Các bài viết đều được đồng bộ trên website blog cá nhân: https://www.ikeguang.com/, chào mừng các bạn ghé thăm.
Gần đây tôi thấy ai đó sử dụng nền tảng quản lý trang flink sql. Tôi đã xem sơ qua và thử cài đặt và sử dụng nó. Nó thực sự dễ sử dụng hơn nhiều so với giao diện gốc của flink sql. thông qua lệnh bin/sql-client.sh Đó là hộp đen, một con sóc, vâng, đó là giao diện. . . .
Công cụ này không phải do Flink sản xuất chính thức. Nó được viết bởi một đối tác trong nước:
https://github.com/zhp8341/flink-streaming-platform-web 。
Theo mô tả của tác giả trên github, các chức năng chính của flink-streaming-patform-web là:
- [1] Nhiệm vụ hỗ trợ luồng đơn, luồng kép, luồng đơn và bảng thứ nguyên, v.v.
- [2] Hỗ trợ chế độ cục bộ, chế độ từng sợi, chế độ ĐỘC LẬP
- [3] Danh mục hỗ trợ và tổ ong.
- [4] Hỗ trợ UDF tùy chỉnh, đầu nối, v.v., hoàn toàn tương thích với các đầu nối chính thức.
- [5] Hỗ trợ phát triển trực tuyến sql, nhắc nhở cú pháp và định dạng.
- [6] Hỗ trợ cảnh báo DingTalk, cảnh báo gọi lại tùy chỉnh và khởi động tác vụ tự động.
- [7] Hỗ trợ các tác vụ gửi Jar tùy chỉnh.
- [8] Hỗ trợ nhiều phiên bản flink (người dùng cần biên dịch phiên bản flink tương ứng).
- [9] Hỗ trợ sao lưu điểm lưu trữ tự động và thủ công cũng như khôi phục các tác vụ từ điểm lưu trữ.
- [10] Hỗ trợ các tác vụ hàng loạt như tổ ong.
