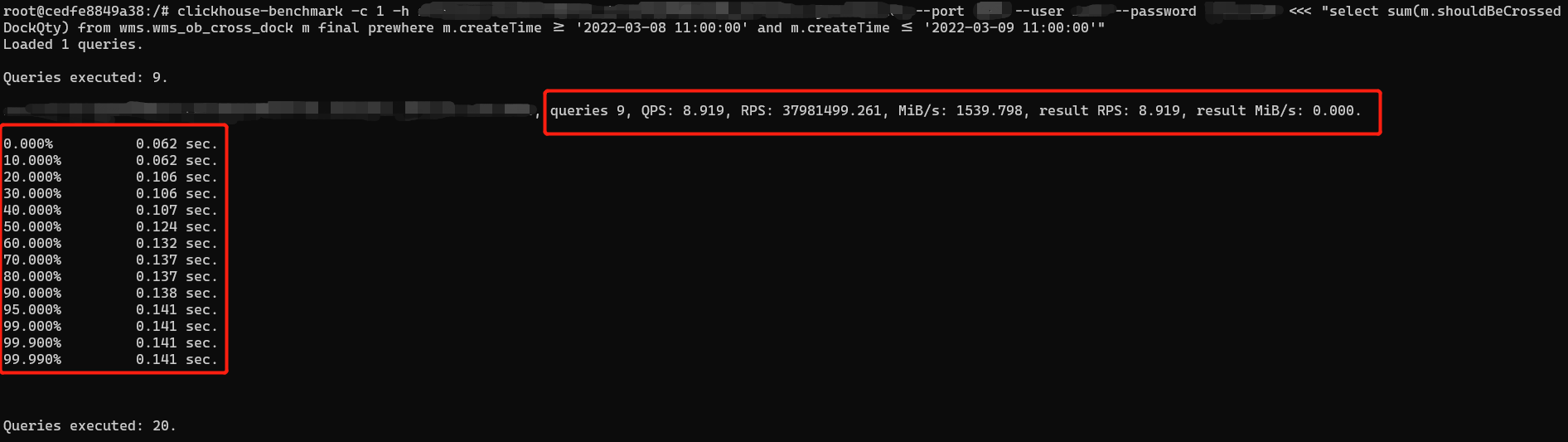
Theo cách này, bạn có thể hiểu thông tin QPS và TP99 ở cấp độ SQL, để bạn có thể kiểm tra sự khác biệt về hiệu suất trước và sau khi tối ưu hóa câu lệnh.
9.4 Tối ưu hóa truy vấn
9.4.1 Các hàm tổng hợp có điều kiện làm giảm số lượng hàng dữ liệu được quét
Giả sử một giao diện cần đếm "mặt hàng đến", "đơn hàng đi hợp lệ" và "mặt hàng đã xem xét" trong một ngày cụ thể.
-- Inbound quantityselect sum(qty) from table_1 final prewhere type = 'inbound' and dt = '2021-01-01';-- Hợp lệ outbound quantityselect count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2021-01-01' where and status = '1' ;-- Kiểm tra amountselect sum(qty) from table_1 final prewhere type = 'check' and dt = '2021-01-01';
Để xuất ra ba chỉ số từ một giao diện, ba câu lệnh SQL trên cần được hoàn thành bằng cách truy vấn table_1. Tuy nhiên, không khó để thấy rằng dt là nhất quán và sự khác biệt nằm ở hai điều kiện về loại và trạng thái. Giả sử dt = '2021-01-1' và mỗi truy vấn cần quét 1 triệu hàng dữ liệu, thì một yêu cầu giao diện sẽ quét 3 triệu hàng dữ liệu. Bằng cách tối ưu hóa hàm tổng hợp có điều kiện, ba truy vấn được thay đổi thành một và số lượng hàng được quét được giảm xuống còn 1 triệu hàng, điều này có thể tiết kiệm đáng kể tài nguyên tính toán của cụm.
select sumIf(qty, type = 'inbound'), -- Số lượng inbound countIf(distinct orderNo, type = 'outbound' và status = '1'), -- Số lượng outbound hợp lệ sumIf(qty, type = 'check') -- Kiểm tra số lượng prewhere dt = '2021-01-01';
Các hàm tổng hợp có điều kiện tương đối linh hoạt và có thể được sử dụng tự do theo tình hình kinh doanh của bạn. Hãy nhớ rằng mục đích là để giảm khối lượng quét tổng thể, có thể đạt được mục đích cải thiện hiệu suất truy vấn.
