Khi sử dụng MySQL để chèn dữ liệu, bạn có thể chọn câu lệnh chèn phù hợp theo kịch bản nhu cầu, chẳng hạn như cách chèn dữ liệu khi dữ liệu lặp lại, cách nhập dữ liệu từ bảng khác, cách chèn dữ liệu theo đợt, v.v. Bài viết này giải thích quy trình triển khai và phương pháp chèn dữ liệu bằng cách đưa ra các ví dụ trong từng tình huống sử dụng.
1. Phân loại phương pháp
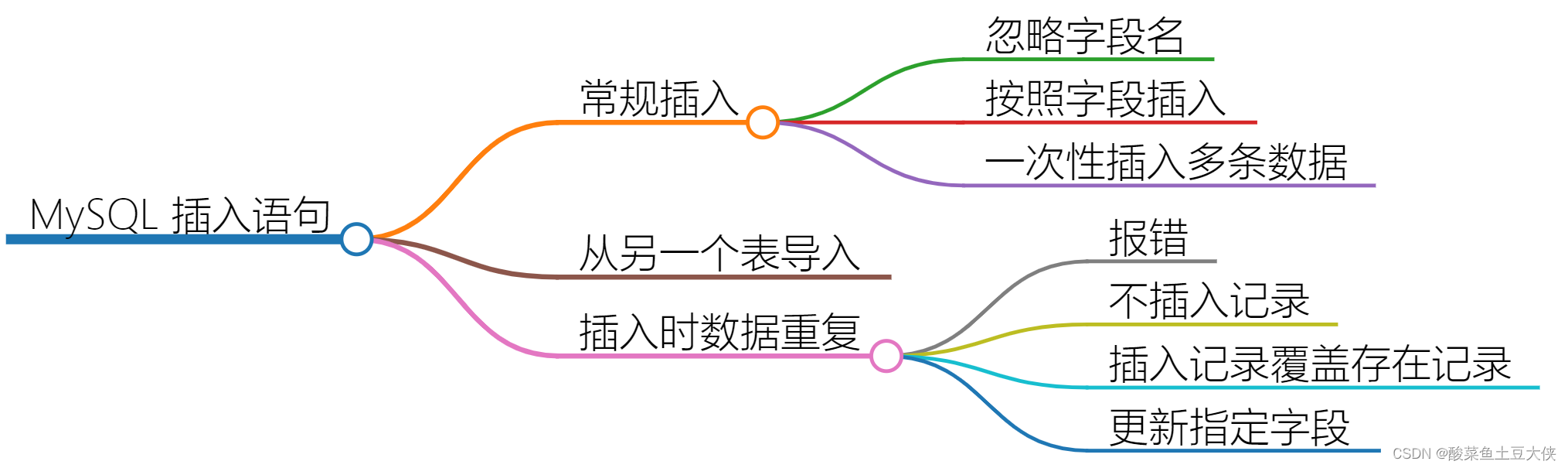
2.Phương pháp cụ thể
| kịch bản sử dụng |
tác dụng |
tuyên bố |
Để ý |
| chèn thường xuyên |
| Bỏ qua tên trường |
| chèn vào các giá trị tên bảng (giá trị 1, giá trị 2,..., giá trị n) |
Các giá trị trong giá trị mặc định sẽ điền vào tất cả các từ theo trình tự. Nếu xảy ra xung đột về tính duy nhất, một ngoại lệ sẽ được đưa ra. |
| Chèn theo trường |
| chèn vào tên bảng (trường 1, trường 2,..., trường n) các giá trị (giá trị 1, giá trị 2,..., giá trị n) |
Sự tương ứng một-một giữa các trường và giá trị |
| Chèn nhiều phần dữ liệu cùng một lúc |
| chèn vào tên bảng (field 1, field 2,..., field n) các giá trị (value a1, value a2,..., value an), (value b1, value b2,..., value bn) |
Phân tách nhiều dòng bằng dấu phẩy, do đó không cần phải viết lại câu lệnh chèn vào. |
| Nhập từ bảng khác |
Xuất một số dữ liệu từ bảng A và chèn nó vào bảng B |
chèn vào tên bảng B (trường B1, trường B2,..., trường Bn) chọn trường A1, trường A2,..., trường An từ tên bảng A trong đó [điều kiện thực hiện] |
Trường A và B có thể có tên trường khác nhau nhưng kiểu dữ liệu phải nhất quán. |
| Dữ liệu trùng lặp khi chèn |
| Nếu có sai sót trong hồ sơ |
| chèn vào tên bảng (trường 1, trường 2,..., trường n) các giá trị (giá trị 1, giá trị 2,..., giá trị n) |
Nếu bản ghi dữ liệu được chèn tồn tại, một lỗi sẽ được báo cáo và ngoại lệ sẽ bị bắt. Nếu nó không tồn tại, bản ghi sẽ được thêm trực tiếp. |
| Không chèn bản ghi nếu nó tồn tại |
| chèn các giá trị bỏ qua vào tên bảng (trường 1, trường 2,..., trường n) (giá trị 1, giá trị 2,..., giá trị n) |
Nếu bản ghi dữ liệu được chèn tồn tại, bản ghi cũ sẽ được lưu và bản ghi mới sẽ bị bỏ qua. Nếu nó không tồn tại, bản ghi mới sẽ được thêm trực tiếp. |
| Chèn bản ghi bất kể chúng có tồn tại hay không |
| thay thế các giá trị tên bảng (trường 1, trường 2,..., trường n) (giá trị 1, giá trị 2,..., giá trị n) |