- [11] Quản lý ba jar như trình kết nối và udf
Bạn có nghĩ rằng nó rất mạnh mẽ không? Nhiều sinh viên đã háo hức muốn thử nó.
Cài đặt
Ở đây chúng tôi chỉ giới thiệu việc cài đặt flink trên chế độ sợi. Nếu cụm hadoop của bạn đã được cài đặt thì sẽ mất khoảng nửa giờ; nếu không thì việc cài đặt cụm hadoop sẽ gặp rất nhiều rắc rối. Các bước tổng thể như sau:
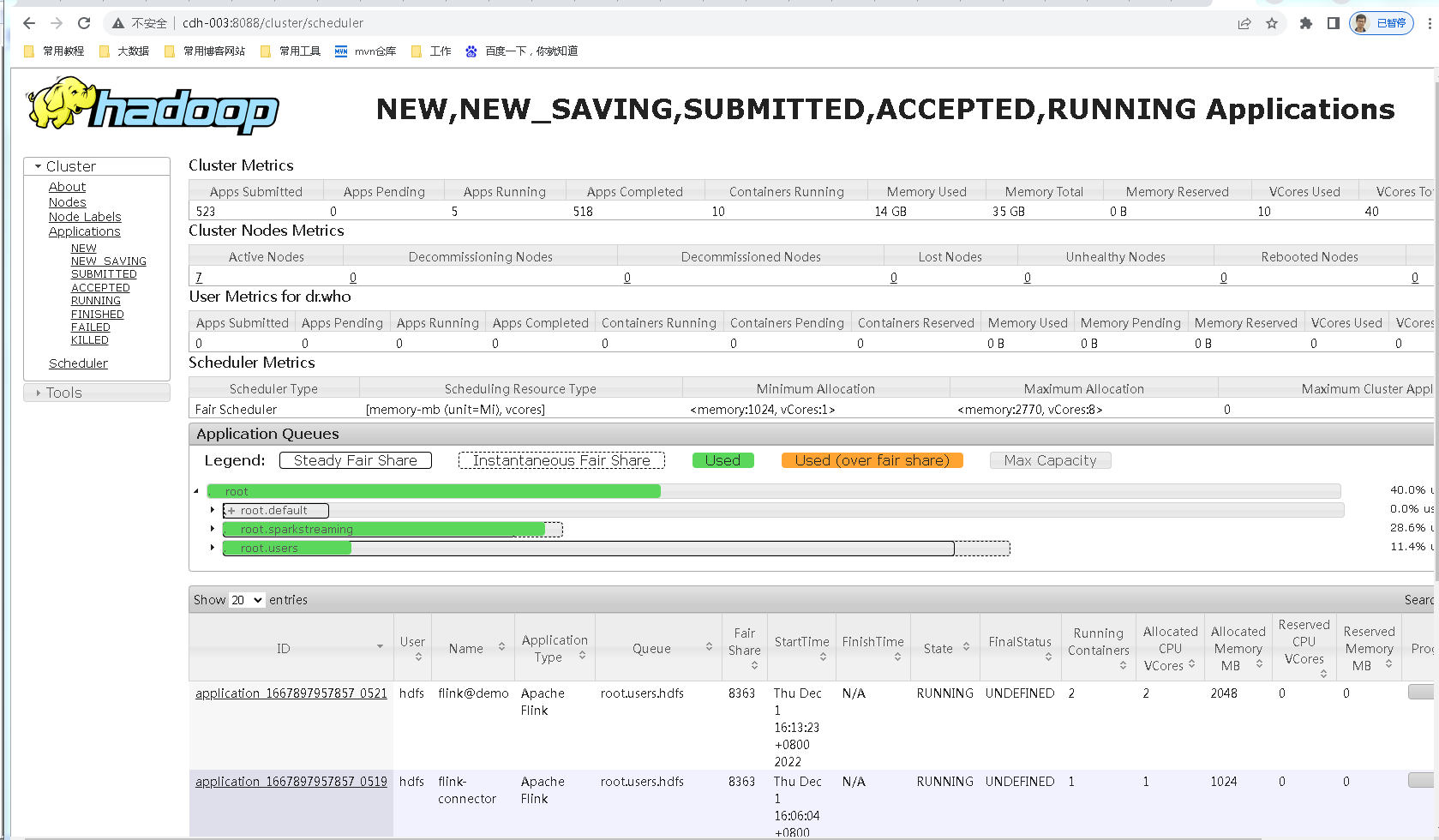
Cụm hadoop bước đầu tiên
Ở đây giả định rằng cụm hadoop của bạn hoạt động tốt, sợi có thể được sử dụng bình thường và có thể truy cập cổng 8088, như sau:
Bước thứ hai là tải xuống flink
Flink on Fiber, bạn chỉ cần tải gói cài đặt flink để sử dụng lệnh Download:
http://archive.apache.org/dist/flink/flink-1.13.5/flink-1.13.5-bin-scala_2.11.tgz
Giải nén.
tar -xvf flink-1.13.5-bin-scala_2.11.tgz
Key: Đây là câu hỏi. Làm cách nào để flink của tôi nhận ra hadoop? Tôi cần định cấu hình biến môi trường, chỉnh sửa/etc/profile và nhập:
import HADOOP_CONF_DIR=Điền vào thư mục tệp cấu hình hadoop của bạn, ví dụ: của tôi là /usr/local/hadoop2.8/etc/hadoop/conf import HADOOP_CLASSPATH=`hadoop classpath`
Được rồi, môi trường sợi như vậy đã được thiết lập.
Địa chỉ chính thức đã được cung cấp ở đầu bài viết. Tìm địa chỉ tải xuống trên github: https://github.com/zhp8341/flink-streaming-platform-web/releases/.