9.4.2 Chỉ số thứ cấp
Các công cụ bảng của họ MergeTree có thể chỉ định chỉ số đếm bước nhảy. Chỉ số hop có nghĩa là sau khi các mảnh dữ liệu được chia thành các khối nhỏ theo độ chi tiết (index_granularity được chỉ định khi tạo bảng), các khối nhỏ của granularity_value được kết hợp thành một khối lớn và thông tin chỉ mục được ghi vào các khối lớn này. Điều này giúp bỏ qua một lượng lớn dữ liệu không cần thiết khi sử dụng bộ lọc where và giảm lượng dữ liệu mà SELECT cần đọc.
TẠO BẢNG tên_bảng( u64 UInt64, i32 Int32, s Chuỗi, ... CHỈ MỤC a (u64 * i32, s) KIỂU minmax ĐỘ CHI TIẾT 3, CHỈ MỤC b (u64 * chiều dài(các)) KIỂU set(1000) ĐỘ CHI TIẾT 4) ENGINE = MergeTree()...
Chỉ mục trong ví dụ trên cho phép ClickHouse giảm lượng dữ liệu được đọc khi thực hiện các truy vấn sau.
CHỌN count() TỪ bảng NƠI s < 'z'CHỌN count() TỪ bảng NƠI u64 * i32 == 10 VÀ u64 * chiều dài >= 1234
Các loại chỉ mục được hỗ trợ.
- minmax: lưu trữ các giá trị min và max được tính toán bằng biểu thức đã chỉ định theo đơn vị chỉ mục chi tiết; trong các truy vấn giá trị và phạm vi bằng nhau, nó có thể giúp nhanh chóng bỏ qua các khối không đáp ứng yêu cầu và giảm IO.
- set(max_rows): lưu trữ tập giá trị riêng biệt của biểu thức được chỉ định theo đơn vị chỉ mục chi tiết, được sử dụng để nhanh chóng xác định xem truy vấn giá trị bằng nhau có chạm đến khối và giảm IO hay không.
- ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed): xây dựng bộ lọc bloom sau khi thực hiện phân đoạn ngram trên chuỗi, có thể tối ưu hóa các điều kiện truy vấn như bằng nhau, giống và trong.
- tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed): Tương tự như ngrambf_v1, nhưng thay vì sử dụng ngram để phân đoạn từ, nó sử dụng dấu chấm câu để phân đoạn từ.
- bloom_filter([false_positive]): Xây dựng bộ lọc bloom cho cột được chỉ định để tăng tốc độ thực thi các điều kiện truy vấn như bằng nhau, giống nhau và trong.
Ví dụ về việc tạo chỉ mục phụ.
Thay đổi bảng wms.wms_order_sku_local TRÊN cụm mặc định THÊM CHỈ MỤC thuộc vềProvinceCode_idx thuộc vềProvinceCode KIỂU set(0) ĐỘ CHI TIẾT 5;Thay đổi bảng wms.wms_order_sku_local TRÊN cụm mặc định THÊM CHỈ MỤC productionEndTime_idx productionEndTime KIỂU minmax ĐỘ CHI TIẾT 5;
Xây dựng lại dữ liệu chỉ mục phân vùng: Dữ liệu được chèn trước khi tạo chỉ mục phụ không thể được sử dụng cho chỉ mục phụ. Dữ liệu chỉ mục của mỗi phân vùng phải được xây dựng lại trước khi có hiệu lực.
-- Nối tất cả các câu lệnh MATERIALIZE của các phân vùng dữ liệu select concat('alter table wms.wms_order_sku_local on cluster default ', 'MATERIALIZE INDEX productionEndTime_idx in PARTITION '||partition_id||',')from system.partswhere database = 'wms' and table = 'wms_order_sku_local'group by partition_id-- Thực thi tất cả các câu lệnh MATERIALIZE được truy vấn trong SQL ở trên để xây dựng lại dữ liệu chỉ mục phân vùng
9.4.3 final thay thế argMax để loại bỏ trùng lặp
So sánh sự khác biệt về hiệu suất giữa final và argMax, như được hiển thị trong SQL sau.