Nếu bản ghi dữ liệu được chèn tồn tại, hãy xóa nó trước rồi cập nhật nó. Nếu nó không tồn tại, hãy thêm bản ghi trực tiếp. |
| Nếu bản ghi tồn tại, hãy cập nhật trường được chỉ định |
| chèn vào … trên bản cập nhật khóa trùng lặp |
Nếu bản ghi dữ liệu được chèn tồn tại, hãy cập nhật trường được chỉ định. Nếu nó không tồn tại, hãy thêm bản ghi trực tiếp. |
3. Ví dụ
bảng sinh viên (id đại diện cho khóa chính, tên là tên và điểm là điểm trung bình).
| nhận dạng |
tên |
điểm |
| 1 |
Lý Minh |
67 |
(1) Chèn thông thường
chèn vào các giá trị của sinh viên(null, 'Zhang San', '74');
Kết quả sau khi thực hiện.
| nhận dạng |
tên |
điểm |
| 1 |
Lý Minh |
67 |
| 2 |
Trương Tam |
74 |
chèn vào giá trị của học sinh(tên)('孙华');
Kết quả sau khi thực hiện.
| nhận dạng |
tên |
điểm |
| 1 |
Lý Minh |
67 |
| 2 |
Trương Tam |
74 |
| 3 |
Tôn Hoa |
|
- Chèn nhiều phần dữ liệu cùng một lúc
chèn vào các giá trị của học sinh(tên, điểm)('Liu Ping', '56'),('Zhou Yu', '90');
Kết quả sau khi thực hiện.
| nhận dạng |
tên |
điểm |
| 1 |
Lý Minh |
67 |
| 2 |
Trương Tam |
74 |
| 3 |
Tôn Hoa |
|
| 4 |
Lưu Bình |
56 |
| 5 |
Chu Du |
90 |
(2) Nhập từ bảng khác
bảng sinh viên (id đại diện cho khóa chính, tên là tên và điểm là điểm trung bình).
| nhận dạng |
tên người dùng |
số_điện_thoại_di_động |
| 1 |
Mã Hóa Đằng |
13800000000 |
| 2 |
Nhậm Chính Phi |
13800000011 |
| 3 |
Jack Ma |
13800000022 |
- Xuất một số dữ liệu từ bảng người dùng và chèn nó vào bảng sinh viên
chèn vào học sinh(tên,điểm) chọn tên người dùng, số điện thoại di động từ những người dùng có id <> 3;
Kết quả thực hiện.
| nhận dạng |
tên |
điểm |
| 1 |
Lý Minh |
67 |
| 2 |
Trương Tam |
74 |
| 3 |
Tôn Hoa |
|
| 4 |
Lưu Bình |
56 |
| 5 |
Chu Du |
90 |
| 6 |
Mã Hóa Đằng |
13800000000 |
| 7 |
Jack Ma |
13800000022 |
Lưu ý: Miễn là các trường tương ứng có cùng loại, dữ liệu có thể được nhập ngay cả khi các trường khác nhau mà không bị xung đột.
(3) Sao chép dữ liệu trong quá trình chèn
- Nếu có sai sót trong hồ sơ
chèn vào giá trị của sinh viên(1, 'Zhang San', '74');
Kết quả thực hiện: báo lỗi.
Mục nhập trùng lặp '1' cho khóa 'PRIMARY'
- Không chèn bản ghi nếu nó tồn tại
chèn bỏ qua vào giá trị của học sinh (id, tên, điểm) (1, '张三', '74');
Kết quả thực hiện: Không chèn và không có lỗi.