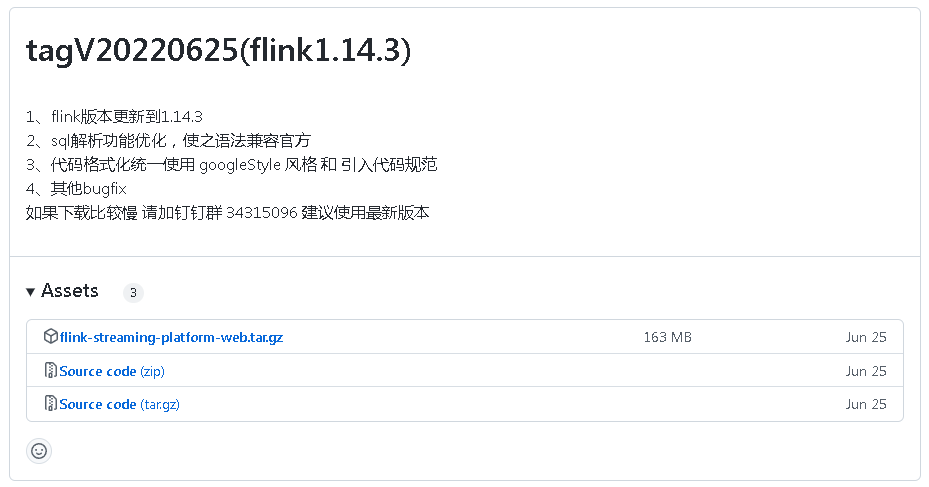
Tại sao tôi tải xuống phiên bản phù hợp với flink 1.14.3? Tôi đã cài đặt flink1.13.5 trước đó và tôi cũng đã tải xuống một loạt flinks. Sau khi thử, tôi thấy rằng phiên bản flink1.13.5 phù hợp với flink-streaming-platform-. thẻ webV20220625.
Sau khi giải nén, hãy sửa đổi tệp cấu hình: application.properties. Những người biết nó đều biết rằng đây thực sự là tệp cấu hình springboot.
#### jdbc sử dụng server.port=9084 spring.datasource.url=jdbc:mysql://192.168.1.1:3306/flink_web?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=false spring.datasource.username=bigdata spring.datasource.password=bigdata
Một cơ sở dữ liệu được cấu hình ở đây và bạn cần tự tạo nó. Tác giả của câu lệnh tạo bảng đưa ra: https://github.com/zhp8341/flink-streaming-platform-web/blob/master/docs/sql/flink_web. .sql, đặt Thực thi sql này và tạo các bảng tương ứng trong cơ sở dữ liệu flink_web cần thiết cho hoạt động của toàn bộ hệ thống.
Bắt đầu dịch vụ web.
#Lệnh bên dưới thư mục bin để bắt đầu: sh triển khai.sh bắt đầu dừng: sh triển khai.sh dừng
Sau khi dịch vụ được khởi động, hãy truy cập dịch vụ đó qua trình duyệt qua cổng 9084.

Bước thứ tư là định cấu hình nền tảng web flink
Bước này rất quan trọng. Nhấp vào Cài đặt hệ thống trên trang để vào trang cấu hình:

Ý nghĩa các thông số ở đây:
- Thư mục máy khách Flink: Đây là thư mục Flink đã cài đặt;
- Thư mục nền tảng quản lý Flink: Đây là thư mục chứa flink-streaming-platform-web đã tải xuống;
- địa chỉ http của sợi RM: sợi.resourcemanager.webapp.address, thường là cổng 8088;
Sau khi test xong cấu hình 3 thông số này là có thể sử dụng được.
Bước 5: Chạy demo
Đây là bản demo chính thức làm ví dụ, [kafka một luồng demo1 ghi vào tài liệu tham khảo mysqld](https://github.com/zhp8341/flink-streaming-platform-web/blob/master/docs/sql_demo/demo_1.md ), đây là một ví dụ về việc sử dụng kafka thông qua flink sql và ghi kết quả tổng hợp vào mysql.