-- phương thức cuối cùng select count(distinct groupOrderCode), sum(arriveNum), count(distinct sku) từ tms.group_order final prewhere siteCode = 'WG0001544' và createTime >= '2022-03-14 22:00:00' và createTime <= '2022-03-15 22:00:00' trong đó arriveNum > 0 và test <> '1'-- phương thức argMax select count(distinct groupOrderCode), sum(arriveNumTemp), count(distinct sku) từ (select argMax(groupOrderCode,version) là groupOrderCode, argMax(arriveNum,version) là arriveNumTemp, argMax(sku,version) là sku từ tms.group_order prewhere siteCode = 'WG0001544' và createTime >= '2022-03-14 22:00:00' và createTime <= '2022-03-15 22:00:00' trong đó arriveNum > 0 và test <> '1' nhóm theo docId)
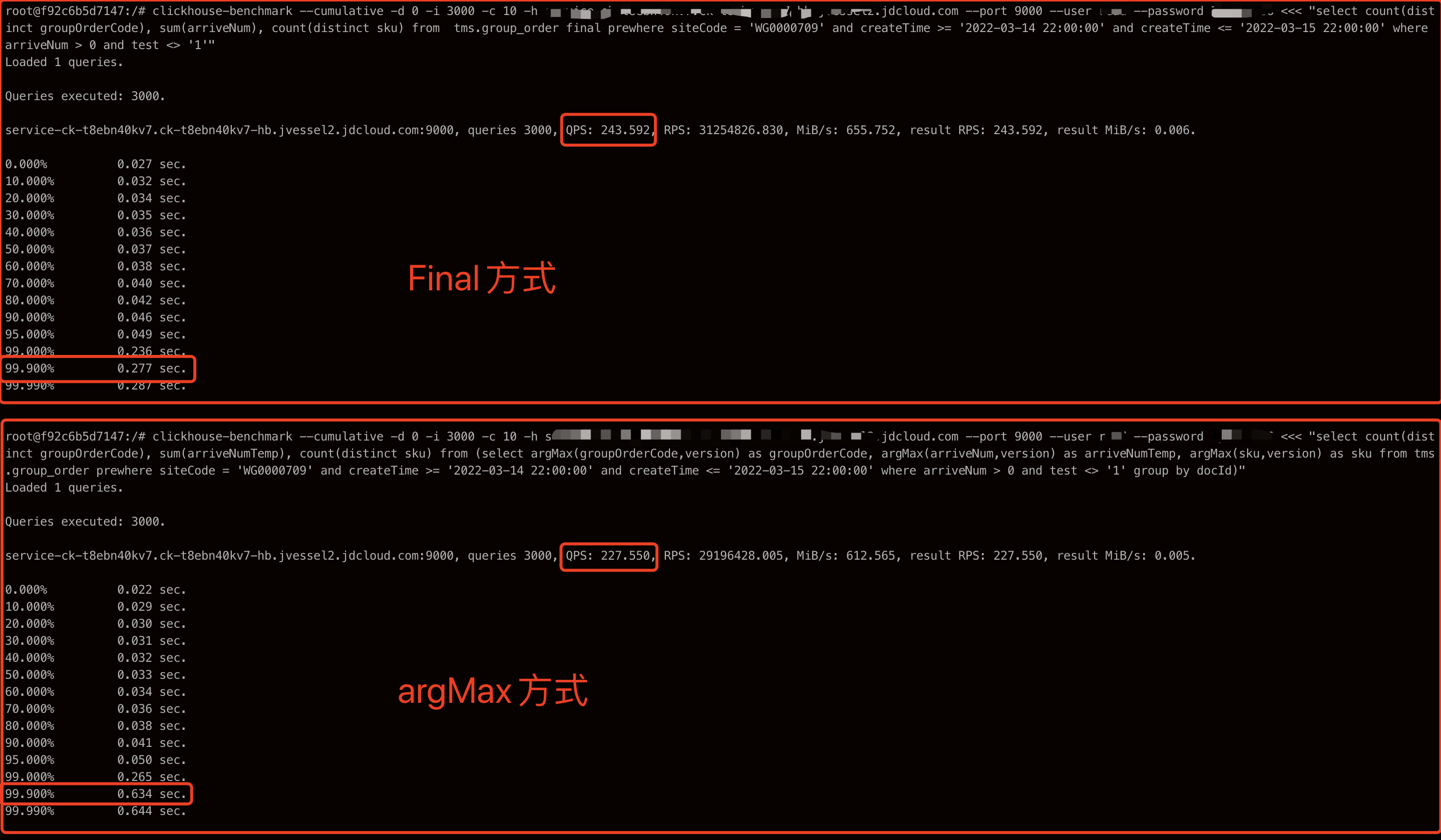
TP99 của phương pháp cuối cùng rõ ràng tốt hơn nhiều so với phương pháp argMax.