Hàng bị ảnh hưởng: 0
| nhận dạng |
tên |
điểm |
| 1 |
Lý Minh |
67 |
| 2 |
Trương Tam |
74 |
| 3 |
Tôn Hoa |
|
| 4 |
Lưu Bình |
56 |
| 5 |
Chu Du |
90 |
| 6 |
Mã Hóa Đằng |
13800000000 |
| 7 |
Jack Ma |
13800000022 |
- Chèn bản ghi bất kể chúng có tồn tại hay không
thay thế giá trị của sinh viên(1, 'Zhang San', '74');
Kết quả thực hiện.
| nhận dạng |
tên |
điểm |
| 1 |
Trương Tam |
74 |
| 2 |
Trương Tam |
74 |
| 3 |
Tôn Hoa |
|
| 4 |
Lưu Bình |
56 |
| 5 |
Chu Du |
90 |
| 6 |
Mã Hóa Đằng |
13800000000 |
| 7 |
Jack Ma |
13800000022 |
- Nếu bản ghi tồn tại, hãy cập nhật trường được chỉ định
chèn vào giá trị (1) của học sinh trên khóa trùng lặp cập nhật tên = '李明', điểm = '67';
Kết quả thực hiện.
| nhận dạng |
tên |
điểm |
| 1 |
Lý Minh |
67 |
| 2 |
Trương Tam |
74 |
| 3 |
Tôn Hoa |
|
| 4 |
Lưu Bình |
56 |
| 5 |
Chu Du |
90 |
| 6 |
Mã Hóa Đằng |
13800000000 |
| 7 |
Jack Ma |
13800000022 |
Code tạo bảng sinh viên.
-- ---------------------------- -- Cấu trúc bảng cho sinh viên -- ---------------------------- DROP TABLE IF EXISTS `students`; CREATE TABLE `students` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '学生id', `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '姓名', `score` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '成绩', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Hồ sơ học sinh -- ---------------------------- INSERT INTO `students` VALUES (1, '李明', '67');
Mã để tạo bảng người dùng.
-- ---------------------------- -- Cấu trúc bảng cho sinh viên -- ---------------------------- DROP TABLE IF EXISTS `users`; CREATE TABLE `users` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Người dùng id', `user_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT 'Người dùng', `mobile_phone_number` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT 'Người dùng', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Hồ sơ của học sinh -- ---------------------------- CHÈN VÀO GIÁ TRỊ `người dùng` (1, '马化腾', '13800000000'); CHÈN VÀO GIÁ TRỊ `người dùng` (2, '任正非', '13800000011'); CHÈN VÀO GIÁ TRỊ `người dùng` (3, '马云', '13800000022');
4. Những điều cần lưu ý
(1) Không ghi tên trường, bạn cần điền ID tăng tự động
- [Sử dụng]: 0 hoặc null hoặc mặc định, ID tăng tự động bắt đầu từ 1 theo mặc định.
- [Sử dụng]: Hoặc số (không lặp lại) không xuất hiện trong ID tăng tự động (chẳng hạn như -1, -2), dữ liệu dấu phẩy động như 3,4 và cuối cùng hiển thị 3, sẽ được làm tròn. Ngay cả khi loại int được xác định, việc nhập '3' hoặc loại dấu phẩy động sẽ buộc phải nhập int, nhưng nhập 'a' sẽ dẫn đến lỗi. Chi tiết cụ thể có thể được tìm thấy trong mã nguồn.
Câu hỏi: Tại sao ID trường đầu tiên có thể rỗng? Nếu id được viết dưới dạng id tăng tự động khi tạo bảng và số 0, null, mặc định hoặc số (không lặp lại) không xuất hiện trong id tăng tự động (chẳng hạn như -1, -2), thì hệ thống sẽ tự động điền id. Nếu bảng được tạo mà không chỉ định ID tăng tự động thì khóa chính không được để trống. Nếu bạn viết null vào thời điểm này, sẽ có thông báo lỗi.
(2) Điền theo tên trường, không cần nhập ID
- [Lưu ý]: Các trường phải tương ứng với các giá trị 1-1.
Các ghi chú khác:
- Tên trường có thể được bỏ qua và tất cả các cột sẽ được mặc định;
- Loại giá trị đầu vào và loại trường phải nhất quán hoặc tương thích;
- Số lượng trường và giá trị phải nhất quán. Không thể xảy ra tình trạng một hàng ghi 5 giá trị và một hàng khác ghi 6 giá trị;
- Nếu một trường được ghi, ngay cả khi nó có giá trị null, nó không thể để trống và phải được thay thế bằng null;
Cuối cùng, bài viết về cách MySQL triển khai chèn dữ liệu kết thúc ở đây. Nếu bạn muốn biết thêm về cách MySQL triển khai chèn dữ liệu, vui lòng tìm kiếm các bài viết về CFSDN hoặc tiếp tục duyệt các bài viết liên quan. Tôi hy vọng bạn sẽ ủng hộ blog của tôi trong tương lai! .

 Trung tâm cá nhân
Trung tâm cá nhân Điều phát hành
Điều phát hành



 4
4



Tôi là một lập trình viên xuất sắc, rất giỏi!