- Tạo bảng trong dữ liệu flink_web
TẠO BẢNG sync_test_1 ( `day_time` varchar(64) KHÔNG NULL, `total_gmv` bigint(11) MẶC ĐỊNH LÀ NULL, KHÓA CHÍNH (`day_time`) ) ENGINE=InnoDB MẶC ĐỊNH BỘ KÝ TỰ=utf8mb4;
- Tải xuống gói jar phụ thuộc
Vì nó liên quan đến kafka và mysql, nên trình kết nối tương ứng cần phụ thuộc vào gói jar, được đánh dấu trong hình bên dưới và được đặt trong thư mục lib của Flink (/var/lib/hadoop-hdfs/flink-1.13.5/lib):
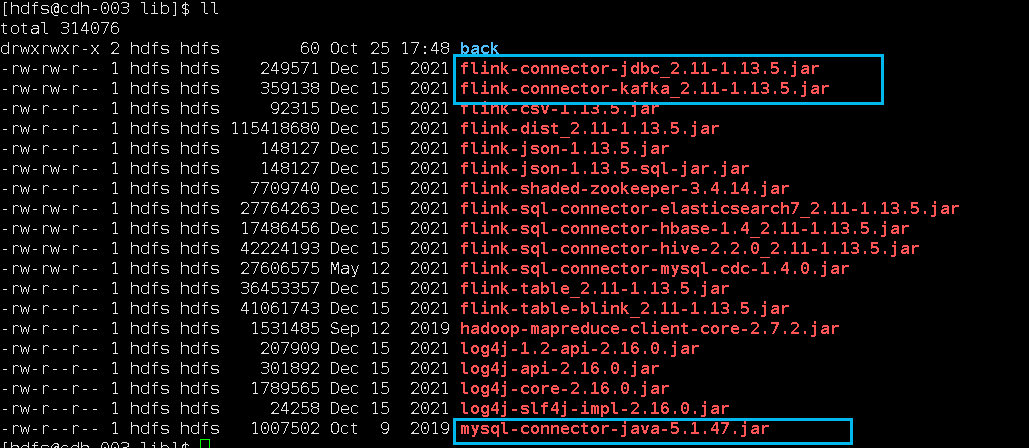
wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-jdbc_2.11/1.13.5/flink-connector-jdbc_2.11-1.13.5.jar https://repo1.maven.org/maven2/org/apache/flink/flink-connector-kafka_2.11/1.13.5/flink-connector-kafka_2.11-1.13.5.jar
Mẹo: Tải xuống gói jar phụ thuộc của Flink Có một nơi rất thuận tiện để tải xuống.
https://repo1.maven.org/maven2/org/apache/flink/ 。