9.4.4 Prewhere thay vì where
Cú pháp của ClickHouse hỗ trợ các điều kiện lọc prewhere bổ sung, được đánh giá trước các điều kiện where. Chúng có thể được coi là hiệu quả hơn các điều kiện where và chức năng của chúng là lọc dữ liệu. Khi điều kiện lọc prewhere được thêm vào điều kiện lọc của SQL, quá trình quét lưu trữ được thực hiện theo hai giai đoạn. Đầu tiên, khối lưu trữ giá trị cột mà biểu thức prewhere phụ thuộc vào được đọc để kiểm tra xem có bản ghi nào đáp ứng điều kiện hay không. Sau đó, các cột khác đáp ứng điều kiện được đọc ra. Lấy SQL sau làm ví dụ. Phương thức prewhere trước tiên sẽ quét các trường type và dt và lấy ra các cột đáp ứng điều kiện. Khi không có bản ghi nào đáp ứng điều kiện, dữ liệu của các cột khác có thể bị bỏ qua. Điều này tương đương với việc thu hẹp thêm phạm vi quét dựa trên Phạm vi đánh dấu. So với where, prewhere xử lý ít dữ liệu hơn và có hiệu suất cao hơn. Đoạn văn này có thể không dễ hiểu.
-- Phương pháp thông thường select count(distinct orderNo) final from table_1 where type = 'outbound' và status = '1' và dt = '2021-01-01';-- Phương pháp prewhere select count(distinct orderNo) final from table_1 prewhere type = 'outbound' và dt = '2021-01-01' where và status = '1';
Ở phần trước, chúng ta đã nói về việc sử dụng final để tối ưu hóa loại bỏ trùng lặp. Có một cạm bẫy cần lưu ý khi sử dụng final để loại bỏ các bản sao và sử dụng prewhere để tối ưu hóa các điều kiện truy vấn. Prewhere sẽ được thực thi trước final. Do đó, trong quá trình xử lý trường giá trị biến như trạng thái, các hàng dữ liệu ở trạng thái trung gian có thể được truy vấn, dẫn đến dữ liệu cuối cùng không nhất quán.

Như hình trên cho thấy, dữ liệu nghiệp vụ của docId:123_1 được ghi ba lần, và dữ liệu có phiên bản = 103 là phiên bản mới nhất. Khi chúng ta sử dụng where để lọc trường giá trị biến status, kết quả của câu lệnh 1 và câu lệnh 2 như sau.
--Câu lệnh 1: Sử dụng where + status=1 để truy vấn, hàng dữ liệu docId:123_1 không thể bị tấn công. select count(distinct orderNo) final from table_1 where type = 'outbound' and dt = '2021-01-01' and status = '1'; --Câu lệnh 2: Sử dụng where + status=2 để truy vấn, hàng dữ liệu docId:123_1 có thể bị truy vấn. select count(distinct orderNo) final from table_1 where type = 'outbound' and dt = '2021-01-01' and status = '2';
Sau khi chúng ta giới thiệu prewhere, câu lệnh 3 được viết như sau: khi prewhere lọc trường trạng thái, dữ liệu có trạng thái = 1 và phiên bản = 102 sẽ bị lọc ra, dẫn đến kết quả truy vấn không chính xác. Cách viết đúng là câu lệnh 2, sử dụng prewhere để tối ưu hóa trường bất biến.
-- Câu lệnh 3: Sai cách, đặt trạng thái trong prewhereselect count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2021-01-01' and status = '1';-- Câu lệnh 4: Sửa phương thức prewhere, đặt biến trạng thái field trong whereselect count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2021-01-01' where and status = '1';
Những hạn chế khác: prewhere hiện chỉ khả dụng cho chuỗi công cụ bảng MergeTree.
9.4.5 Cắt tỉa cột và cắt tỉa phân vùng
ClickHouse rất phù hợp để lưu trữ các bảng có khối lượng dữ liệu lớn, vì vậy chúng ta nên tránh sử dụng thao tác SELECT *, đây là thao tác có tác động rất lớn. Nên cắt bớt các cột để chỉ chọn những cột bạn cần, vì càng ít trường thì tài nguyên IO tiêu tốn càng ít và do đó hiệu suất càng cao. Cắt tỉa phân vùng là chỉ đọc các phân vùng cần thiết và kiểm soát phạm vi truy vấn của các trường phân vùng.