Vì vậy, phụ thuộc, mọi thứ đã sẵn sàng.
Tạo một tác vụ luồng SQL mới trên trang web:
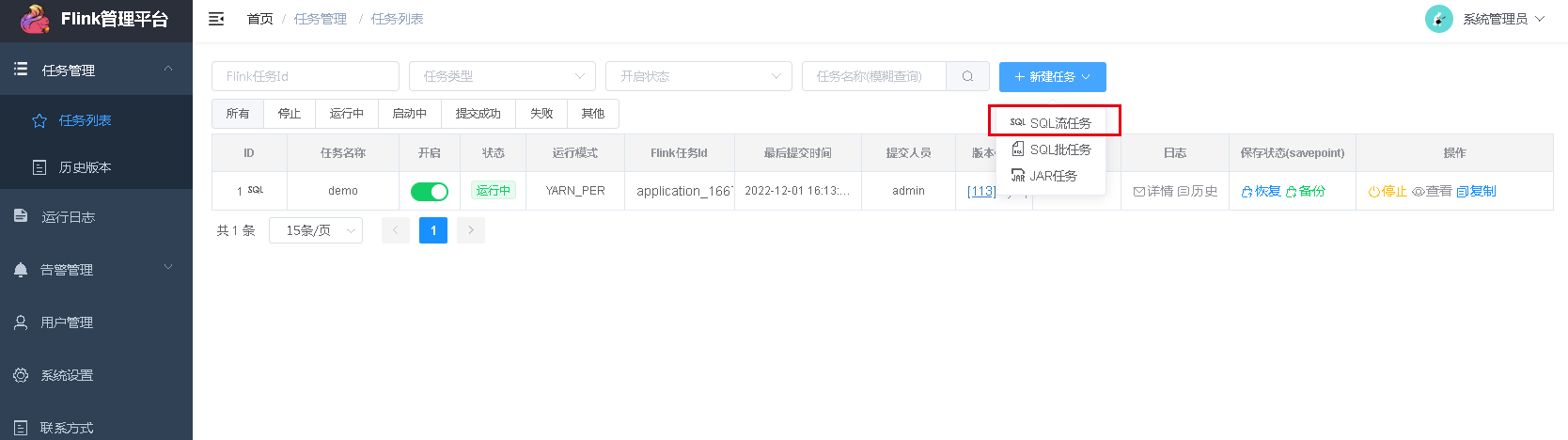
Tôi đã xây dựng một cái và điền các thuộc tính nhiệm vụ như thế này:
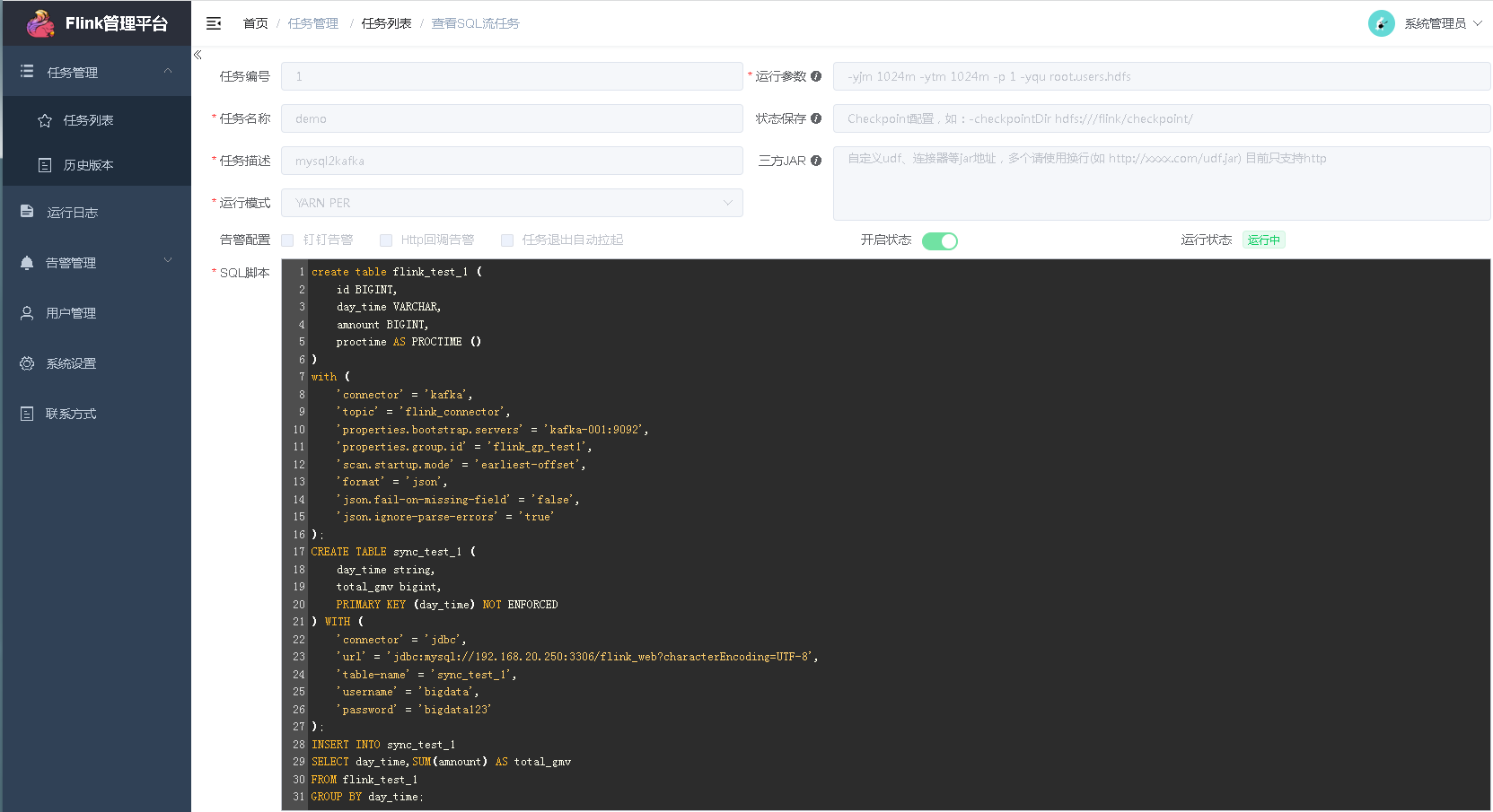
nội dung tập lệnh sql:
tạo bảng flink_test_1 (id BIGINT, day_time VARCHAR, amnount BIGINT, proctime AS PROCTIME () ) với ('connector' = 'kafka', 'topic' = 'flink_connector', 'properties.bootstrap.servers' = 'kafka-001:9092', 'properties.group.id' = 'flink_gp_test1', 'scan.startup.mode' = 'earliest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true' ); TẠO BẢNG sync_test_1 (day_time chuỗi, total_gmv bigint, KHÓA CHÍNH (day_time) KHÔNG ĐƯỢC THI HÀNH) VỚI ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://192.168.1.1:3306/flink_web?characterEncoding=UTF-8', 'table-name' = 'sync_test_1', 'username' = 'bigdata', 'password' = 'bigdata' ); CHÈN VÀO sync_test_1 CHỌN day_time,SUM(amnount) LÀ total_gmv TỪ flink_test_1 NHÓM THEO day_time;
Sau khi tạo nhiệm vụ, hãy bắt đầu nhiệm vụ.
Sau khi khởi động, bạn có thể thấy một ứng dụng trên trang cổng 8088 của sợi. Tên này là tên được điền vào nhiệm vụ mới cộng với tiền tố flink@:
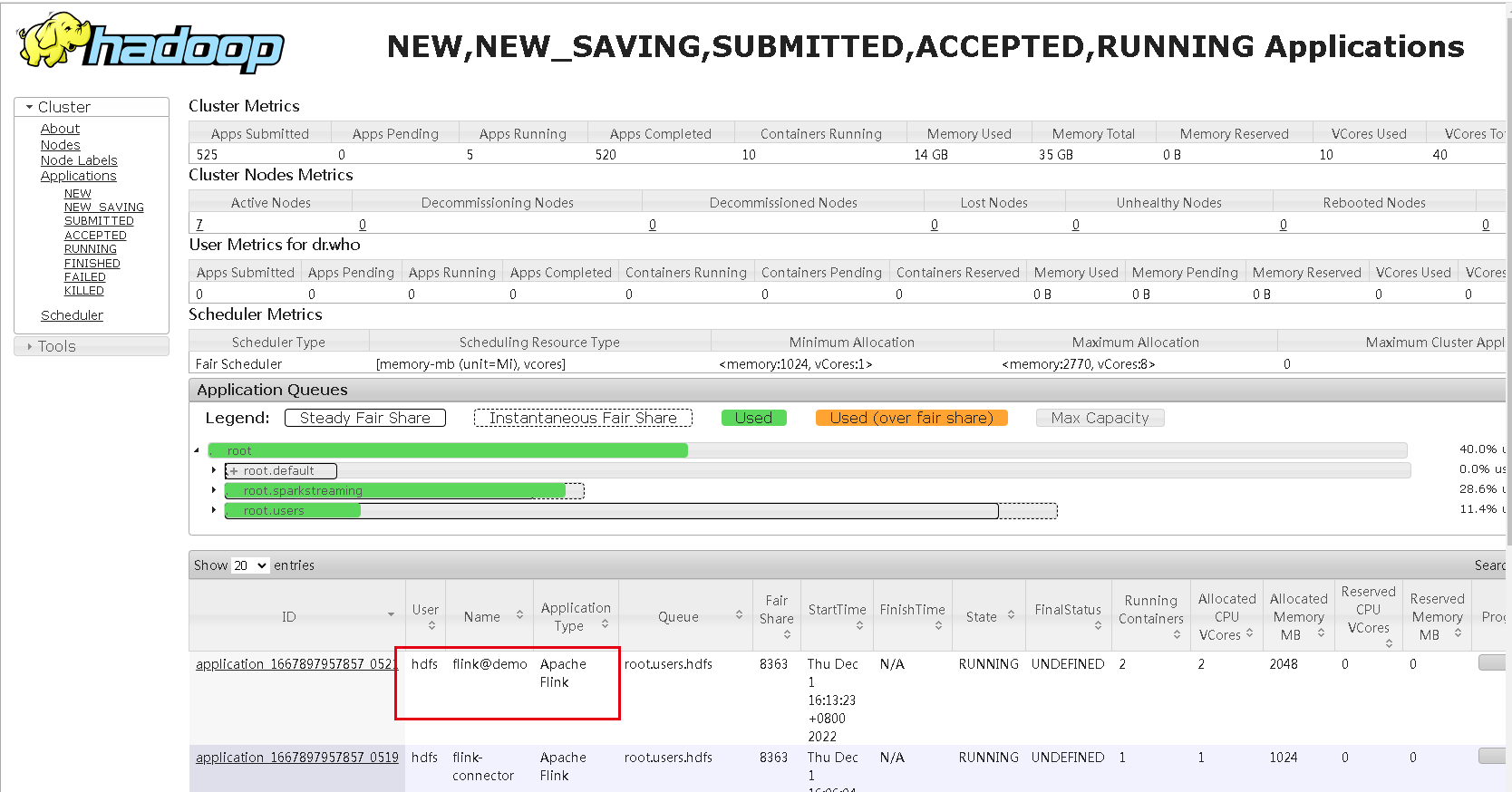
Hãy nhấp vào nhiệm vụ này và xem rằng nhiệm vụ sql được gửi qua nền tảng quản lý thực sự đang chạy. Trang này sẽ quen thuộc với những sinh viên biết Flink:

Trên thực tế, chúng ta có thể thực thi tập lệnh SQL này trong hộp đen của con sóc nhỏ được nhập bởi bin/sql-client.sh của flink. Bạn có thể thử nó.
Bảng điều khiển kafka ghi dữ liệu vào chủ đề. Nếu chủ đề không tồn tại, nó sẽ được tạo tự động:

Hãy nhìn lại mysql:
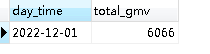
Dữ liệu đã đến rồi.
So sánh với Flink SQL
Chúng ta có thể thấy công cụ flink-streaming-platform-web chỉ cho phép chúng ta viết sql trên trang web thay vì viết sql vào hộp đen này. Hệ thống sẽ xác minh sql đã viết và gửi đến flink để thực thi. trang web flink-streaming-platform-web hoặc bảng điều khiển SQL có khung màu đen, về cơ bản chúng là một số API bảng do flink cung cấp để thực hiện các tác vụ.
Cuối cùng, bài viết này về việc cài đặt và xây dựng nền tảng quản lý FlinkSQL flink-streaming-platform-web kết thúc tại đây. Nếu bạn muốn biết thêm về việc cài đặt và xây dựng nền tảng quản lý FlinkSQL flink-streaming-platform-web, vui lòng tìm kiếm. bài viết của CFSDN Hoặc tiếp tục duyệt các bài viết liên quan, tôi hy vọng bạn sẽ ủng hộ blog của tôi trong tương lai! .

 Trung tâm cá nhân
Trung tâm cá nhân Điều phát hành
Điều phát hành



 4
4



Tôi là một lập trình viên xuất sắc, rất giỏi!