9.4.6 trong đó, nhóm theo thứ tự
Thứ tự các cột trong where và group by phải nhất quán với thứ tự các cột trong câu lệnh tạo bảng và phải được đặt ở phía trước để chúng có tiền tố chung liên tục, nếu không sẽ ảnh hưởng đến hiệu suất truy vấn.
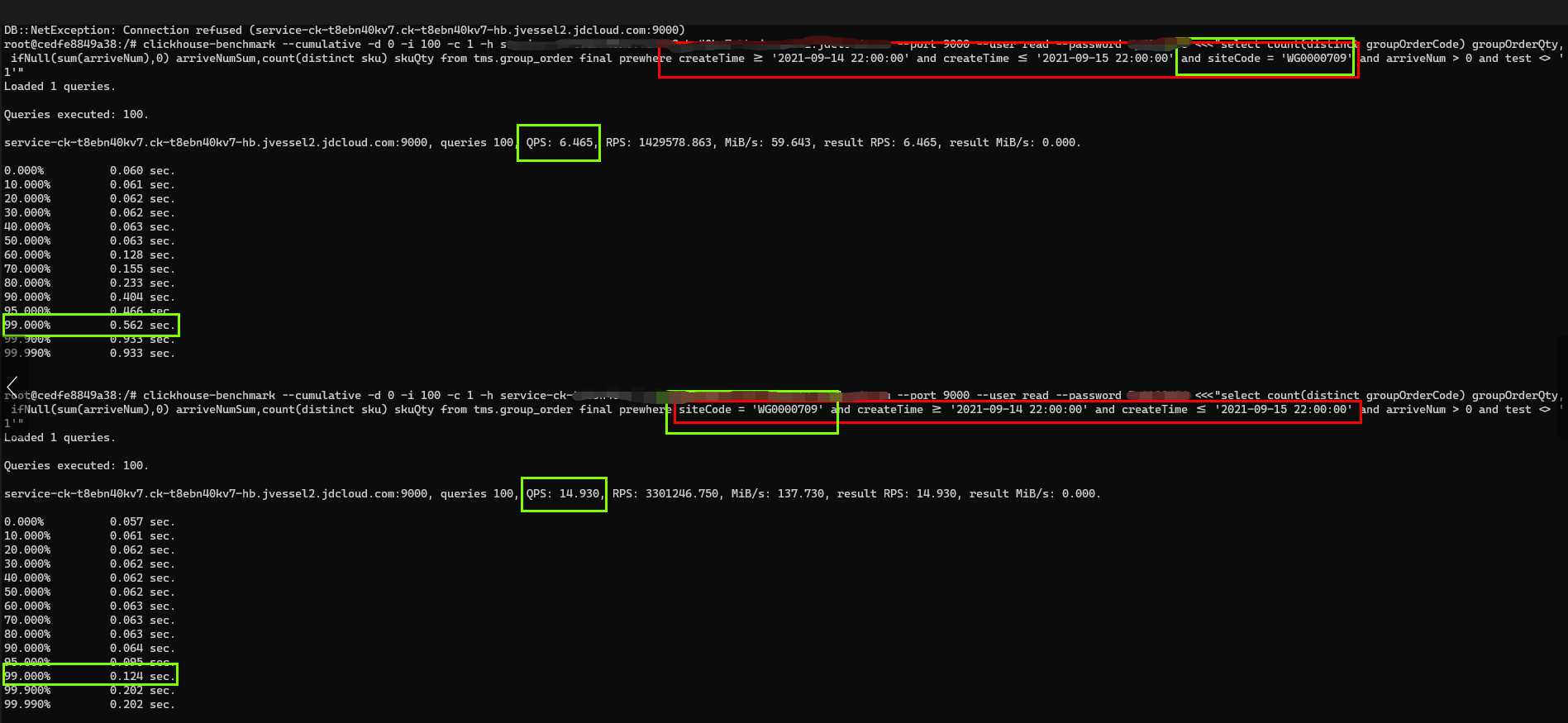
-- Câu lệnh tạo bảng create table group_order_local( docId String, version UInt64, siteCode String, groupOrderCode String, sku String, ... Bỏ qua các trường không phải khóa... createTime DateTime) engine = ReplicatedReplacingMergeTree('/clickhouse/tms/group_order/{shard}', '{replica}', version)PARTITION BY toYYYYMM(createTime)ORDER BY (siteCode, groupOrderCode, sku);--Câu lệnh truy vấn 1select count(distinct groupOrderCode) groupOrderQty, ifNull(sum(arriveNum),0) arriveNumSum,count(distinct sku) skuQtyfrom tms.group_order finalprewhere createTime >= '2021-09-14 22:00:00' và createTime <= '2021-09-15 22:00:00'và siteCode = 'WG0000709'trong đó arriveNum > 0 và test <> '1'--Câu lệnh truy vấn 2 (trường trong where/prewhere)select count(distinct groupOrderCode) groupOrderQty, ifNull(sum(arriveNum),0) arriveNumSum,count(distinct sku) skuQtyfrom tms.group_order finalprewhere siteCode = 'WG0000709' và createTime >= '2021-09-14 22:00:00' và createTime <= '2021-09-15 22:00:00'trong đó arriveNum > 0 và test <> '1'
Câu lệnh tạo bảng ORDER BY (siteCode, groupOrderCode, sku), câu lệnh 1 không đáp ứng các yêu cầu và vượt qua bài kiểm tra ứng suất với QPS6.4, TP99 0,56 giây, trong khi câu lệnh 2 đáp ứng các yêu cầu và vượt qua bài kiểm tra ứng suất với QPS 14.9, TP99 0,12 giây.
10 Cách chịu được mức độ đồng thời cao và đảm bảo tính khả dụng của ClickHouse
1) Giảm tốc độ truy vấn và cải thiện thông lượng.
max_threads: Nằm trong users.xml, chỉ ra số lượng CPU tối đa có thể được sử dụng cho một truy vấn duy nhất. Giá trị mặc định là số lõi CPU. Nếu máy là 32C, 32 luồng sẽ được bắt đầu để xử lý yêu cầu hiện tại. Bạn có thể giảm max_threads, hy sinh tốc độ của một truy vấn duy nhất để đảm bảo tính khả dụng của ClickHouse và cải thiện khả năng đồng thời. Có thể cấu hình thông qua url jdbc.

Hình sau là bài kiểm tra ứng suất dựa trên cấu hình 32C128G, đảm bảo cụm CK có thể cung cấp dịch vụ ổn định với mức sử dụng CPU là 50% và được thực hiện trên max_threads. Đây là bài kiểm tra ứng suất cấp giao diện, với 5 câu lệnh SQL được thực thi cho mỗi yêu cầu và 5,08W hàng dữ liệu được xử lý. Có thể thấy rằng max_threads càng nhỏ thì QPS càng tốt và TP99 càng tệ. Bạn có thể điều chỉnh giá trị cấu hình phù hợp theo tình hình kinh doanh của mình.

2) Giao diện thêm một khoảng thời gian bộ nhớ đệm nhất định. 3) Nhiệm vụ không đồng bộ thực thi câu lệnh truy vấn, đưa kết quả chỉ báo tổng hợp vào ES và áp dụng truy vấn vào kết quả tổng hợp trong ES. 4) Chế độ xem vật chất hóa giải quyết vấn đề này bằng cách tổng hợp trước, nhưng không áp dụng được cho tình huống kinh doanh của chúng tôi.
11 Thu thập dữ liệu
• Các hoạt động như xây dựng cơ sở dữ liệu, tạo bảng và tạo chỉ mục phụ.
• Thay đổi các trường ORDER BY, PARTITION BY, sao lưu dữ liệu, di chuyển dữ liệu trong một bảng duy nhất, v.v.
• Xây dựng clickhouse-client dựa trên docker để liên kết với cụm ck.
• Xây dựng grafana dựa trên docker để theo dõi việc thực thi SQL.
• Tự xây dựng clickhouse trong môi trường thử nghiệm.
Tác giả: Ma Hongyan từ JD Logistics.
Nguồn nội dung: Cộng đồng nhà phát triển JD Cloud.
Cuối cùng, bài viết này về bài viết dài 10.000 từ nêu chi tiết về việc khám phá và thực hành dữ liệu thời gian thực của ClickHouse tại Bắc Kinh Xida đã kết thúc. Nếu bạn muốn biết thêm về bài viết dài 10.000 từ nêu chi tiết về việc khám phá và thực hành dữ liệu thời gian thực của ClickHouse tại Bắc Kinh Xida, vui lòng tìm kiếm các bài viết của CFSDN hoặc tiếp tục duyệt các bài viết liên quan. Tôi hy vọng bạn sẽ ủng hộ blog của tôi trong tương lai! .

 Trung tâm cá nhân
Trung tâm cá nhân Bài viết phát hành
Bài viết phát hành



 4
4



Tôi là một lập trình viên xuất sắc, rất giỏi!